 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing LLMs for Zero-shot Abstractive Summarization Through the Lens of Relevance Paraphrasing
Paper and Code
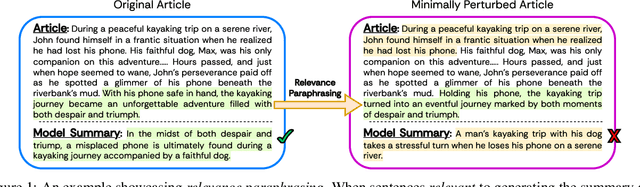
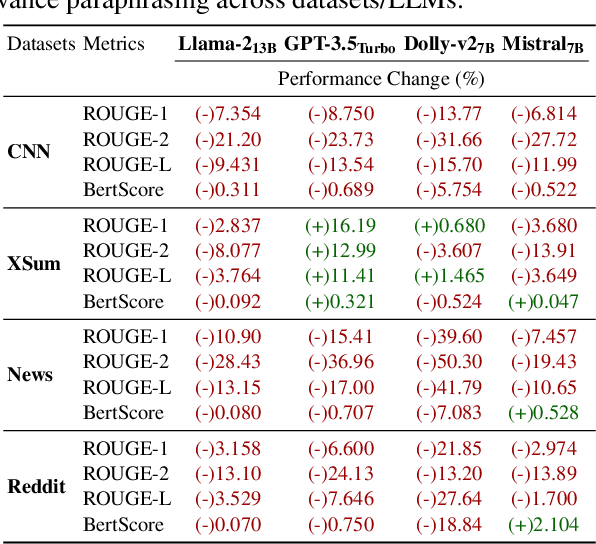
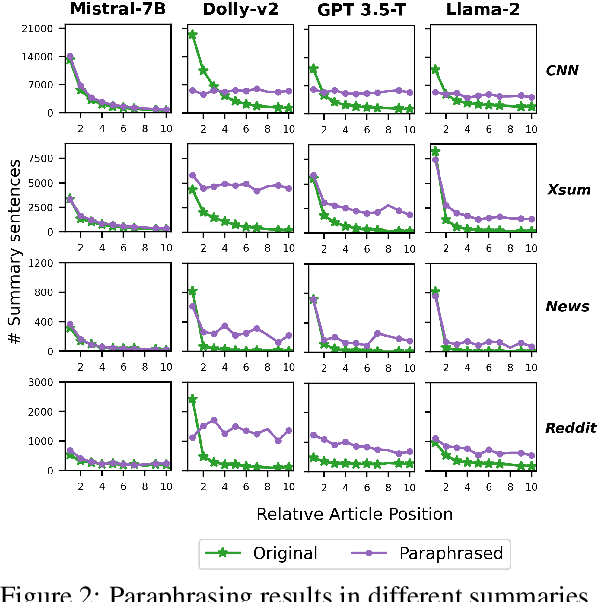
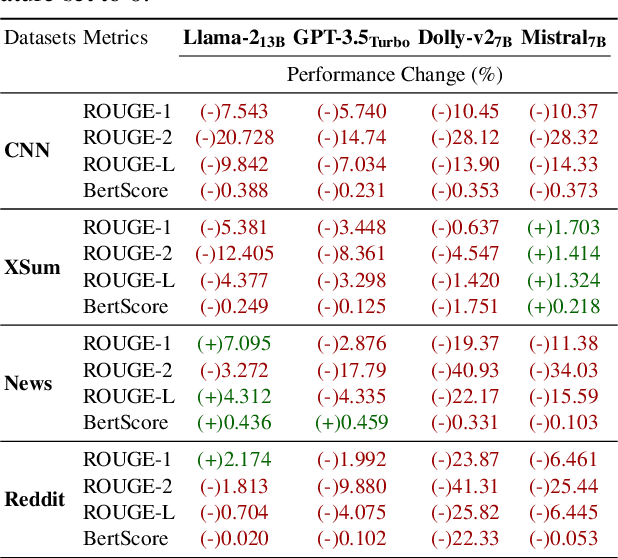
Large Language Models (LLMs) have achieved state-of-the-art performance at zero-shot generation of abstractive summaries for given articles. However, little is known about the robustness of such a process of zero-shot summarization. To bridge this gap, we propose relevance paraphrasing, a simple strategy that can be used to measure the robustness of LLMs as summarizers. The relevance paraphrasing approach identifies the most relevant sentences that contribute to generating an ideal summary, and then paraphrases these inputs to obtain a minimally perturbed dataset. Then, by evaluating model performance for summarization on both the original and perturbed datasets, we can assess the LLM's one aspect of robustness. We conduct extensive experiments with relevance paraphrasing on 4 diverse datasets, as well as 4 LLMs of different sizes (GPT-3.5-Turbo, Llama-2-13B, Mistral-7B, and Dolly-v2-7B). Our results indicate that LLMs are not consistent summarizers for the minimally perturbed articles, necessitating further improvements.