 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCRBench: Exploring Long-form Causal Reasoning Capabilities of Large Video Language Models
May 13, 2025
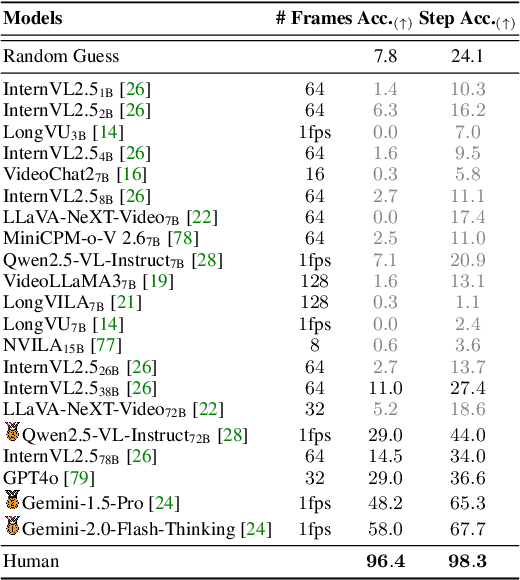
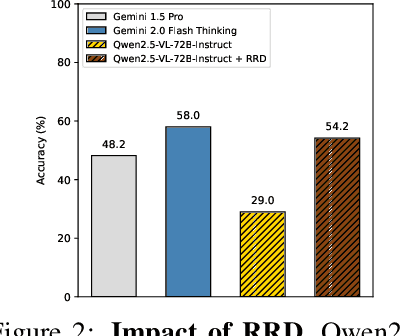
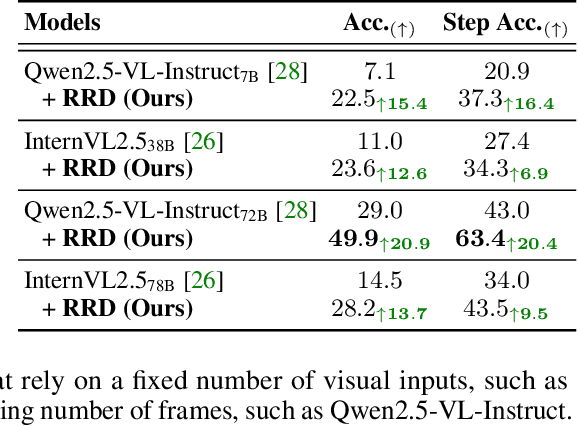
Despite recent advances in video understanding, the capabilities of Large Video Language Models (LVLMs) to perform video-based causal reasoning remains underexplored, largely due to the absence of relevant and dedicated benchmarks for evaluating causal reasoning in visually grounded and goal-driven settings. To fill this gap, we introduce a novel benchmark named Video-based long-form Causal Reasoning (VCRBench). We create VCRBench using procedural videos of simple everyday activities, where the steps are deliberately shuffled with each clip capturing a key causal event, to test whether LVLMs can identify, reason about, and correctly sequence the events needed to accomplish a specific goal. Moreover, the benchmark is carefully designed to prevent LVLMs from exploiting linguistic shortcuts, as seen in multiple-choice or binary QA formats, while also avoiding the challenges associated with evaluating open-ended QA. Our evaluation of state-of-the-art LVLMs on VCRBench suggests that these models struggle with video-based long-form causal reasoning, primarily due to their difficulty in modeling long-range causal dependencies directly from visual observations. As a simple step toward enabling such capabilities, we propose Recognition-Reasoning Decomposition (RRD), a modular approach that breaks video-based causal reasoning into two sub-tasks of video recognition and causal reasoning. Our experiments on VCRBench show that RRD significantly boosts accuracy on VCRBench, with gains of up to 25.2%. Finally, our thorough analysis reveals interesting insights, for instance, that LVLMs primarily rely on language knowledge for complex video-based long-form causal reasoning tasks.
Self-alignment of Large Video Language Models with Refined Regularized Preference Optimization
Apr 16, 2025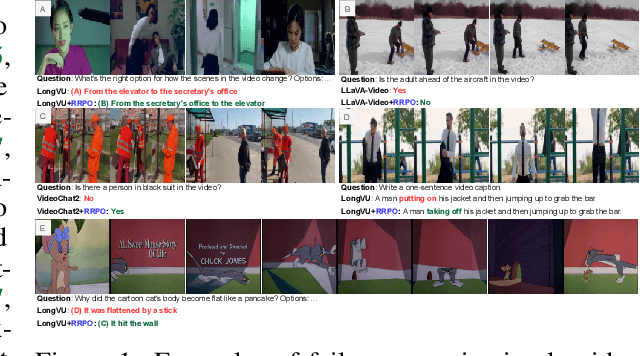
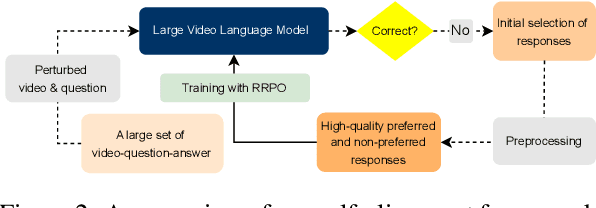


Despite recent advances in Large Video Language Models (LVLMs), they still struggle with fine-grained temporal understanding, hallucinate, and often make simple mistakes on even simple video question-answering tasks, all of which pose significant challenges to their safe and reliable deployment in real-world applications. To address these limitations, we propose a self-alignment framework that enables LVLMs to learn from their own errors. Our proposed framework first obtains a training set of preferred and non-preferred response pairs, where non-preferred responses are generated by incorporating common error patterns that often occur due to inadequate spatio-temporal understanding, spurious correlations between co-occurring concepts, and over-reliance on linguistic cues while neglecting the vision modality, among others. To facilitate self-alignment of LVLMs with the constructed preferred and non-preferred response pairs, we introduce Refined Regularized Preference Optimization (RRPO), a novel preference optimization method that utilizes sub-sequence-level refined rewards and token-wise KL regularization to address the limitations of Direct Preference Optimization (DPO). We demonstrate that RRPO achieves more precise alignment and more stable training compared to DPO. Our experiments and analysis validate the effectiveness of our approach across diverse video tasks, including video hallucination, short- and long-video understanding, and fine-grained temporal reasoning.
Mitigating Object Hallucination via Data Augmented Contrastive Tuning
May 28, 2024Despite their remarkable progress, Multimodal Large Language Models (MLLMs) tend to hallucinate factually inaccurate information. In this work, we address object hallucinations in MLLMs, where information is offered about an object that is not present in the model input. We introduce a contrastive tuning method that can be applied to a pretrained off-the-shelf MLLM for mitigating hallucinations while preserving its general vision-language capabilities. For a given factual token, we create a hallucinated token through generative data augmentation by selectively altering the ground-truth information. The proposed contrastive tuning is applied at the token level to improve the relative likelihood of the factual token compared to the hallucinated one. Our thorough evaluation confirms the effectiveness of contrastive tuning in mitigating hallucination. Moreover, the proposed contrastive tuning is simple, fast, and requires minimal training with no additional overhead at inference.
Region-Disentangled Diffusion Model for High-Fidelity PPG-to-ECG Translation
Aug 25, 2023



The high prevalence of cardiovascular diseases (CVDs) calls for accessible and cost-effective continuous cardiac monitoring tools. Despite Electrocardiography (ECG) being the gold standard, continuous monitoring remains a challenge, leading to the exploration of Photoplethysmography (PPG), a promising but more basic alternative available in consumer wearables. This notion has recently spurred interest in translating PPG to ECG signals. In this work, we introduce Region-Disentangled Diffusion Model (RDDM), a novel diffusion model designed to capture the complex temporal dynamics of ECG. Traditional Diffusion models like Denoising Diffusion Probabilistic Models (DDPM) face challenges in capturing such nuances due to the indiscriminate noise addition process across the entire signal. Our proposed RDDM overcomes such limitations by incorporating a novel forward process that selectively adds noise to specific regions of interest (ROI) such as QRS complex in ECG signals, and a reverse process that disentangles the denoising of ROI and non-ROI regions. Quantitative experiments demonstrate that RDDM can generate high-fidelity ECG from PPG in as few as 10 diffusion steps, making it highly effective and computationally efficient. Additionally, to rigorously validate the usefulness of the generated ECG signals, we introduce CardioBench, a comprehensive evaluation benchmark for a variety of cardiac-related tasks including heart rate and blood pressure estimation, stress classification, and the detection of atrial fibrillation and diabetes. Our thorough experiments show that RDDM achieves state-of-the-art performance on CardioBench. To the best of our knowledge, RDDM is the first diffusion model for cross-modal signal-to-signal translation in the bio-signal domain.
Uncovering the Hidden Dynamics of Video Self-supervised Learning under Distribution Shifts
Jun 03, 2023Video self-supervised learning (VSSL) has made significant progress in recent years. However, the exact behavior and dynamics of these models under different forms of distribution shift are not yet known. In this paper, we comprehensively study the behavior of six popular self-supervised methods (v-SimCLR, v-MOCO, v-BYOL, v-SimSiam, v-DINO, v-MAE) in response to various forms of natural distribution shift, i.e., (i) context shift, (ii) viewpoint shift, (iii) actor shift, (iv) source shift, (v) generalizability to unknown classes (zero-shot), and (vi) open-set recognition. To perform this extensive study, we carefully craft a test bed consisting of $17$ in-distribution and out-of-distribution benchmark pairs using available public datasets and a series of evaluation protocols to stress-test the different methods under the intended shifts. Our study uncovers a series of intriguing findings and interesting behaviors of VSSL methods. For instance, we observe that while video models generally struggle with context shifts, v-MAE and supervised learning exhibit more robustness. Moreover, our study shows that v-MAE is a strong temporal learner, whereas contrastive methods, v-SimCLR and v-MOCO, exhibit strong performances against viewpoint shifts. When studying the notion of open-set recognition, we notice a trade-off between closed-set and open-set recognition performance, particularly if the pretrained VSSL encoders are used without finetuning. We hope that our work will contribute to the development of robust video representation learning frameworks for various real-world scenarios.
XKD: Cross-modal Knowledge Distillation with Domain Alignment for Video Representation Learning
Dec 12, 2022We present XKD, a novel self-supervised framework to learn meaningful representations from unlabelled video clips. XKD is trained with two pseudo tasks. First, masked data reconstruction is performed to learn modality-specific representations. Next, self-supervised cross-modal knowledge distillation is performed between the two modalities through teacher-student setups to learn complementary information. To identify the most effective information to transfer and also to tackle the domain gap between audio and visual modalities which could hinder knowledge transfer, we introduce a domain alignment strategy for effective cross-modal distillation. Lastly, to develop a general-purpose solution capable of handling both audio and visual streams, a modality-agnostic variant of our proposed framework is introduced, which uses the same backbone for both audio and visual modalities. Our proposed cross-modal knowledge distillation improves linear evaluation top-1 accuracy of video action classification by 8.4% on UCF101, 8.1% on HMDB51, 13.8% on Kinetics-Sound, and 14.2% on Kinetics400. Additionally, our modality-agnostic variant shows promising results in developing a general-purpose network capable of handling different data streams. The code is released on the project website.
AVCAffe: A Large Scale Audio-Visual Dataset of Cognitive Load and Affect for Remote Work
May 13, 2022



We introduce AVCAffe, the first Audio-Visual dataset consisting of Cognitive load and Affect attributes. We record AVCAffe by simulating remote work scenarios over a video-conferencing platform, where subjects collaborate to complete a number of cognitively engaging tasks. AVCAffe is the largest originally collected (not collected from the Internet) affective dataset in English language. We recruit 106 participants from 18 different countries of origin, spanning an age range of 18 to 57 years old, with a balanced male-female ratio. AVCAffe comprises a total of 108 hours of video, equivalent to more than 58,000 clips along with task-based self-reported ground truth labels for arousal, valence, and cognitive load attributes such as mental demand, temporal demand, effort, and a few others. We believe AVCAffe would be a challenging benchmark for the deep learning research community given the inherent difficulty of classifying affect and cognitive load in particular. Moreover, our dataset fills an existing timely gap by facilitating the creation of learning systems for better self-management of remote work meetings, and further study of hypotheses regarding the impact of remote work on cognitive load and affective states.
Self-Supervised Audio-Visual Representation Learning with Relaxed Cross-Modal Temporal Synchronicity
Nov 14, 2021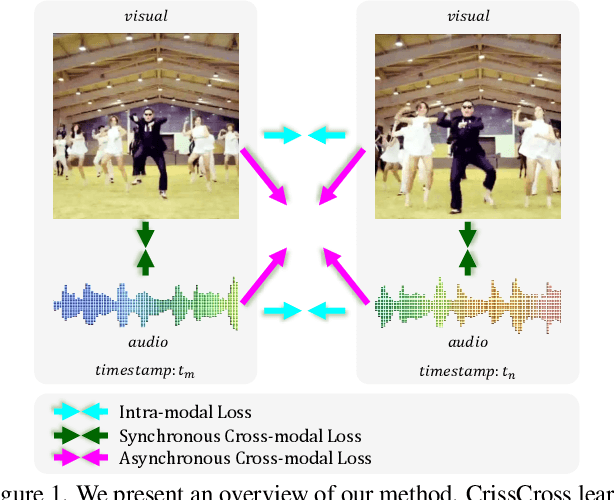
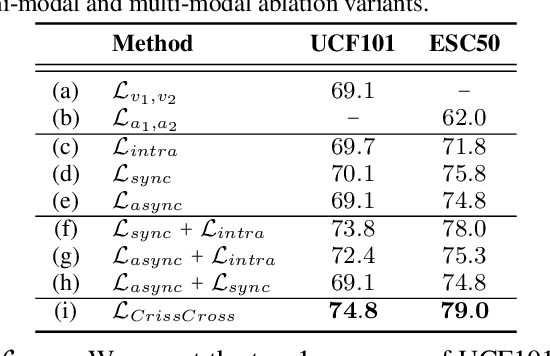
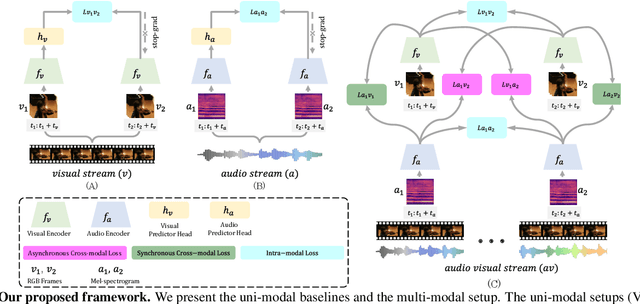

We present CrissCross, a self-supervised framework for learning audio-visual representations. A novel notion is introduced in our framework whereby in addition to learning the intra-modal and standard 'synchronous' cross-modal relations, CrissCross also learns 'asynchronous' cross-modal relationships. We show that by relaxing the temporal synchronicity between the audio and visual modalities, the network learns strong time-invariant representations. Our experiments show that strong augmentations for both audio and visual modalities with relaxation of cross-modal temporal synchronicity optimize performance. To pretrain our proposed framework, we use 3 different datasets with varying sizes, Kinetics-Sound, Kinetics-400, and AudioSet. The learned representations are evaluated on a number of downstream tasks namely action recognition, sound classification, and retrieval. CrissCross shows state-of-the-art performances on action recognition (UCF101 and HMDB51) and sound classification (ESC50). The codes and pretrained models will be made publicly available.
CardioGAN: Attentive Generative Adversarial Network with Dual Discriminators for Synthesis of ECG from PPG
Sep 30, 2020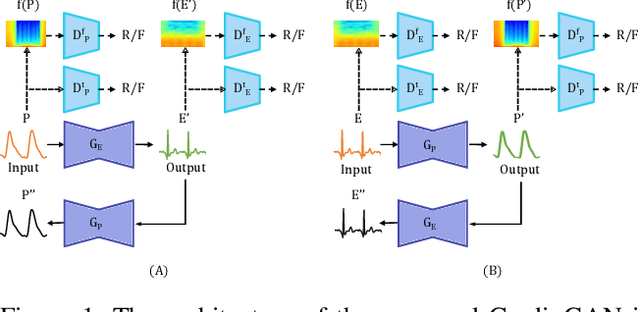


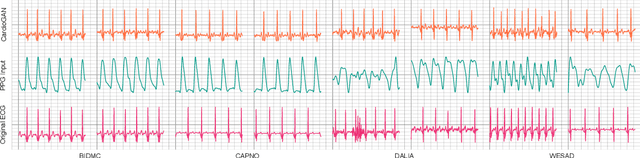
Electrocardiogram (ECG) is the electrical measurement of cardiac activity, whereas Photoplethysmogram (PPG) is the optical measurement of volumetric changes in blood circulation. While both signals are used for heart rate monitoring, from a medical perspective, ECG is more useful as it carries additional cardiac information. Despite many attempts toward incorporating ECG sensing in smartwatches or similar wearable devices for continuous and reliable cardiac monitoring, PPG sensors are the main feasible sensing solution available. In order to tackle this problem, we propose CardioGAN, an adversarial model which takes PPG as input and generates ECG as output. The proposed network utilizes an attention-based generator to learn local salient features, as well as dual discriminators to preserve the integrity of generated data in both time and frequency domains. Our experiments show that the ECG generated by CardioGAN provides more reliable heart rate measurements compared to the original input PPG, reducing the error from 9.74 beats per minute (measured from the PPG) to 2.89 (measured from the generated ECG).
Self-supervised ECG Representation Learning for Emotion Recognition
Feb 04, 2020

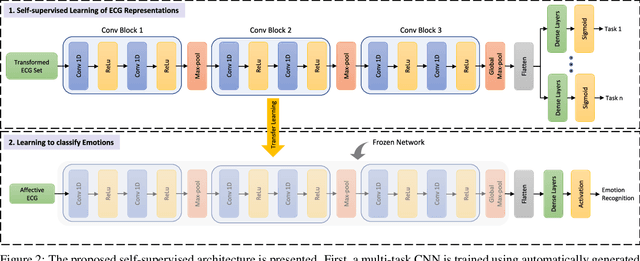

We present a self-supervised deep multi-task learning framework for electrocardiogram (ECG) -based emotion recognition. The proposed framework consists of two stages of learning a) learning ECG representations and b) learning to classify emotions. ECG representations are learned by a signal transformation recognition network. The network learns high-level abstract representations from unlabeled ECG data. Six different signal transformations are applied to the ECG signals, and transformation recognition is performed as pretext tasks. Training the model on pretext tasks helps our network learn spatiotemporal representations that generalize well across different datasets and different emotion categories. We transfer the weights of the self-supervised network to an emotion recognition network, where the convolutional layers are kept frozen and the dense layers are trained with labelled ECG data. We show that our proposed method considerably improves the performance compared to a network trained using fully-supervised learning. New state-of-the-art results are set in classification of arousal, valence, affective states, and stress for the four utilized datasets. Extensive experiments are performed, providing interesting insights into the impact of using a multi-task self-supervised structure instead of a single-task model, as well as the optimum level of difficulty required for the pretext self-supervised tasks.