 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Audio-Visual Representation Learning with Relaxed Cross-Modal Temporal Synchronicity
Paper and Code
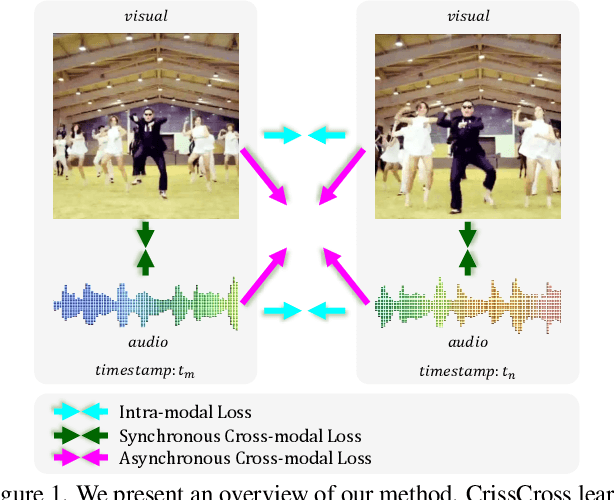
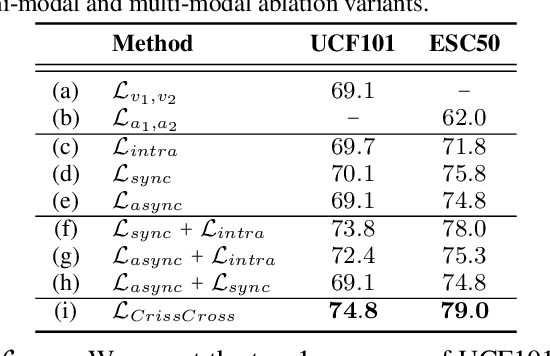
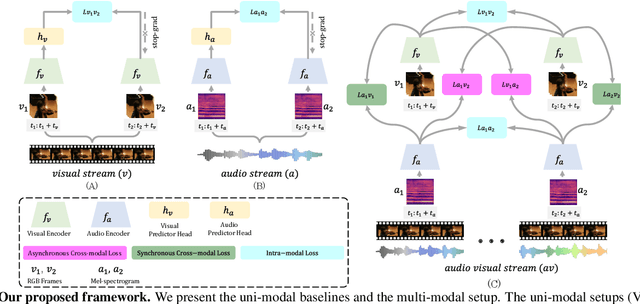

We present CrissCross, a self-supervised framework for learning audio-visual representations. A novel notion is introduced in our framework whereby in addition to learning the intra-modal and standard 'synchronous' cross-modal relations, CrissCross also learns 'asynchronous' cross-modal relationships. We show that by relaxing the temporal synchronicity between the audio and visual modalities, the network learns strong time-invariant representations. Our experiments show that strong augmentations for both audio and visual modalities with relaxation of cross-modal temporal synchronicity optimize performance. To pretrain our proposed framework, we use 3 different datasets with varying sizes, Kinetics-Sound, Kinetics-400, and AudioSet. The learned representations are evaluated on a number of downstream tasks namely action recognition, sound classification, and retrieval. CrissCross shows state-of-the-art performances on action recognition (UCF101 and HMDB51) and sound classification (ESC50). The codes and pretrained models will be made publicly available.