 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoxMind: Closed-loop AI strategy optimization for elite boxing validated in the 2024 Olympics
Jan 16, 2026Competitive sports require sophisticated tactical analysis, yet combat disciplines like boxing remain underdeveloped in AI-driven analytics due to the complexity of action dynamics and the lack of structured tactical representations. To address this, we present BoxMind, a closed-loop AI expert system validated in elite boxing competition. By defining atomic punch events with precise temporal boundaries and spatial and technical attributes, we parse match footage into 18 hierarchical technical-tactical indicators. We then propose a graph-based predictive model that fuses these explicit technical-tactical profiles with learnable, time-variant latent embeddings to capture the dynamics of boxer matchups. Modeling match outcome as a differentiable function of technical-tactical indicators, we turn winning probability gradients into executable tactical adjustments. Experiments show that the outcome prediction model achieves state-of-the-art performance, with 69.8% accuracy on BoxerGraph test set and 87.5% on Olympic matches. Using this predictive model as a foundation, the system generates strategic recommendations that demonstrate proficiency comparable to human experts. BoxMind is validated through a closed-loop deployment during the 2024 Paris Olympics, directly contributing to the Chinese National Team's historic achievement of three gold and two silver medals. BoxMind establishes a replicable paradigm for transforming unstructured video data into strategic intelligence, bridging the gap between computer vision and decision support in competitive sports.
The Devil of Face Recognition is in the Noise
Jul 31, 2018

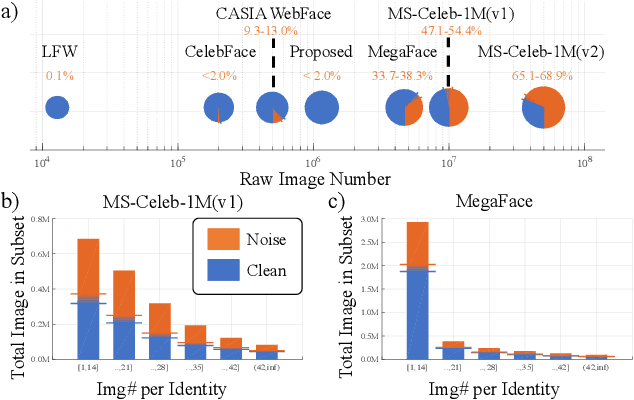
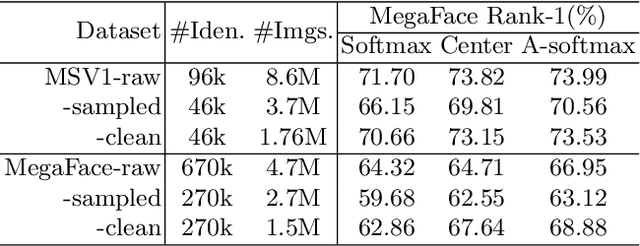
The growing scale of face recognition datasets empowers us to train strong convolutional networks for face recognition. While a variety of architectures and loss functions have been devised, we still have a limited understanding of the source and consequence of label noise inherent in existing datasets. We make the following contributions: 1) We contribute cleaned subsets of popular face databases, i.e., MegaFace and MS-Celeb-1M datasets, and build a new large-scale noise-controlled IMDb-Face dataset. 2) With the original datasets and cleaned subsets, we profile and analyze label noise properties of MegaFace and MS-Celeb-1M. We show that a few orders more samples are needed to achieve the same accuracy yielded by a clean subset. 3) We study the association between different types of noise, i.e., label flips and outliers, with the accuracy of face recognition models. 4) We investigate ways to improve data cleanliness, including a comprehensive user study on the influence of data labeling strategies to annotation accuracy. The IMDb-Face dataset has been released on https://github.com/fwang91/IMDb-Face.