 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards In-Vehicle Multi-Task Facial Attribute Recognition: Investigating Synthetic Data and Vision Foundation Models
Mar 10, 2024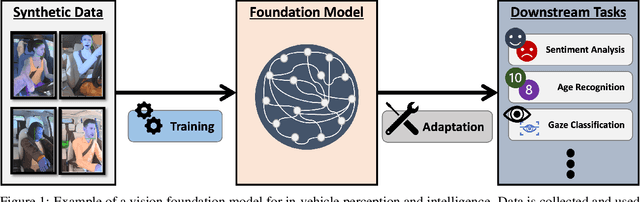
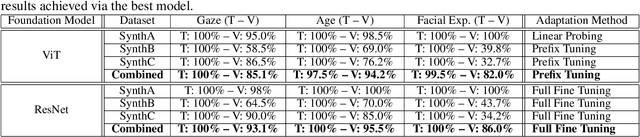


In the burgeoning field of intelligent transportation systems, enhancing vehicle-driver interaction through facial attribute recognition, such as facial expression, eye gaze, age, etc., is of paramount importance for safety, personalization, and overall user experience. However, the scarcity of comprehensive large-scale, real-world datasets poses a significant challenge for training robust multi-task models. Existing literature often overlooks the potential of synthetic datasets and the comparative efficacy of state-of-the-art vision foundation models in such constrained settings. This paper addresses these gaps by investigating the utility of synthetic datasets for training complex multi-task models that recognize facial attributes of passengers of a vehicle, such as gaze plane, age, and facial expression. Utilizing transfer learning techniques with both pre-trained Vision Transformer (ViT) and Residual Network (ResNet) models, we explore various training and adaptation methods to optimize performance, particularly when data availability is limited. We provide extensive post-evaluation analysis, investigating the effects of synthetic data distributions on model performance in in-distribution data and out-of-distribution inference. Our study unveils counter-intuitive findings, notably the superior performance of ResNet over ViTs in our specific multi-task context, which is attributed to the mismatch in model complexity relative to task complexity. Our results highlight the challenges and opportunities for enhancing the use of synthetic data and vision foundation models in practical applications.
One Agent Too Many: User Perspectives on Approaches to Multi-agent Conversational AI
Jan 13, 2024Conversational agents have been gaining increasing popularity in recent years. Influenced by the widespread adoption of task-oriented agents such as Apple Siri and Amazon Alexa, these agents are being deployed into various applications to enhance user experience. Although these agents promote "ask me anything" functionality, they are typically built to focus on a single or finite set of expertise. Given that complex tasks often require more than one expertise, this results in the users needing to learn and adopt multiple agents. One approach to alleviate this is to abstract the orchestration of agents in the background. However, this removes the option of choice and flexibility, potentially harming the ability to complete tasks. In this paper, we explore these different interaction experiences (one agent for all) vs (user choice of agents) for conversational AI. We design prototypes for each, systematically evaluating their ability to facilitate task completion. Through a series of conducted user studies, we show that users have a significant preference for abstracting agent orchestration in both system usability and system performance. Additionally, we demonstrate that this mode of interaction is able to provide quality responses that are rated within 1% of human-selected answers.
One Agent To Rule Them All: Towards Multi-agent Conversational AI
Mar 15, 2022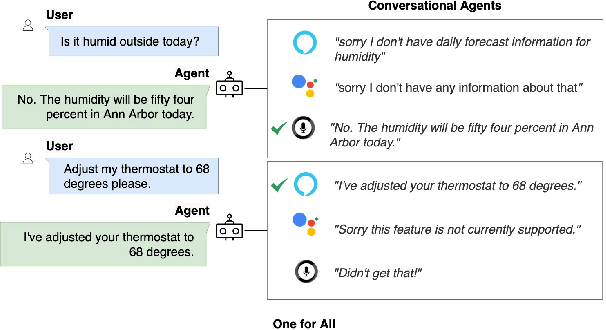
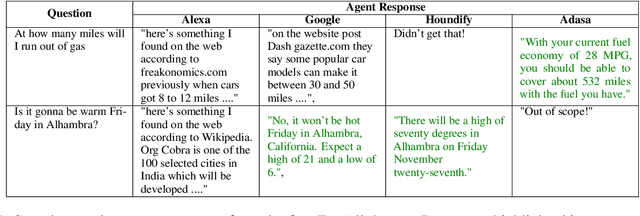
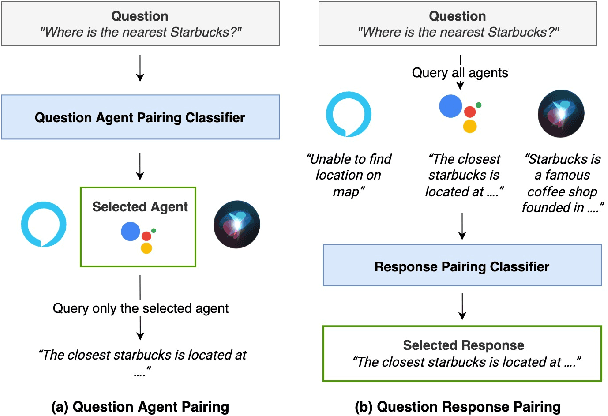
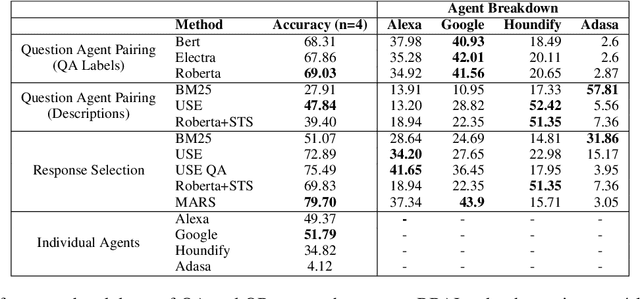
The increasing volume of commercially available conversational agents (CAs) on the market has resulted in users being burdened with learning and adopting multiple agents to accomplish their tasks. Though prior work has explored supporting a multitude of domains within the design of a single agent, the interaction experience suffers due to the large action space of desired capabilities. To address these problems, we introduce a new task BBAI: Black-Box Agent Integration, focusing on combining the capabilities of multiple black-box CAs at scale. We explore two techniques: question agent pairing and question response pairing aimed at resolving this task. Leveraging these techniques, we design One For All (OFA), a scalable system that provides a unified interface to interact with multiple CAs. Additionally, we introduce MARS: Multi-Agent Response Selection, a new encoder model for question response pairing that jointly encodes user question and agent response pairs. We demonstrate that OFA is able to automatically and accurately integrate an ensemble of commercially available CAs spanning disparate domains. Specifically, using the MARS encoder we achieve the highest accuracy on our BBAI task, outperforming strong baselines.
Predicting Driver Fatigue in Automated Driving with Explainability
Mar 03, 2021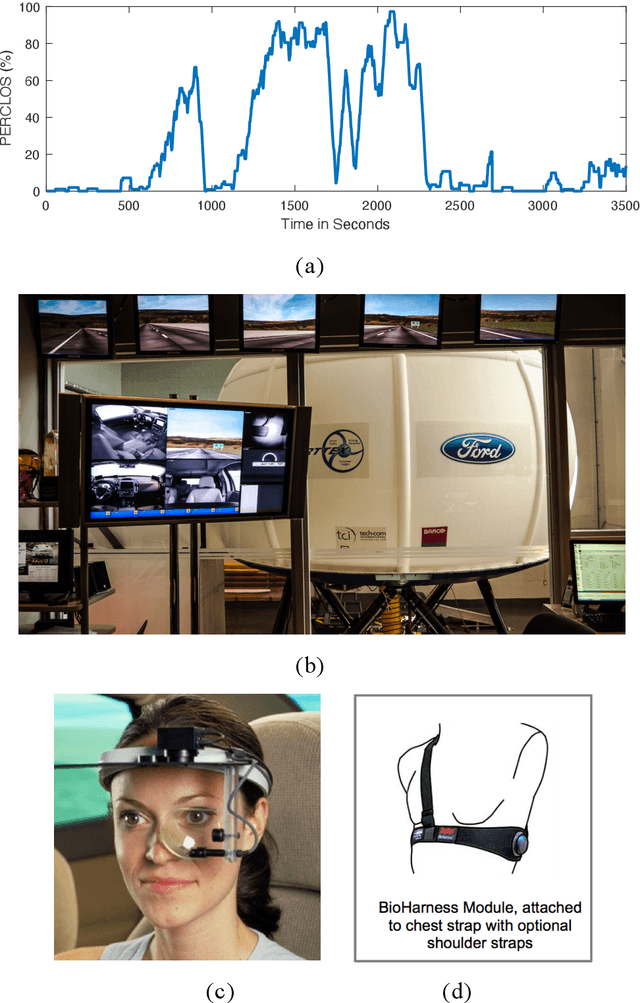
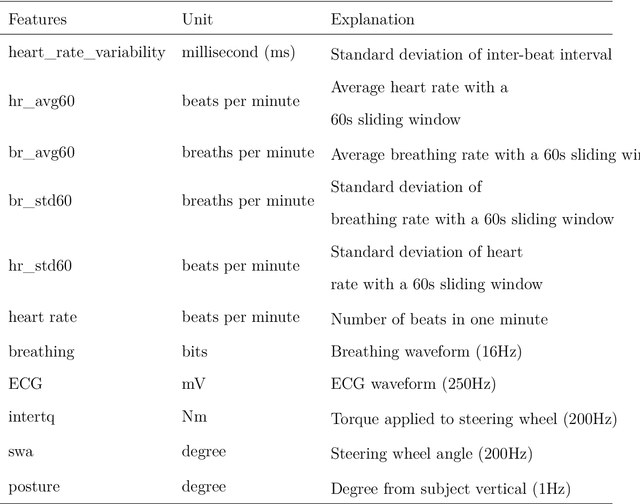
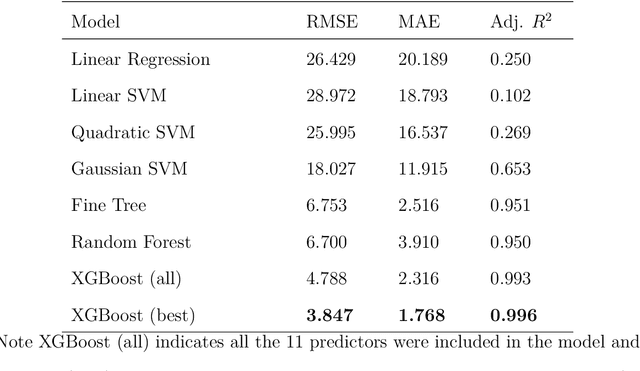
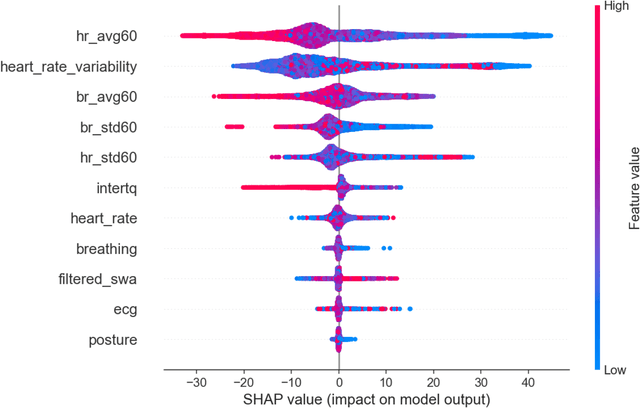
Research indicates that monotonous automated driving increases the incidence of fatigued driving. Although many prediction models based on advanced machine learning techniques were proposed to monitor driver fatigue, especially in manual driving, little is known about how these black-box machine learning models work. In this paper, we proposed a combination of eXtreme Gradient Boosting (XGBoost) and SHAP (SHapley Additive exPlanations) to predict driver fatigue with explanations due to their efficiency and accuracy. First, in order to obtain the ground truth of driver fatigue, PERCLOS (percentage of eyelid closure over the pupil over time) between 0 and 100 was used as the response variable. Second, we built a driver fatigue regression model using both physiological and behavioral measures with XGBoost and it outperformed other selected machine learning models with 3.847 root-mean-squared error (RMSE), 1.768 mean absolute error (MAE) and 0.996 adjusted $R^2$. Third, we employed SHAP to identify the most important predictor variables and uncovered the black-box XGBoost model by showing the main effects of most important predictor variables globally and explaining individual predictions locally. Such an explainable driver fatigue prediction model offered insights into how to intervene in automated driving when necessary, such as during the takeover transition period from automated driving to manual driving.