 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Motion Correction Via Iterative Nonlinear Optimization and Animation
Mar 28, 2022

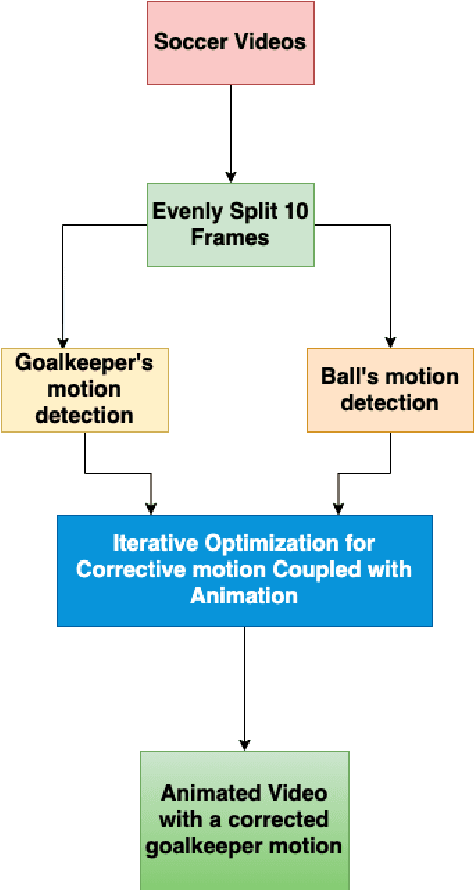
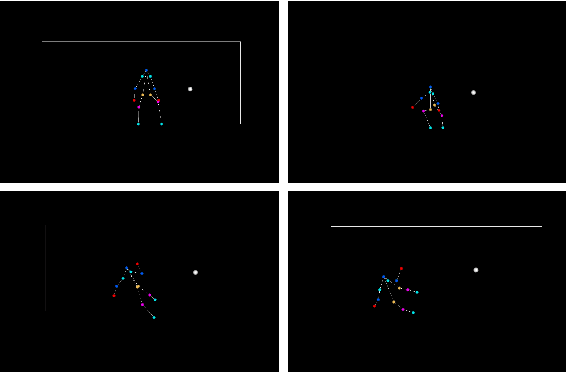
Here, we present an end-to-end method to create 2D animation for a goalkeeper attempting to block a penalty kick, and then correct that motion using an iterative nonlinear optimization scheme. The input is a raw video that is fed into pose and object detection networks to find the skeleton of the goalkeeper and the ball. The output is a set of key frames of the skeleton associated with the corrected motion so that if the goalkeeper missed the ball, the animation will show then successfully deflecting it. Our method is robust enough correct different kinds of mistakes the goalkeeper can make, such as not lunging far enough or jumping to the incorrect side. Our method is also meant to be semantically similar to the goalkeeper's original motion, which helps keep our animation grounded with respect to actual human behavior.
Text Classification for Task-based Source Code Related Questions
Oct 31, 2021There is a key demand to automatically generate code for small tasks for developers. Websites such as StackOverflow provide a simplistic way by offering solutions in small snippets which provide a complete answer to whatever task question the developer wants to code. Natural Language Processing and particularly Question-Answering Systems are very helpful in resolving and working on these tasks. In this paper, we develop a two-fold deep learning model: Seq2Seq and a binary classifier that takes in the intent (which is in natural language) and code snippets in Python. We train both the intent and the code utterances in the Seq2Seq model, where we decided to compare the effect of the hidden layer embedding from the encoder for representing the intent and similarly, using the decoder's hidden layer embeddings for the code sequence. Then we combine both these embeddings and then train a simple binary neural network classifier model for predicting if the intent is correctly answered by the predicted code sequence from the seq2seq model. We find that the hidden state layer's embeddings perform slightly better than regular standard embeddings from a constructed vocabulary. We experimented with our tests on the CoNaLa dataset in addition to the StaQC database consisting of simple task-code snippet-based pairs. We empirically establish that using additional pre-trained embeddings for code snippets in Python is less context-based in comparison to using hidden state context vectors from seq2seq models.