 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathDuels: Evaluating LLMs as Problem Posers and Solvers
Apr 23, 2026As frontier language models attain near-ceiling performance on static mathematical benchmarks, existing evaluations are increasingly unable to differentiate model capabilities, largely because they cast models solely as solvers of fixed problem sets. We introduce MathDuels, a self-play benchmark in which models occupy dual roles: each authors math problems under adversarial prompting and solves problems authored by every other participant. Problems are produced through a three-stage generation pipeline (meta-prompting, problem generation, and difficulty amplification), and validated by an independent verifier that excludes ill-posed questions. A Rasch model (Rasch, 1993) jointly estimates solver abilities and problem difficulties; author quality is derived from the difficulties of each model's authored problems. Experiments across 19 frontier models reveal that authoring and solving capabilities are partially decoupled, and that dual-role evaluation reveals capability separations invisible in single-role benchmarks. As newer models enter the arena, they produce problems that defeat previously dominant solvers, so the benchmark's difficulty co-evolves with participant strength rather than saturating at a fixed ceiling. We host a public leaderboard that updates as new models are released.
Delta Activations: A Representation for Finetuned Large Language Models
Sep 04, 2025



The success of powerful open source Large Language Models (LLMs) has enabled the community to create a vast collection of post-trained models adapted to specific tasks and domains. However, navigating and understanding these models remains challenging due to inconsistent metadata and unstructured repositories. We introduce Delta Activations, a method to represent finetuned models as vector embeddings by measuring shifts in their internal activations relative to a base model. This representation allows for effective clustering by domain and task, revealing structure in the model landscape. Delta Activations also demonstrate desirable properties: it is robust across finetuning settings and exhibits an additive property when finetuning datasets are mixed. In addition, we show that Delta Activations can embed tasks via few-shot finetuning, and further explore its use for model selection and merging. We hope Delta Activations can facilitate the practice of reusing publicly available models. Code is available at https://github.com/OscarXZQ/delta_activations.
Generative Modeling of Weights: Generalization or Memorization?
Jun 09, 2025Generative models, with their success in image and video generation, have recently been explored for synthesizing effective neural network weights. These approaches take trained neural network checkpoints as training data, and aim to generate high-performing neural network weights during inference. In this work, we examine four representative methods on their ability to generate novel model weights, i.e., weights that are different from the checkpoints seen during training. Surprisingly, we find that these methods synthesize weights largely by memorization: they produce either replicas, or at best simple interpolations, of the training checkpoints. Current methods fail to outperform simple baselines, such as adding noise to the weights or taking a simple weight ensemble, in obtaining different and simultaneously high-performing models. We further show that this memorization cannot be effectively mitigated by modifying modeling factors commonly associated with memorization in image diffusion models, or applying data augmentations. Our findings provide a realistic assessment of what types of data current generative models can model, and highlight the need for more careful evaluation of generative models in new domains. Our code is available at https://github.com/boyazeng/weight_memorization.
Idiosyncrasies in Large Language Models
Feb 17, 2025



In this work, we unveil and study idiosyncrasies in Large Language Models (LLMs) -- unique patterns in their outputs that can be used to distinguish the models. To do so, we consider a simple classification task: given a particular text output, the objective is to predict the source LLM that generates the text. We evaluate this synthetic task across various groups of LLMs and find that simply fine-tuning existing text embedding models on LLM-generated texts yields excellent classification accuracy. Notably, we achieve 97.1% accuracy on held-out validation data in the five-way classification problem involving ChatGPT, Claude, Grok, Gemini, and DeepSeek. Our further investigation reveals that these idiosyncrasies are rooted in word-level distributions. These patterns persist even when the texts are rewritten, translated, or summarized by an external LLM, suggesting that they are also encoded in the semantic content. Additionally, we leverage LLM as judges to generate detailed, open-ended descriptions of each model's idiosyncrasies. Finally, we discuss the broader implications of our findings, particularly for training on synthetic data and inferring model similarity. Code is available at https://github.com/locuslab/llm-idiosyncrasies.
Initializing Models with Larger Ones
Nov 30, 2023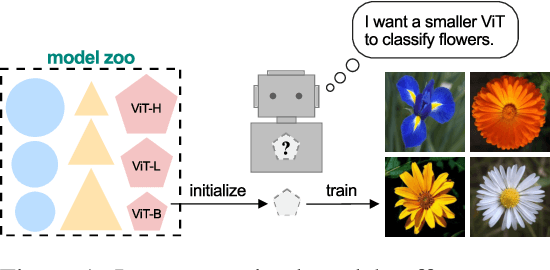



Weight initialization plays an important role in neural network training. Widely used initialization methods are proposed and evaluated for networks that are trained from scratch. However, the growing number of pretrained models now offers new opportunities for tackling this classical problem of weight initialization. In this work, we introduce weight selection, a method for initializing smaller models by selecting a subset of weights from a pretrained larger model. This enables the transfer of knowledge from pretrained weights to smaller models. Our experiments demonstrate that weight selection can significantly enhance the performance of small models and reduce their training time. Notably, it can also be used together with knowledge distillation. Weight selection offers a new approach to leverage the power of pretrained models in resource-constrained settings, and we hope it can be a useful tool for training small models in the large-model era. Code is available at https://github.com/OscarXZQ/weight-selection.
A Coefficient Makes SVRG Effective
Nov 09, 2023Stochastic Variance Reduced Gradient (SVRG), introduced by Johnson & Zhang (2013), is a theoretically compelling optimization method. However, as Defazio & Bottou (2019) highlights, its effectiveness in deep learning is yet to be proven. In this work, we demonstrate the potential of SVRG in optimizing real-world neural networks. Our analysis finds that, for deeper networks, the strength of the variance reduction term in SVRG should be smaller and decrease as training progresses. Inspired by this, we introduce a multiplicative coefficient $\alpha$ to control the strength and adjust it through a linear decay schedule. We name our method $\alpha$-SVRG. Our results show $\alpha$-SVRG better optimizes neural networks, consistently reducing training loss compared to both baseline and the standard SVRG across various architectures and image classification datasets. We hope our findings encourage further exploration into variance reduction techniques in deep learning. Code is available at https://github.com/davidyyd/alpha-SVRG.
Dropout Reduces Underfitting
Mar 02, 2023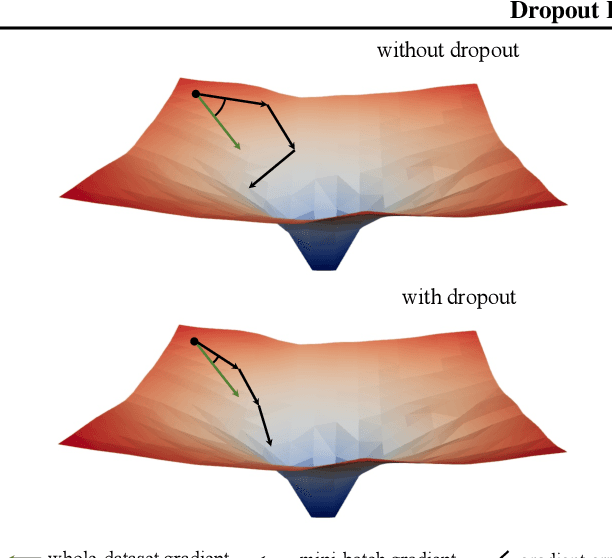



Introduced by Hinton et al. in 2012, dropout has stood the test of time as a regularizer for preventing overfitting in neural networks. In this study, we demonstrate that dropout can also mitigate underfitting when used at the start of training. During the early phase, we find dropout reduces the directional variance of gradients across mini-batches and helps align the mini-batch gradients with the entire dataset's gradient. This helps counteract the stochasticity of SGD and limit the influence of individual batches on model training. Our findings lead us to a solution for improving performance in underfitting models - early dropout: dropout is applied only during the initial phases of training, and turned off afterwards. Models equipped with early dropout achieve lower final training loss compared to their counterparts without dropout. Additionally, we explore a symmetric technique for regularizing overfitting models - late dropout, where dropout is not used in the early iterations and is only activated later in training. Experiments on ImageNet and various vision tasks demonstrate that our methods consistently improve generalization accuracy. Our results encourage more research on understanding regularization in deep learning and our methods can be useful tools for future neural network training, especially in the era of large data. Code is available at https://github.com/facebookresearch/dropout .