 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroSMPC: A Neural Network guided Sampling Based MPC for On-Road Autonomous Driving
Oct 19, 2023



In this paper we show an effective means of integrating data driven frameworks to sampling based optimal control to vastly reduce the compute time for easy adoption and adaptation to real time applications such as on-road autonomous driving in the presence of dynamic actors. Presented with training examples, a spatio-temporal CNN learns to predict the optimal mean control over a finite horizon that precludes further resampling, an iterative process that makes sampling based optimal control formulations difficult to adopt in real time settings. Generating control samples around the network-predicted optimal mean retains the advantage of sample diversity while enabling real time rollout of trajectories that avoids multiple dynamic obstacles in an on-road navigation setting. Further the 3D CNN architecture implicitly learns the future trajectories of the dynamic agents in the scene resulting in successful collision free navigation despite no explicit future trajectory prediction. We show performance gain over multiple baselines in a number of on-road scenes through closed loop simulations in CARLA. We also showcase the real world applicability of our system by running it on our custom Autonomous Driving Platform (AutoDP).
ConceptFusion: Open-set Multimodal 3D Mapping
Feb 15, 2023Building 3D maps of the environment is central to robot navigation, planning, and interaction with objects in a scene. Most existing approaches that integrate semantic concepts with 3D maps largely remain confined to the closed-set setting: they can only reason about a finite set of concepts, pre-defined at training time. Further, these maps can only be queried using class labels, or in recent work, using text prompts. We address both these issues with ConceptFusion, a scene representation that is (1) fundamentally open-set, enabling reasoning beyond a closed set of concepts and (ii) inherently multimodal, enabling a diverse range of possible queries to the 3D map, from language, to images, to audio, to 3D geometry, all working in concert. ConceptFusion leverages the open-set capabilities of today's foundation models pre-trained on internet-scale data to reason about concepts across modalities such as natural language, images, and audio. We demonstrate that pixel-aligned open-set features can be fused into 3D maps via traditional SLAM and multi-view fusion approaches. This enables effective zero-shot spatial reasoning, not needing any additional training or finetuning, and retains long-tailed concepts better than supervised approaches, outperforming them by more than 40% margin on 3D IoU. We extensively evaluate ConceptFusion on a number of real-world datasets, simulated home environments, a real-world tabletop manipulation task, and an autonomous driving platform. We showcase new avenues for blending foundation models with 3D open-set multimodal mapping. For more information, visit our project page https://concept-fusion.github.io or watch our 5-minute explainer video https://www.youtube.com/watch?v=rkXgws8fiDs
Drift Reduced Navigation with Deep Explainable Features
Mar 14, 2022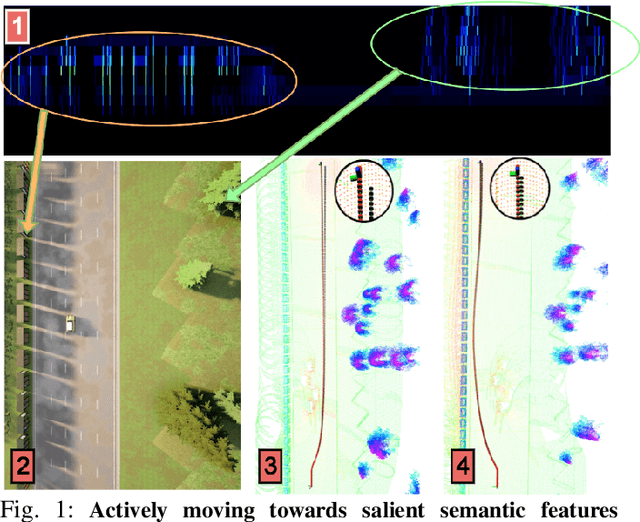
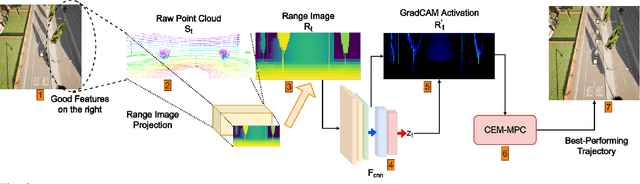
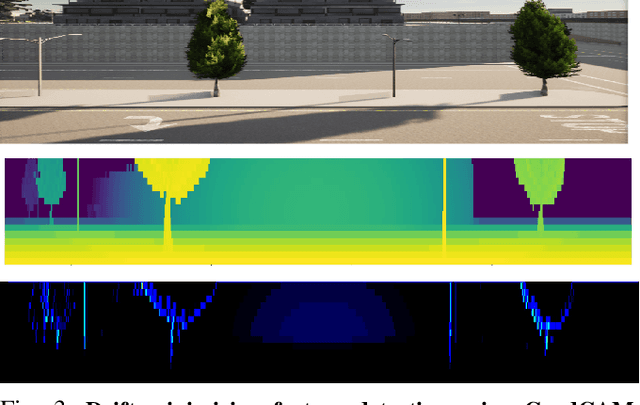

Modern autonomous vehicles (AVs) often rely on vision, LIDAR, and even radar-based simultaneous localization and mapping (SLAM) frameworks for precise localization and navigation. However, modern SLAM frameworks often lead to unacceptably high levels of drift (i.e., localization error) when AVs observe few visually distinct features or encounter occlusions due to dynamic obstacles. This paper argues that minimizing drift must be a key desiderata in AV motion planning, which requires an AV to take active control decisions to move towards feature-rich regions while also minimizing conventional control cost. To do so, we first introduce a novel data-driven perception module that observes LIDAR point clouds and estimates which features/regions an AV must navigate towards for drift minimization. Then, we introduce an interpretable model predictive controller (MPC) that moves an AV toward such feature-rich regions while avoiding visual occlusions and gracefully trading off drift and control cost. Our experiments on challenging, dynamic scenarios in the state-of-the-art CARLA simulator indicate our method reduces drift up to 76.76% compared to benchmark approaches.
Learning Actions for Drift-Free Navigation in Highly Dynamic Scenes
Oct 28, 2021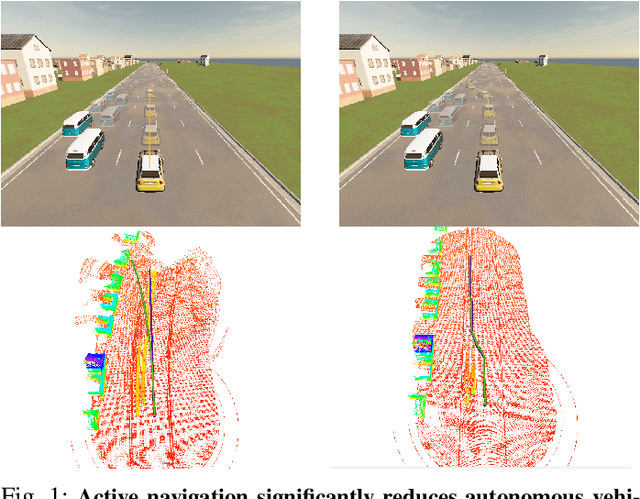
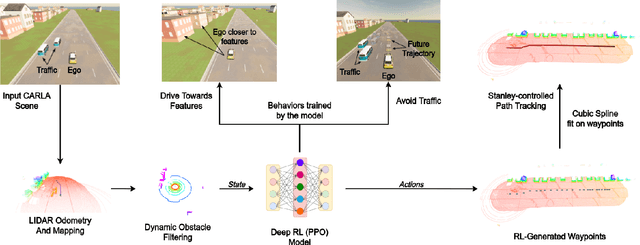
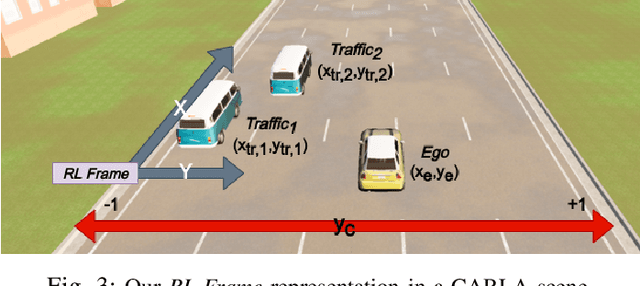
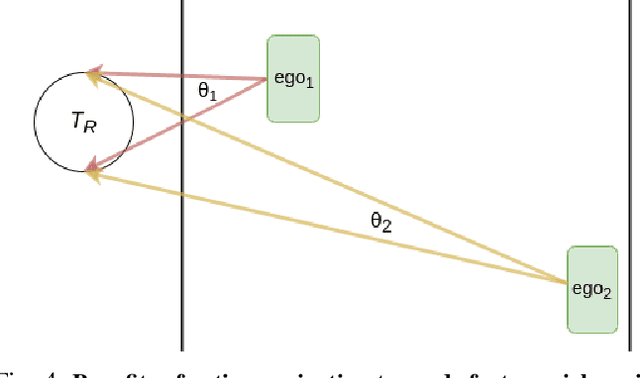
We embark on a hitherto unreported problem of an autonomous robot (self-driving car) navigating in dynamic scenes in a manner that reduces its localization error and eventual cumulative drift or Absolute Trajectory Error, which is pronounced in such dynamic scenes. With the hugely popular Velodyne-16 3D LIDAR as the main sensing modality, and the accurate LIDAR-based Localization and Mapping algorithm, LOAM, as the state estimation framework, we show that in the absence of a navigation policy, drift rapidly accumulates in the presence of moving objects. To overcome this, we learn actions that lead to drift-minimized navigation through a suitable set of reward and penalty functions. We use Proximal Policy Optimization, a class of Deep Reinforcement Learning methods, to learn the actions that result in drift-minimized trajectories. We show by extensive comparisons on a variety of synthetic, yet photo-realistic scenes made available through the CARLA Simulator the superior performance of the proposed framework vis-a-vis methods that do not adopt such policies.