 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Synthetic Data: Applied Evaluations and Enhancements
Nov 11, 2020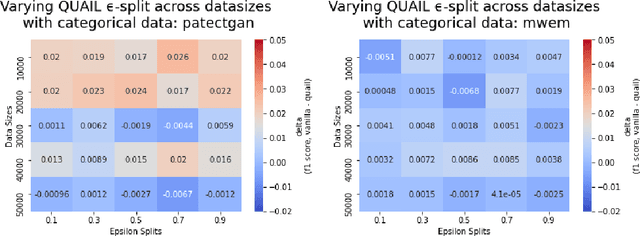
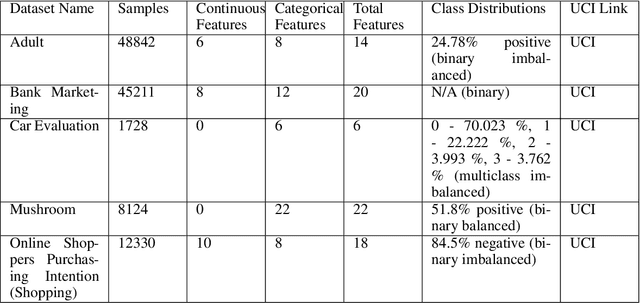

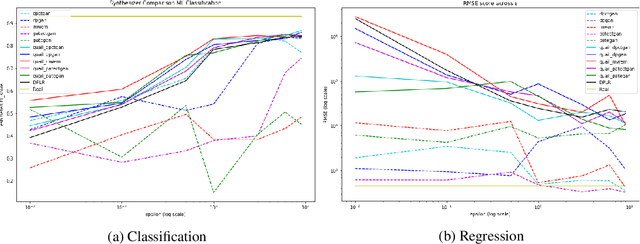
Machine learning practitioners frequently seek to leverage the most informative available data, without violating the data owner's privacy, when building predictive models. Differentially private data synthesis protects personal details from exposure, and allows for the training of differentially private machine learning models on privately generated datasets. But how can we effectively assess the efficacy of differentially private synthetic data? In this paper, we survey four differentially private generative adversarial networks for data synthesis. We evaluate each of them at scale on five standard tabular datasets, and in two applied industry scenarios. We benchmark with novel metrics from recent literature and other standard machine learning tools. Our results suggest some synthesizers are more applicable for different privacy budgets, and we further demonstrate complicating domain-based tradeoffs in selecting an approach. We offer experimental learning on applied machine learning scenarios with private internal data to researchers and practioners alike. In addition, we propose QUAIL, an ensemble-based modeling approach to generating synthetic data. We examine QUAIL's tradeoffs, and note circumstances in which it outperforms baseline differentially private supervised learning models under the same budget constraint.