 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoLoco: Leveraging 3D Geometric Priors from Visual Foundation Model for Robust RGB-Only Humanoid Locomotion
Mar 08, 2026The prevailing paradigm of perceptive humanoid locomotion relies heavily on active depth sensors. However, this depth-centric approach fundamentally discards the rich semantic and dense appearance cues of the visual world, severing low-level control from the high-level reasoning essential for general embodied intelligence. While monocular RGB offers a ubiquitous, information-dense alternative, end-to-end reinforcement learning from raw 2D pixels suffers from extreme sample inefficiency and catastrophic sim-to-real collapse due to the inherent loss of geometric scale. To break this deadlock, we propose GeoLoco, a purely RGB-driven locomotion framework that conceptualizes monocular images as high-dimensional 3D latent representations by harnessing the powerful geometric priors of a frozen, scale-aware Visual Foundation Model (VFM). Rather than naive feature concatenation, we design a proprioceptive-query multi-head cross-attention mechanism that dynamically attends to task-critical topological features conditioned on the robot's real-time gait phase. Crucially, to prevent the policy from overfitting to superficial textures, we introduce a dual-head auxiliary learning scheme. This explicit regularization forces the high-dimensional latent space to strictly align with the physical terrain geometry, ensuring robust zero-shot sim-to-real transfer. Trained exclusively in simulation, GeoLoco achieves robust zero-shot transfer to the Unitree G1 humanoid and successfully negotiates challenging terrains.
Initializing Models with Larger Ones
Nov 30, 2023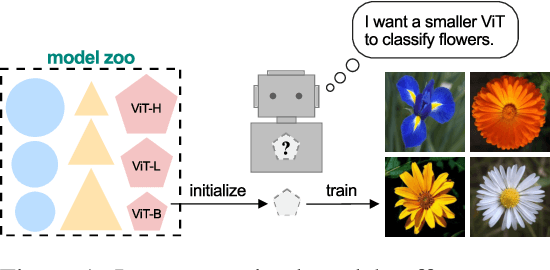



Weight initialization plays an important role in neural network training. Widely used initialization methods are proposed and evaluated for networks that are trained from scratch. However, the growing number of pretrained models now offers new opportunities for tackling this classical problem of weight initialization. In this work, we introduce weight selection, a method for initializing smaller models by selecting a subset of weights from a pretrained larger model. This enables the transfer of knowledge from pretrained weights to smaller models. Our experiments demonstrate that weight selection can significantly enhance the performance of small models and reduce their training time. Notably, it can also be used together with knowledge distillation. Weight selection offers a new approach to leverage the power of pretrained models in resource-constrained settings, and we hope it can be a useful tool for training small models in the large-model era. Code is available at https://github.com/OscarXZQ/weight-selection.
Joint Echo Cancellation and Noise Suppression based on Cascaded Magnitude and Complex Mask Estimation
Jul 20, 2021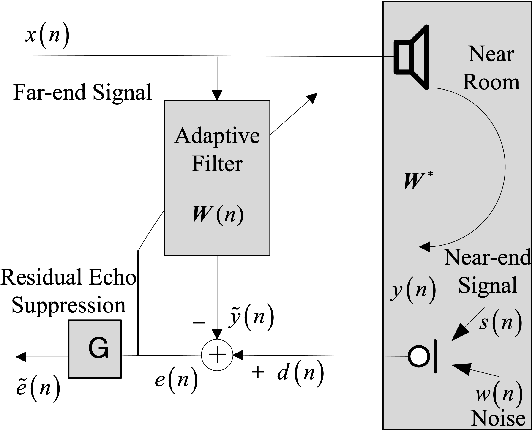
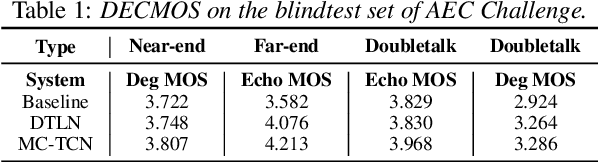
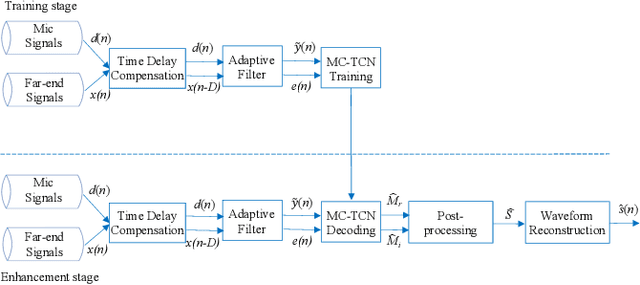
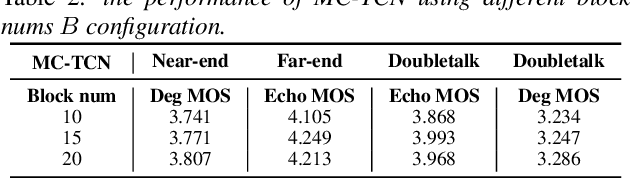
Acoustic echo and background noise can seriously degrade the intelligibility of speech. In practice, echo and noise suppression are usually treated as two separated tasks and can be removed with various digital signal processing (DSP) and deep learning techniques. In this paper, we propose a new cascaded model, magnitude and complex temporal convolutional neural network (MC-TCN), to jointly perform acoustic echo cancellation and noise suppression with the help of adaptive filters. The MC-TCN cascades two separation cores, which are used to extract robust magnitude spectra feature and to enhance magnitude and phase simultaneously. Experimental results reveal that the proposed method can achieve superior performance by removing both echo and noise in real-time. In terms of DECMOS, the subjective test shows our method achieves a mean score of 4.41 and outperforms the INTERSPEECH2021 AEC-Challenge baseline by 0.54.
Artificial Intelligence Enhanced Rapid and Efficient Diagnosis of Mycoplasma Pneumoniae Pneumonia in Children Patients
Feb 20, 2021
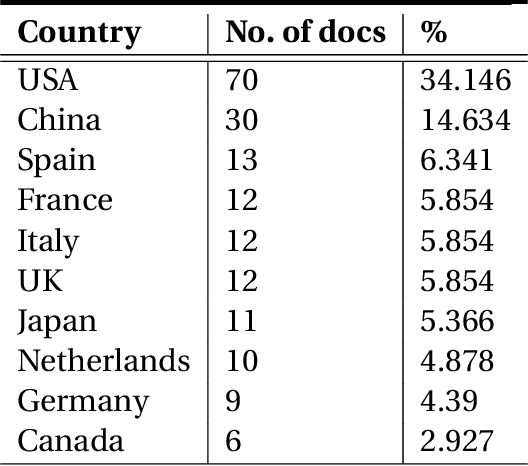
Artificial intelligence methods have been increasingly turning into a potentially powerful tool in the diagnosis and management of diseases. In this study, we utilized logistic regression (LR), decision tree (DT), gradient boosted decision tree (GBDT), support vector machine (SVM), and multilayer perceptron (MLP) as machine learning models to rapidly diagnose the mycoplasma pneumoniae pneumonia (MPP) in children patients. The classification task was carried out after applying the preprocessing procedure to the MPP dataset. The most efficient results are obtained by GBDT. It provides the best performance with an accuracy of 93.7%. In contrast to standard raw feature weighting, the feature importance takes the underlying correlation structure of the features into account. The most crucial feature of GBDT is the "pulmonary infiltrates range" with a score of 0.5925, followed by "cough" (0.0953) and "pleural effusion" (0.0492). We publicly share our full implementation with the dataset and trained models at https://github.com/zhenguonie/2021_AI4MPP.
PPDM: Parallel Point Detection and Matching for Real-time Human-Object Interaction Detection
Dec 30, 2019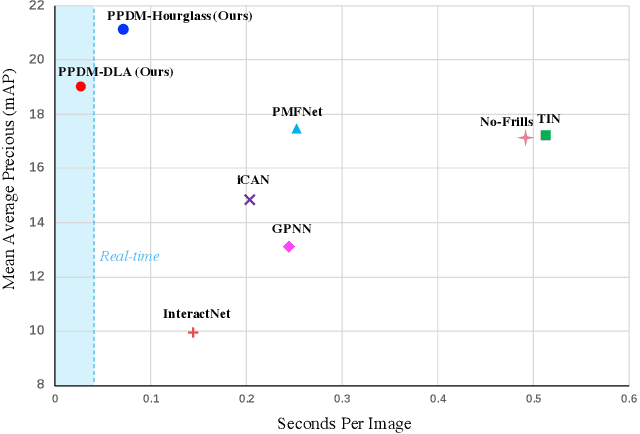
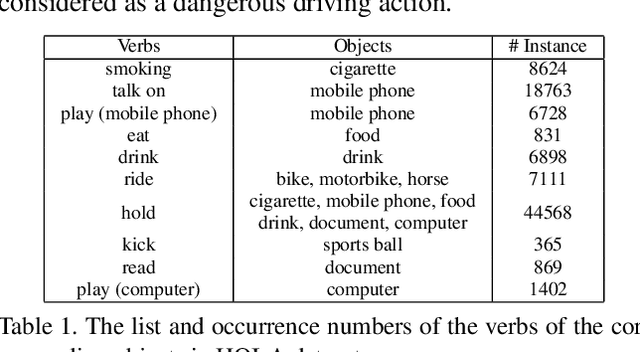
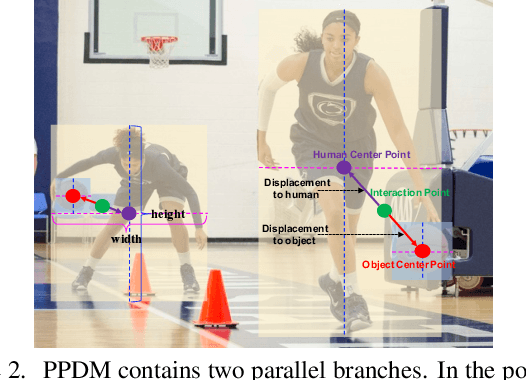
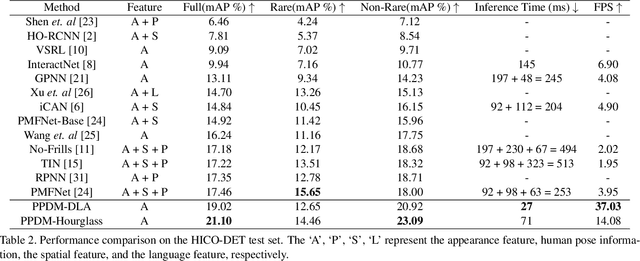
We propose a single-stage Human-Object Interaction (HOI) detection method that has outperformed all existing methods on HICO-DET dataset at 37 fps on a single Titan XP GPU. It is the first real-time HOI detection method. Conventional HOI detection methods are composed of two stages, i.e., human-object proposals generation, and proposals classification. Their effectiveness and efficiency are limited by the sequential and separate architecture. In this paper, we propose a Parallel Point Detection and Matching (PPDM) HOI detection framework. In PPDM, an HOI is defined as a point triplet < human point, interaction point, object point>. Human and object points are the center of the detection boxes, and the interaction point is the midpoint of the human and object points. PPDM contains two parallel branches, namely point detection branch and point matching branch. The point detection branch predicts three points. Simultaneously, the point matching branch predicts two displacements from the interaction point to its corresponding human and object points. The human point and the object point originated from the same interaction point are considered as matched pairs. In our novel parallel architecture, the interaction points implicitly provide context and regularization for human and object detection. The isolated detection boxes are unlikely to form meaning HOI triplets are suppressed, which increases the precision of HOI detection. Moreover, the matching between human and object detection boxes is only applied around limited numbers of filtered candidate interaction points, which saves much computational cost. Additionally, we build a new applicationoriented database named HOI-A, which severs as a good supplement to the existing datasets. The source code and the dataset will be made publicly available to facilitate the development of HOI detection.
A Real-Time Cross-modality Correlation Filtering Method for Referring Expression Comprehension
Sep 24, 2019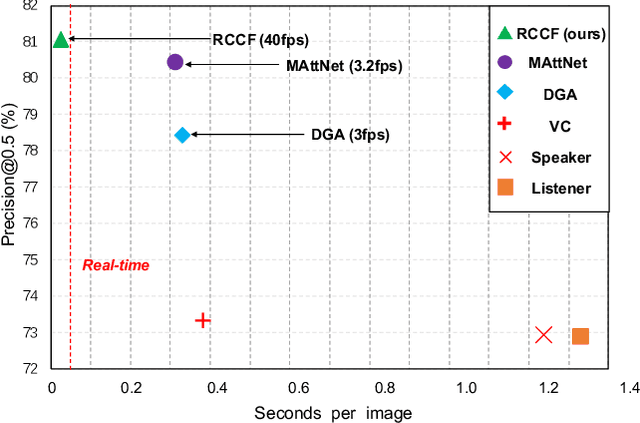
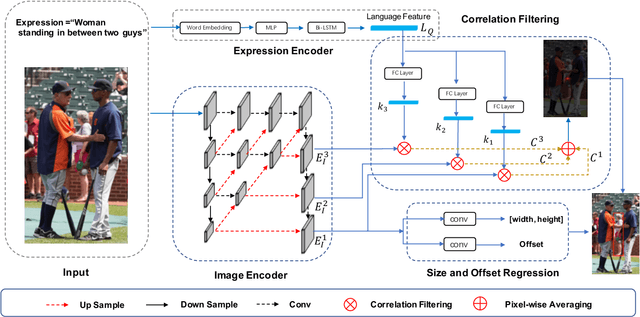
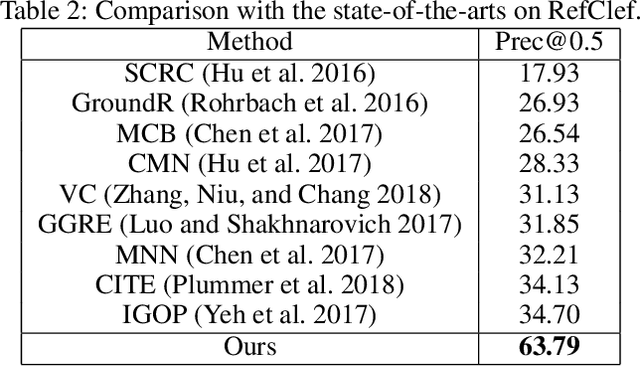
Referring expression comprehension aims to localize the object instance described by a natural language expression. Current referring expression methods have achieved pretty-well performance. However, none of them is able to achieve real-time inference without accuracy drop. The reason for the relatively slow inference speed is that these methods artificially split the referring expression comprehension into two sequential stages including proposal generation and proposal ranking. It does not exactly conform to the habit of human cognition. To this end, we propose a novel Real-time Cross-modality Correlation Filtering method (RCCF). RCCF reformulates the referring expression as a correlation filtering process. The expression is first mapped from the language domain to the visual domain and then treated as a template (kernel) to perform correlation filtering on the image feature map. The peak value in the correlation heatmap indicates the center points of the target box. In addition, RCCF also regresses a 2-D object size and 2-D offset. The center point coordinates, object size and center point offset together form the target bounding-box. Our method runs at 40 FPS while achieves leading performance in RefClef, RefCOCO, RefCOCO+, and RefCOCOg benchmarks. In the challenge RefClef dataset, our methods almost double the state-of-the-art performance(34.70% increased to 63.79%). We hope this work can arouse more attention and studies to the new cross-modality correlation filtering framework as well as the one-stage framework for referring expression comprehension.
The Devil of Face Recognition is in the Noise
Jul 31, 2018

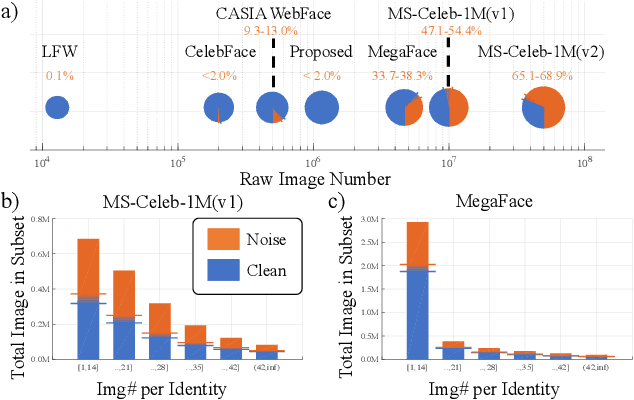
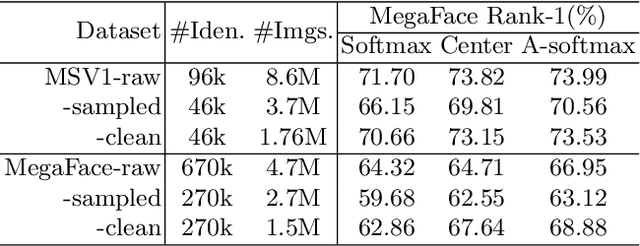
The growing scale of face recognition datasets empowers us to train strong convolutional networks for face recognition. While a variety of architectures and loss functions have been devised, we still have a limited understanding of the source and consequence of label noise inherent in existing datasets. We make the following contributions: 1) We contribute cleaned subsets of popular face databases, i.e., MegaFace and MS-Celeb-1M datasets, and build a new large-scale noise-controlled IMDb-Face dataset. 2) With the original datasets and cleaned subsets, we profile and analyze label noise properties of MegaFace and MS-Celeb-1M. We show that a few orders more samples are needed to achieve the same accuracy yielded by a clean subset. 3) We study the association between different types of noise, i.e., label flips and outliers, with the accuracy of face recognition models. 4) We investigate ways to improve data cleanliness, including a comprehensive user study on the influence of data labeling strategies to annotation accuracy. The IMDb-Face dataset has been released on https://github.com/fwang91/IMDb-Face.