 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Agent To Rule Them All: Towards Multi-agent Conversational AI
Mar 15, 2022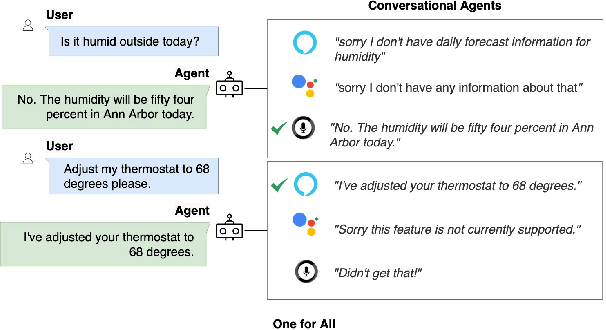
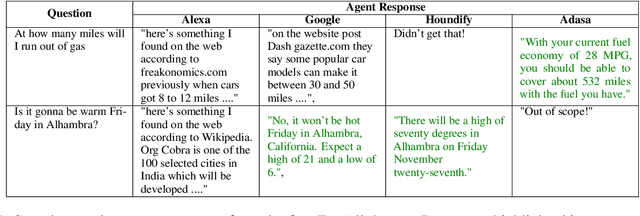
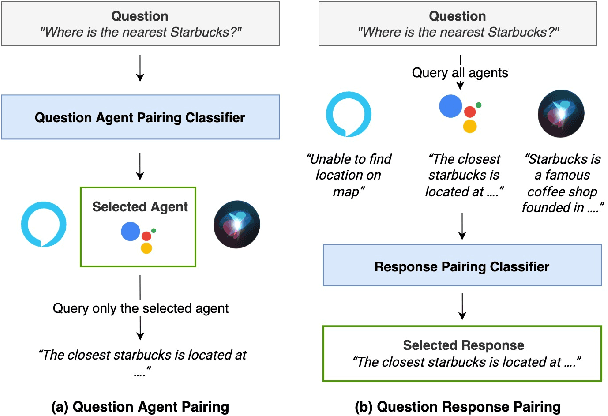
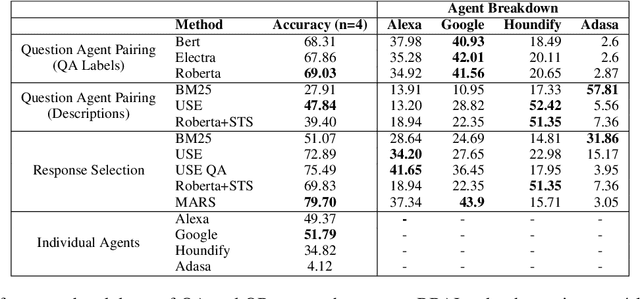
The increasing volume of commercially available conversational agents (CAs) on the market has resulted in users being burdened with learning and adopting multiple agents to accomplish their tasks. Though prior work has explored supporting a multitude of domains within the design of a single agent, the interaction experience suffers due to the large action space of desired capabilities. To address these problems, we introduce a new task BBAI: Black-Box Agent Integration, focusing on combining the capabilities of multiple black-box CAs at scale. We explore two techniques: question agent pairing and question response pairing aimed at resolving this task. Leveraging these techniques, we design One For All (OFA), a scalable system that provides a unified interface to interact with multiple CAs. Additionally, we introduce MARS: Multi-Agent Response Selection, a new encoder model for question response pairing that jointly encodes user question and agent response pairs. We demonstrate that OFA is able to automatically and accurately integrate an ensemble of commercially available CAs spanning disparate domains. Specifically, using the MARS encoder we achieve the highest accuracy on our BBAI task, outperforming strong baselines.
A Case for Backward Compatibility for Human-AI Teams
Jun 04, 2019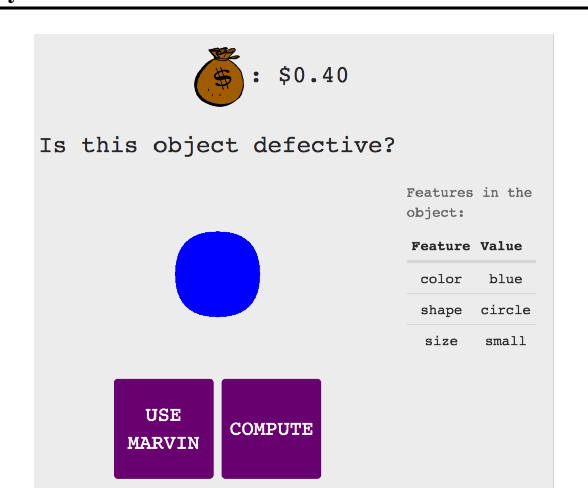
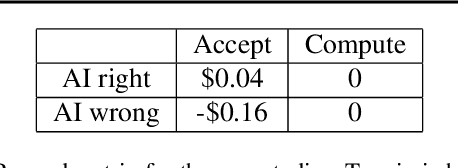
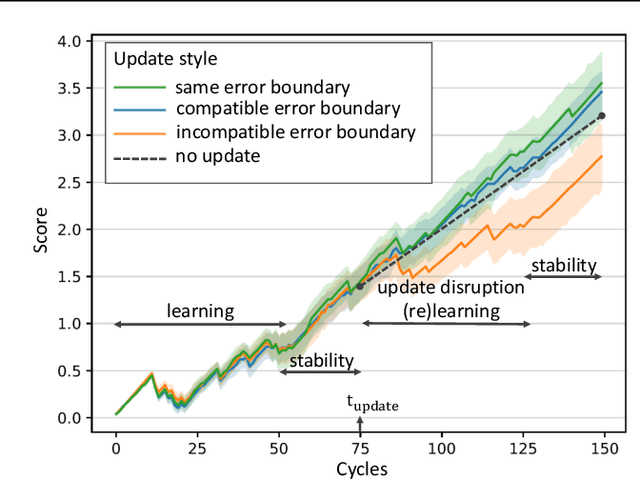
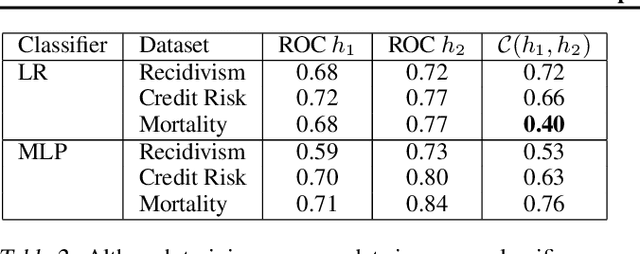
AI systems are being deployed to support human decision making in high-stakes domains. In many cases, the human and AI form a team, in which the human makes decisions after reviewing the AI's inferences. A successful partnership requires that the human develops insights into the performance of the AI system, including its failures. We study the influence of updates to an AI system in this setting. While updates can increase the AI's predictive performance, they may also lead to changes that are at odds with the user's prior experiences and confidence in the AI's inferences, hurting therefore the overall team performance. We introduce the notion of the compatibility of an AI update with prior user experience and present methods for studying the role of compatibility in human-AI teams. Empirical results on three high-stakes domains show that current machine learning algorithms do not produce compatible updates. We propose a re-training objective to improve the compatibility of an update by penalizing new errors. The objective offers full leverage of the performance/compatibility tradeoff, enabling more compatible yet accurate updates.