 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil of Face Recognition is in the Noise
Paper and Code


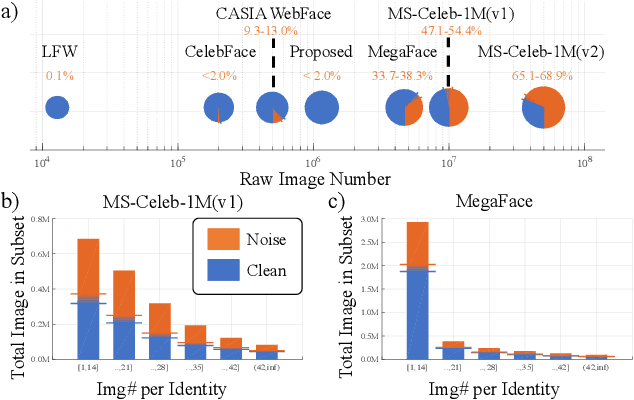
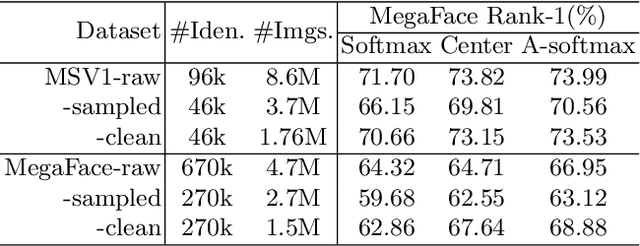
The growing scale of face recognition datasets empowers us to train strong convolutional networks for face recognition. While a variety of architectures and loss functions have been devised, we still have a limited understanding of the source and consequence of label noise inherent in existing datasets. We make the following contributions: 1) We contribute cleaned subsets of popular face databases, i.e., MegaFace and MS-Celeb-1M datasets, and build a new large-scale noise-controlled IMDb-Face dataset. 2) With the original datasets and cleaned subsets, we profile and analyze label noise properties of MegaFace and MS-Celeb-1M. We show that a few orders more samples are needed to achieve the same accuracy yielded by a clean subset. 3) We study the association between different types of noise, i.e., label flips and outliers, with the accuracy of face recognition models. 4) We investigate ways to improve data cleanliness, including a comprehensive user study on the influence of data labeling strategies to annotation accuracy. The IMDb-Face dataset has been released on https://github.com/fwang91/IMDb-Face.