 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpending Privacy Budget Fairly and Wisely
Paper and Code

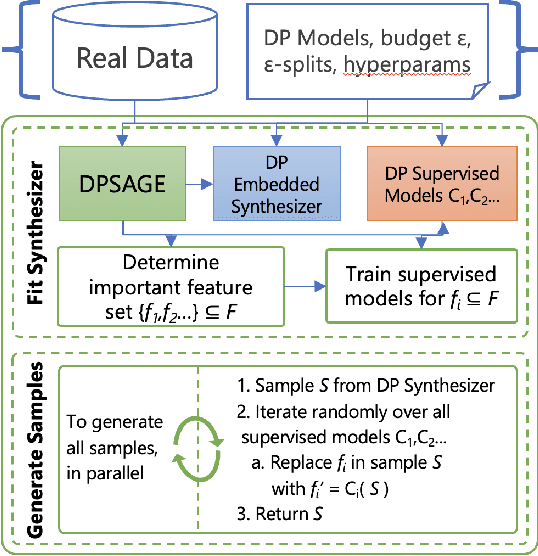

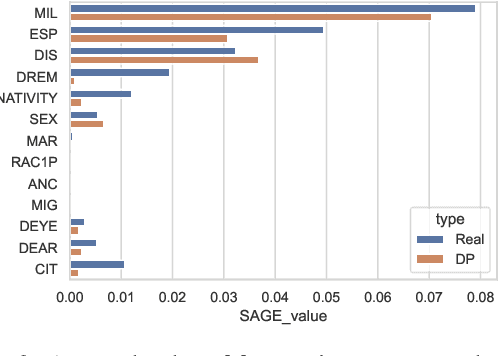
Differentially private (DP) synthetic data generation is a practical method for improving access to data as a means to encourage productive partnerships. One issue inherent to DP is that the "privacy budget" is generally "spent" evenly across features in the data set. This leads to good statistical parity with the real data, but can undervalue the conditional probabilities and marginals that are critical for predictive quality of synthetic data. Further, loss of predictive quality may be non-uniform across the data set, with subsets that correspond to minority groups potentially suffering a higher loss. In this paper, we develop ensemble methods that distribute the privacy budget "wisely" to maximize predictive accuracy of models trained on DP data, and "fairly" to bound potential disparities in accuracy across groups and reduce inequality. Our methods are based on the insights that feature importance can inform how privacy budget is allocated, and, further, that per-group feature importance and fairness-related performance objectives can be incorporated in the allocation. These insights make our methods tunable to social contexts, allowing data owners to produce balanced synthetic data for predictive analysis.