 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis in Drug Reviews using Supervised Machine Learning Algorithms
Paper and Code
Mar 21, 2020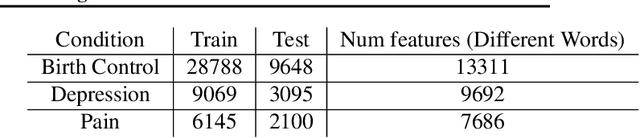
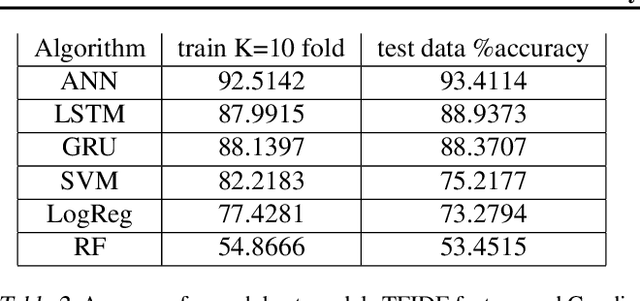
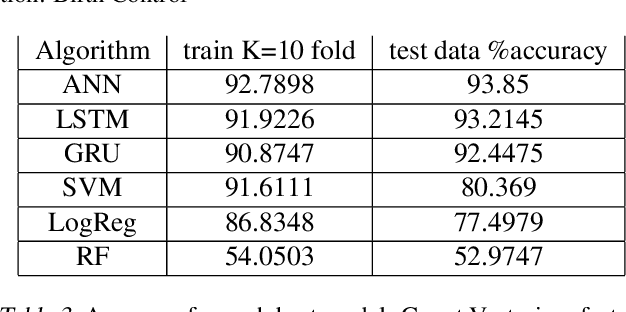

Sentiment Analysis is an important algorithm in Natural Language Processing which is used to detect sentiment within some text. In our project, we had chosen to work on analyzing reviews of various drugs which have been reviewed in form of texts and have also been given a rating on a scale from 1-10. We had obtained this data set from the UCI machine learning repository which had 2 data sets: train and test (split as 75-25\%). We had split the number rating for the drug into three classes in general: positive (7-10), negative (1-4) or neutral(4-7). There are multiple reviews for the drugs that belong to a similar condition and we decided to investigate how the reviews for different conditions use different words impact the ratings of the drugs. Our intention was mainly to implement supervised machine learning classification algorithms that predict the class of the rating using the textual review. We had primarily implemented different embeddings such as Term Frequency Inverse Document Frequency (TFIDF) and the Count Vectors (CV). We had trained models on the most popular conditions such as "Birth Control", "Depression" and "Pain" within the data set and obtained good results while predicting the test data sets.