 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of creditworthiness models privacy-preserving training with synthetic data
Dec 31, 2022Credit scoring models are the primary instrument used by financial institutions to manage credit risk. The scarcity of research on behavioral scoring is due to the difficult data access. Financial institutions have to maintain the privacy and security of borrowers' information refrain them from collaborating in research initiatives. In this work, we present a methodology that allows us to evaluate the performance of models trained with synthetic data when they are applied to real-world data. Our results show that synthetic data quality is increasingly poor when the number of attributes increases. However, creditworthiness assessment models trained with synthetic data show a reduction of 3\% of AUC and 6\% of KS when compared with models trained with real data. These results have a significant impact since they encourage credit risk investigation from synthetic data, making it possible to maintain borrowers' privacy and to address problems that until now have been hampered by the availability of information.
On the dynamics of credit history and social interaction features, and their impact on creditworthiness assessment performance
Apr 13, 2022
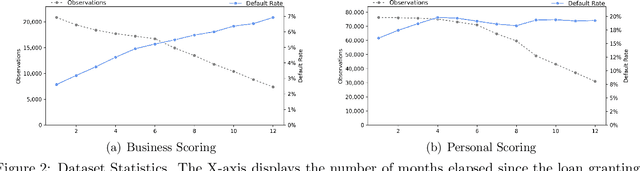
For more than a half-century, credit risk management has used credit scoring models in each of its well-defined stages to manage credit risk. Application scoring is used to decide whether to grant a credit or not, while behavioral scoring is used mainly for portfolio management and to take preventive actions in case of default signals. In both cases, network data has recently been shown to be valuable to increase the predictive power of these models, especially when the borrower's historical data is scarce or not available. This study aims to understand the creditworthiness assessment performance dynamics and how it is influenced by the credit history, repayment behavior, and social network features. To accomplish this, we introduced a machine learning classification framework to analyze 97.000 individuals and companies from the moment they obtained their first loan to 12 months afterward. Our novel and massive dataset allow us to characterize each borrower according to their credit behavior, and social and economic relationships. Our research shows that borrowers' history increases performance at a decreasing rate during the first six months and then stabilizes. The most notable effect on perfomance of social networks features occurs at loan application; in personal scoring, this effect prevails a few months, while in business scoring adds value throughout the study period. These findings are of great value to improve credit risk management and optimize the use of traditional information and alternative data sources.
On the combination of graph data for assessing thin-file borrowers' creditworthiness
Nov 26, 2021
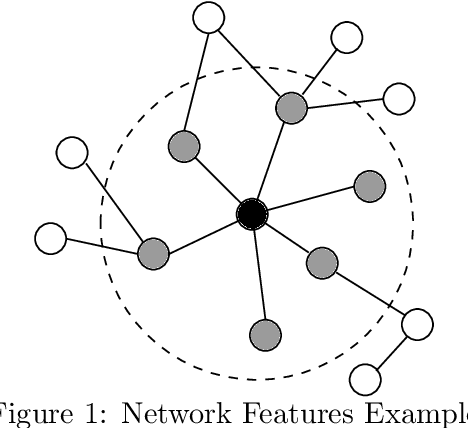

The thin-file borrowers are customers for whom a creditworthiness assessment is uncertain due to their lack of credit history; many researchers have used borrowers' relationships and interactions networks in the form of graphs as an alternative data source to address this. Incorporating network data is traditionally made by hand-crafted feature engineering, and lately, the graph neural network has emerged as an alternative, but it still does not improve over the traditional method's performance. Here we introduce a framework to improve credit scoring models by blending several Graph Representation Learning methods: feature engineering, graph embeddings, and graph neural networks. We stacked their outputs to produce a single score in this approach. We validated this framework using a unique multi-source dataset that characterizes the relationships and credit history for the entire population of a Latin American country, applying it to credit risk models, application, and behavior, targeting both individuals and companies. Our results show that the graph representation learning methods should be used as complements, and these should not be seen as self-sufficient methods as is currently done. In terms of AUC and KS, we enhance the statistical performance, outperforming traditional methods. In Corporate lending, where the gain is much higher, it confirms that evaluating an unbanked company cannot solely consider its features. The business ecosystem where these firms interact with their owners, suppliers, customers, and other companies provides novel knowledge that enables financial institutions to enhance their creditworthiness assessment. Our results let us know when and which group to use graph data and what effects on performance to expect. They also show the enormous value of graph data on the unbanked credit scoring problem, principally to help companies' banking.
Simion Zoo: A Workbench for Distributed Experimentation with Reinforcement Learning for Continuous Control Tasks
Apr 16, 2019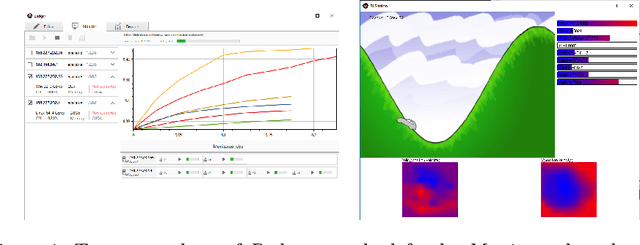
We present Simion Zoo, a Reinforcement Learning (RL) workbench that provides a complete set of tools to design, run, and analyze the results,both statistically and visually, of RL control applications. The main features that set apart Simion Zoo from similar software packages are its easy-to-use GUI, its support for distributed execution including deployment over graphics processing units (GPUs) , and the possibility to explore concurrently the RL metaparameter space, which is key to successful RL experimentation.
Using Scratch to Teach Undergraduate Students' Skills on Artificial Intelligence
Mar 30, 2019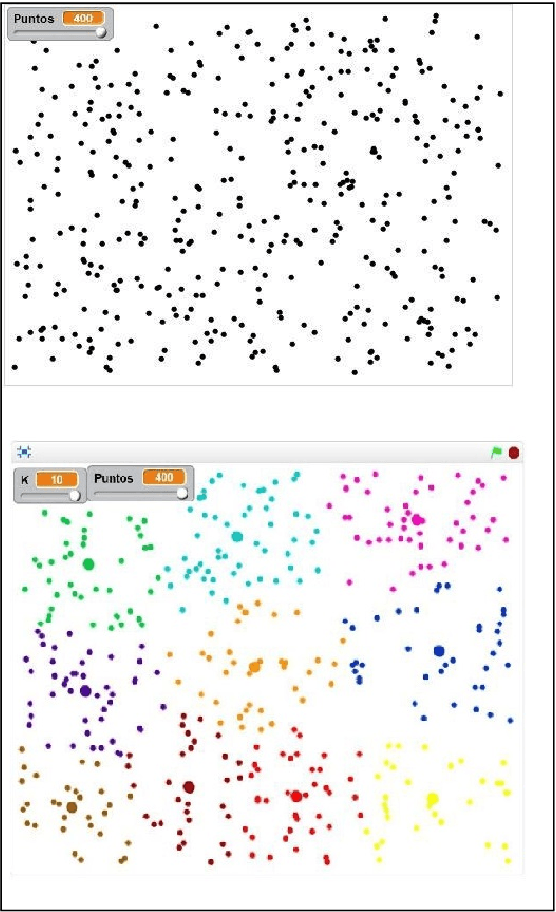
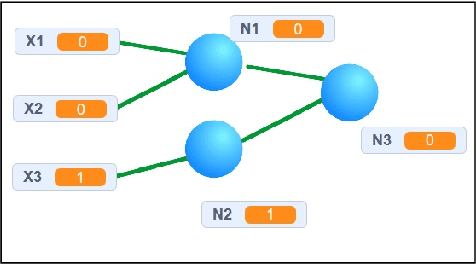
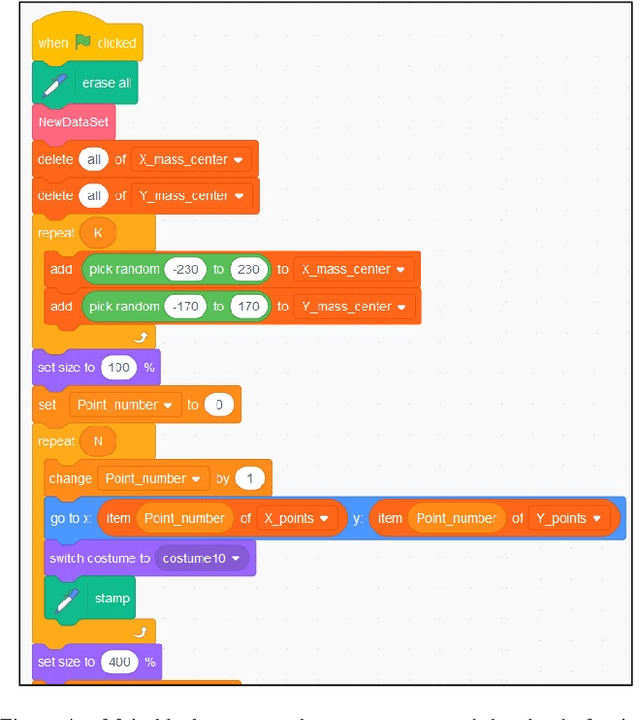
This paper presents a educational workshop in Scratch that is proposed for the active participation of undergraduate students in contexts of Artificial Intelligence. The main objective of the activity is to demystify the complexity of Artificial Intelligence and its algorithms. For this purpose, students must realize simple exercises of clustering and two neural networks, in Scratch. The detailed methodology to get that is presented in the article.
Further results on dissimilarity spaces for hyperspectral images RF-CBIR
Jul 04, 2013


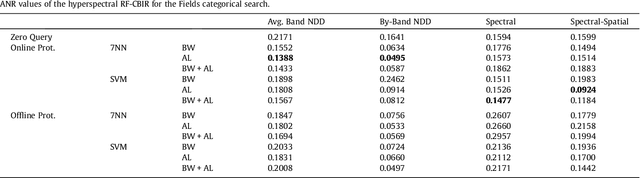
Content-Based Image Retrieval (CBIR) systems are powerful search tools in image databases that have been little applied to hyperspectral images. Relevance feedback (RF) is an iterative process that uses machine learning techniques and user's feedback to improve the CBIR systems performance. We pursued to expand previous research in hyperspectral CBIR systems built on dissimilarity functions defined either on spectral and spatial features extracted by spectral unmixing techniques, or on dictionaries extracted by dictionary-based compressors. These dissimilarity functions were not suitable for direct application in common machine learning techniques. We propose to use a RF general approach based on dissimilarity spaces which is more appropriate for the application of machine learning algorithms to the hyperspectral RF-CBIR. We validate the proposed RF method for hyperspectral CBIR systems over a real hyperspectral dataset.
* In Pattern Recognition Letters (2013)