 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the combination of graph data for assessing thin-file borrowers' creditworthiness
Paper and Code
Nov 26, 2021
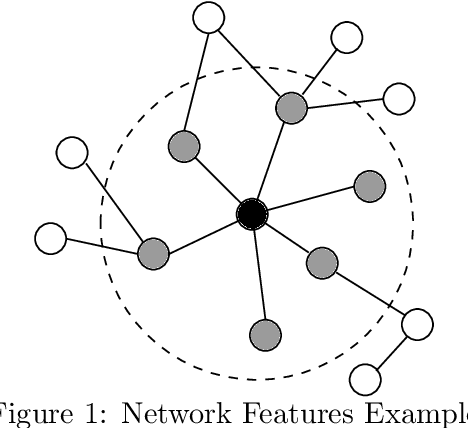

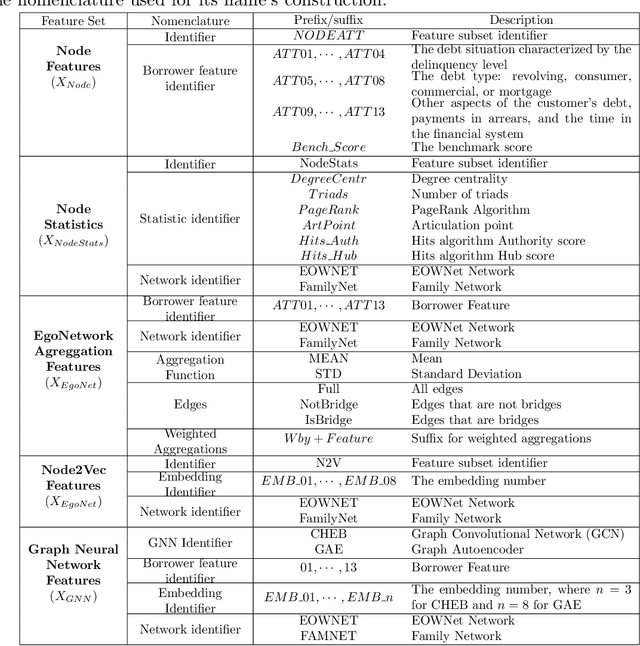
The thin-file borrowers are customers for whom a creditworthiness assessment is uncertain due to their lack of credit history; many researchers have used borrowers' relationships and interactions networks in the form of graphs as an alternative data source to address this. Incorporating network data is traditionally made by hand-crafted feature engineering, and lately, the graph neural network has emerged as an alternative, but it still does not improve over the traditional method's performance. Here we introduce a framework to improve credit scoring models by blending several Graph Representation Learning methods: feature engineering, graph embeddings, and graph neural networks. We stacked their outputs to produce a single score in this approach. We validated this framework using a unique multi-source dataset that characterizes the relationships and credit history for the entire population of a Latin American country, applying it to credit risk models, application, and behavior, targeting both individuals and companies. Our results show that the graph representation learning methods should be used as complements, and these should not be seen as self-sufficient methods as is currently done. In terms of AUC and KS, we enhance the statistical performance, outperforming traditional methods. In Corporate lending, where the gain is much higher, it confirms that evaluating an unbanked company cannot solely consider its features. The business ecosystem where these firms interact with their owners, suppliers, customers, and other companies provides novel knowledge that enables financial institutions to enhance their creditworthiness assessment. Our results let us know when and which group to use graph data and what effects on performance to expect. They also show the enormous value of graph data on the unbanked credit scoring problem, principally to help companies' banking.