 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Fairness: Discovery and Mitigation of Unknown Sensitive Attributes
Paper and Code
Jul 28, 2021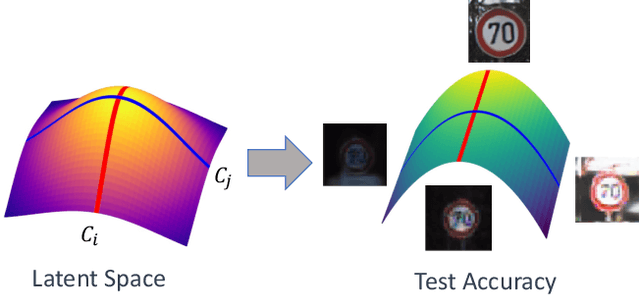
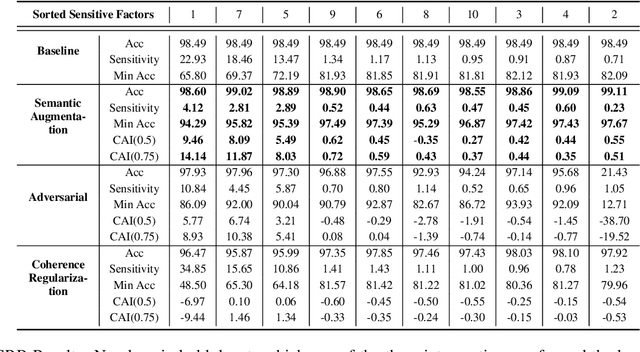
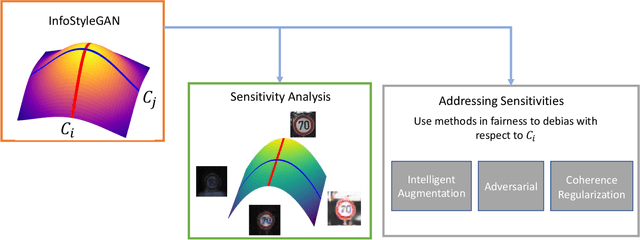
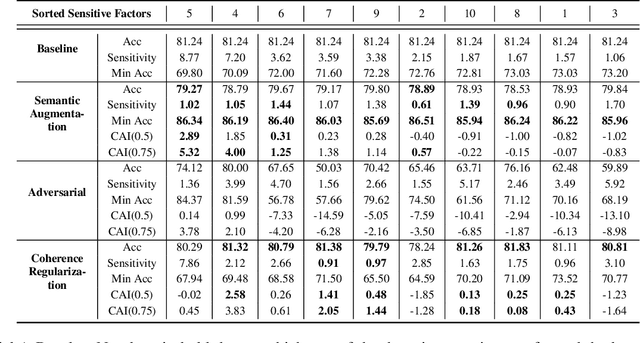
When deploying artificial intelligence (AI) in the real world, being able to trust the operation of the AI by characterizing how it performs is an ever-present and important topic. An important and still largely unexplored task in this characterization is determining major factors within the real world that affect the AI's behavior, such as weather conditions or lighting, and either a) being able to give justification for why it may have failed or b) eliminating the influence the factor has. Determining these sensitive factors heavily relies on collected data that is diverse enough to cover numerous combinations of these factors, which becomes more onerous when having many potential sensitive factors or operating in complex environments. This paper investigates methods that discover and separate out individual semantic sensitive factors from a given dataset to conduct this characterization as well as addressing mitigation of these factors' sensitivity. We also broaden remediation of fairness, which normally only addresses socially relevant factors, and widen it to deal with the desensitization of AI with regard to all possible aspects of variation in the domain. The proposed methods which discover these major factors reduce the potentially onerous demands of collecting a sufficiently diverse dataset. In experiments using the road sign (GTSRB) and facial imagery (CelebA) datasets, we show the promise of using this scheme to perform this characterization and remediation and demonstrate that our approach outperforms state of the art approaches.