 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep residential representations: Using unsupervised learning to unlock elevation data for geo-demographic prediction
Dec 02, 2021


LiDAR (short for "Light Detection And Ranging" or "Laser Imaging, Detection, And Ranging") technology can be used to provide detailed three-dimensional elevation maps of urban and rural landscapes. To date, airborne LiDAR imaging has been predominantly confined to the environmental and archaeological domains. However, the geographically granular and open-source nature of this data also lends itself to an array of societal, organizational and business applications where geo-demographic type data is utilised. Arguably, the complexity involved in processing this multi-dimensional data has thus far restricted its broader adoption. In this paper, we propose a series of convenient task-agnostic tile elevation embeddings to address this challenge, using recent advances from unsupervised Deep Learning. We test the potential of our embeddings by predicting seven English indices of deprivation (2019) for small geographies in the Greater London area. These indices cover a range of socio-economic outcomes and serve as a proxy for a wide variety of downstream tasks to which the embeddings can be applied. We consider the suitability of this data not just on its own but also as an auxiliary source of data in combination with demographic features, thus providing a realistic use case for the embeddings. Having trialled various model/embedding configurations, we find that our best performing embeddings lead to Root-Mean-Squared-Error (RMSE) improvements of up to 21% over using standard demographic features alone. We also demonstrate how our embedding pipeline, using Deep Learning combined with K-means clustering, produces coherent tile segments which allow the latent embedding features to be interpreted.
The value of text for small business default prediction: A deep learning approach
Mar 19, 2020


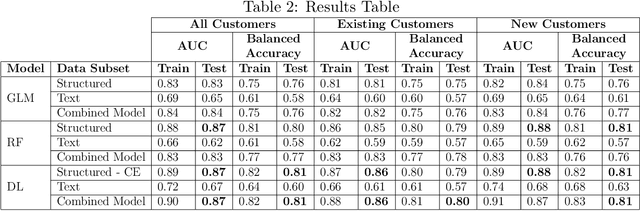
Compared to consumer lending, Micro, Small and Medium Enterprise (mSME) credit risk modelling is particularly challenging, as, often, the same sources of information are not available. To mitigate limited data availability, it is standard policy for a loan officer to provide a textual loan assessment. In turn, this statement is analysed by a credit expert alongside any available standard credit data. In our paper, we exploit recent advances from the field of Deep Learning and Natural Language Processing (NLP), including the BERT (Bidirectional Encoder Representations from Transformers) model, to extract information from 60000+ textual assessments. We consider the performance in terms of AUC (Area Under the Curve) and Balanced Accuracy and find that the text alone is surprisingly effective for predicting default. Yet, when combined with traditional data, it yields no additional predictive capability. We do find, however, that deep learning with categorical embeddings is capable of producing a modest performance improvement when compared to alternative machine learning models. We explore how the loan assessments influence predictions, explaining why despite the text being predictive, no additional performance is gained. This exploration leads us to a series of recommendations on a new strategy for the collection of future mSME loan assessments.