 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Fairness Impact of Differentially Private Synthetic Data
May 09, 2022
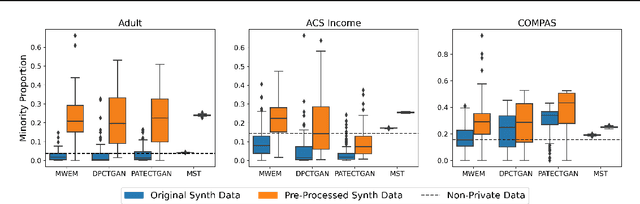

Differentially private (DP) synthetic data is a promising approach to maximizing the utility of data containing sensitive information. Due to the suppression of underrepresented classes that is often required to achieve privacy, however, it may be in conflict with fairness. We evaluate four DP synthesizers and present empirical results indicating that three of these models frequently degrade fairness outcomes on downstream binary classification tasks. We draw a connection between fairness and the proportion of minority groups present in the generated synthetic data, and find that training synthesizers on data that are pre-processed via a multi-label undersampling method can promote more fair outcomes without degrading accuracy.
Spending Privacy Budget Fairly and Wisely
Apr 27, 2022
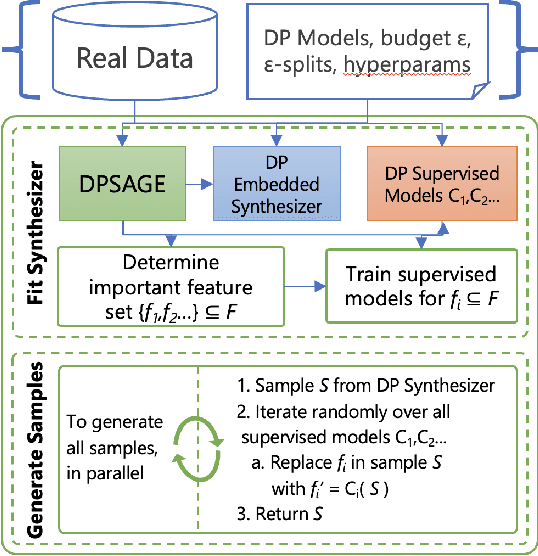

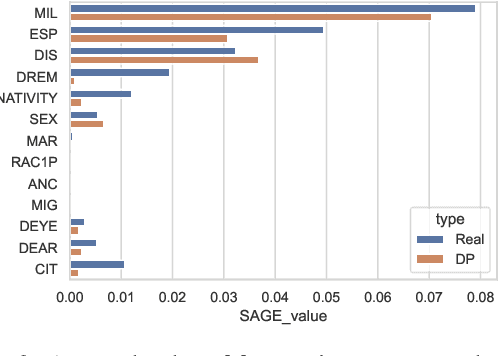
Differentially private (DP) synthetic data generation is a practical method for improving access to data as a means to encourage productive partnerships. One issue inherent to DP is that the "privacy budget" is generally "spent" evenly across features in the data set. This leads to good statistical parity with the real data, but can undervalue the conditional probabilities and marginals that are critical for predictive quality of synthetic data. Further, loss of predictive quality may be non-uniform across the data set, with subsets that correspond to minority groups potentially suffering a higher loss. In this paper, we develop ensemble methods that distribute the privacy budget "wisely" to maximize predictive accuracy of models trained on DP data, and "fairly" to bound potential disparities in accuracy across groups and reduce inequality. Our methods are based on the insights that feature importance can inform how privacy budget is allocated, and, further, that per-group feature importance and fairness-related performance objectives can be incorporated in the allocation. These insights make our methods tunable to social contexts, allowing data owners to produce balanced synthetic data for predictive analysis.
Differentially Private Synthetic Data: Applied Evaluations and Enhancements
Nov 11, 2020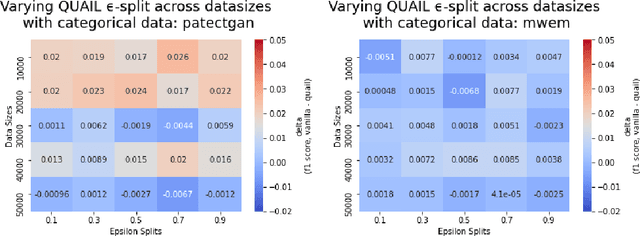
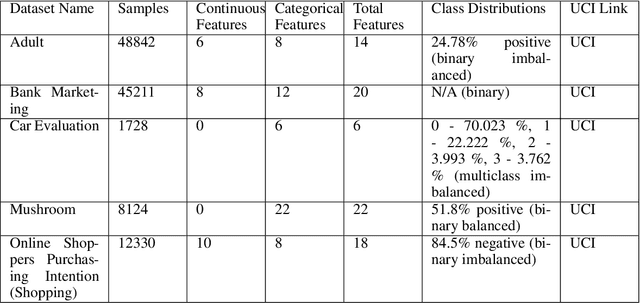

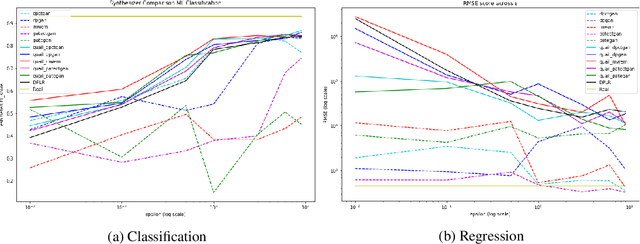
Machine learning practitioners frequently seek to leverage the most informative available data, without violating the data owner's privacy, when building predictive models. Differentially private data synthesis protects personal details from exposure, and allows for the training of differentially private machine learning models on privately generated datasets. But how can we effectively assess the efficacy of differentially private synthetic data? In this paper, we survey four differentially private generative adversarial networks for data synthesis. We evaluate each of them at scale on five standard tabular datasets, and in two applied industry scenarios. We benchmark with novel metrics from recent literature and other standard machine learning tools. Our results suggest some synthesizers are more applicable for different privacy budgets, and we further demonstrate complicating domain-based tradeoffs in selecting an approach. We offer experimental learning on applied machine learning scenarios with private internal data to researchers and practioners alike. In addition, we propose QUAIL, an ensemble-based modeling approach to generating synthetic data. We examine QUAIL's tradeoffs, and note circumstances in which it outperforms baseline differentially private supervised learning models under the same budget constraint.