 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRIEDA: Benchmarking Multi-Step Cartographic Reasoning in Vision-Language Models
Dec 08, 2025Cartographic reasoning is the skill of interpreting geographic relationships by aligning legends, map scales, compass directions, map texts, and geometries across one or more map images. Although essential as a concrete cognitive capability and for critical tasks such as disaster response and urban planning, it remains largely unevaluated. Building on progress in chart and infographic understanding, recent large vision language model studies on map visual question-answering often treat maps as a special case of charts. In contrast, map VQA demands comprehension of layered symbology (e.g., symbols, geometries, and text labels) as well as spatial relations tied to orientation and distance that often span multiple maps and are not captured by chart-style evaluations. To address this gap, we introduce FRIEDA, a benchmark for testing complex open-ended cartographic reasoning in LVLMs. FRIEDA sources real map images from documents and reports in various domains and geographical areas. Following classifications in Geographic Information System (GIS) literature, FRIEDA targets all three categories of spatial relations: topological (border, equal, intersect, within), metric (distance), and directional (orientation). All questions require multi-step inference, and many require cross-map grounding and reasoning. We evaluate eleven state-of-the-art LVLMs under two settings: (1) the direct setting, where we provide the maps relevant to the question, and (2) the contextual setting, where the model may have to identify the maps relevant to the question before reasoning. Even the strongest models, Gemini-2.5-Pro and GPT-5-Think, achieve only 38.20% and 37.20% accuracy, respectively, far below human performance of 84.87%. These results reveal a persistent gap in multi-step cartographic reasoning, positioning FRIEDA as a rigorous benchmark to drive progress on spatial intelligence in LVLMs.
LayerIF: Estimating Layer Quality for Large Language Models using Influence Functions
May 27, 2025Pretrained Large Language Models (LLMs) achieve strong performance across a wide range of tasks, yet exhibit substantial variability in the various layers' training quality with respect to specific downstream applications, limiting their downstream performance.It is therefore critical to estimate layer-wise training quality in a manner that accounts for both model architecture and training data. However, existing approaches predominantly rely on model-centric heuristics (such as spectral statistics, outlier detection, or uniform allocation) while overlooking the influence of data. To address these limitations, we propose LayerIF, a data-driven framework that leverages Influence Functions to quantify the training quality of individual layers in a principled and task-sensitive manner. By isolating each layer's gradients and measuring the sensitivity of the validation loss to training examples by computing layer-wise influences, we derive data-driven estimates of layer importance. Notably, our method produces task-specific layer importance estimates for the same LLM, revealing how layers specialize for different test-time evaluation tasks. We demonstrate the utility of our scores by leveraging them for two downstream applications: (a) expert allocation in LoRA-MoE architectures and (b) layer-wise sparsity distribution for LLM pruning. Experiments across multiple LLM architectures demonstrate that our model-agnostic, influence-guided allocation leads to consistent gains in task performance.
Unraveling Indirect In-Context Learning Using Influence Functions
Jan 01, 2025



This work introduces a novel paradigm for generalized In-Context Learning (ICL), termed Indirect In-Context Learning. In Indirect ICL, we explore demonstration selection strategies tailored for two distinct real-world scenarios: Mixture of Tasks and Noisy Demonstrations. We systematically evaluate the effectiveness of Influence Functions (IFs) as a selection tool for these settings, highlighting the potential for IFs to better capture the informativeness of examples within the demonstration pool. For the Mixture of Tasks setting, demonstrations are drawn from 28 diverse tasks, including MMLU, BigBench, StrategyQA, and CommonsenseQA. We demonstrate that combining BertScore-Recall (BSR) with an IF surrogate model can significantly improve performance, leading to average absolute accuracy gains of 0.37\% and 1.45\% for 3-shot and 5-shot setups when compared to traditional ICL metrics. In the Noisy Demonstrations setting, we examine scenarios where demonstrations might be mislabeled. Our experiments show that reweighting traditional ICL selectors (BSR and Cosine Similarity) with IF-based selectors boosts accuracy by an average of 2.90\% for Cosine Similarity and 2.94\% for BSR on noisy GLUE benchmarks. In sum, we propose a robust framework for demonstration selection that generalizes beyond traditional ICL, offering valuable insights into the role of IFs for Indirect ICL.
Assessing LLMs for Zero-shot Abstractive Summarization Through the Lens of Relevance Paraphrasing
Jun 06, 2024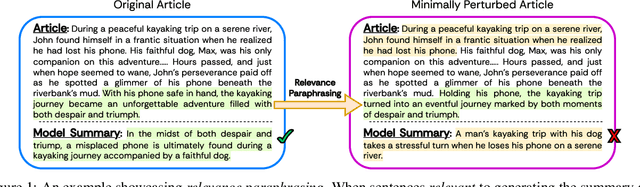
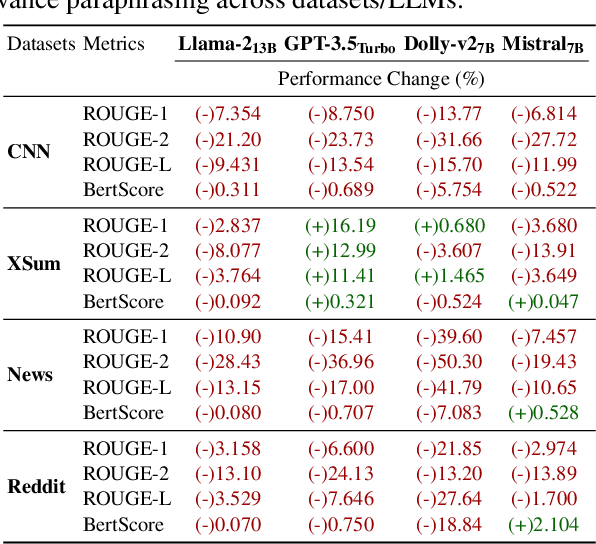
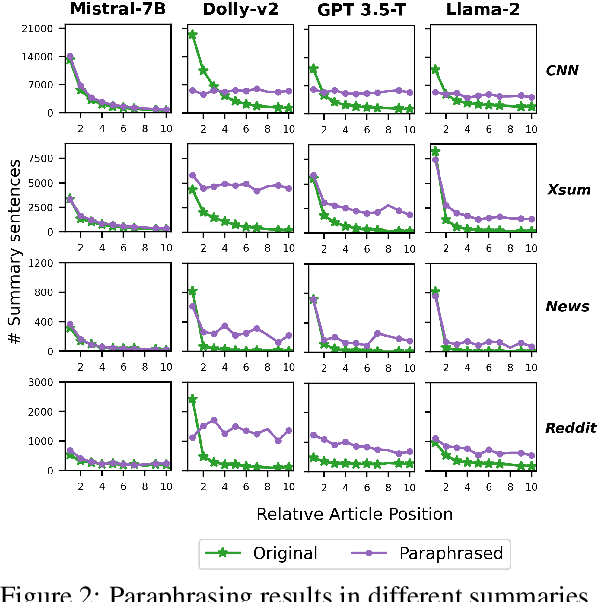
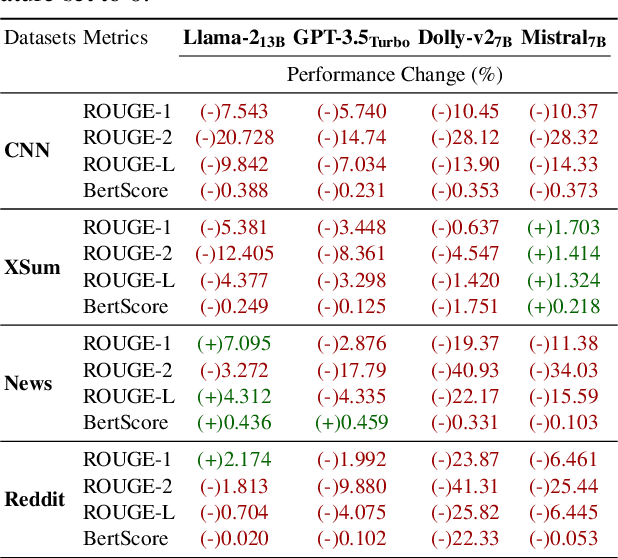
Large Language Models (LLMs) have achieved state-of-the-art performance at zero-shot generation of abstractive summaries for given articles. However, little is known about the robustness of such a process of zero-shot summarization. To bridge this gap, we propose relevance paraphrasing, a simple strategy that can be used to measure the robustness of LLMs as summarizers. The relevance paraphrasing approach identifies the most relevant sentences that contribute to generating an ideal summary, and then paraphrases these inputs to obtain a minimally perturbed dataset. Then, by evaluating model performance for summarization on both the original and perturbed datasets, we can assess the LLM's one aspect of robustness. We conduct extensive experiments with relevance paraphrasing on 4 diverse datasets, as well as 4 LLMs of different sizes (GPT-3.5-Turbo, Llama-2-13B, Mistral-7B, and Dolly-v2-7B). Our results indicate that LLMs are not consistent summarizers for the minimally perturbed articles, necessitating further improvements.
Incentivizing News Consumption on Social Media Platforms Using Large Language Models and Realistic Bot Accounts
Mar 30, 2024
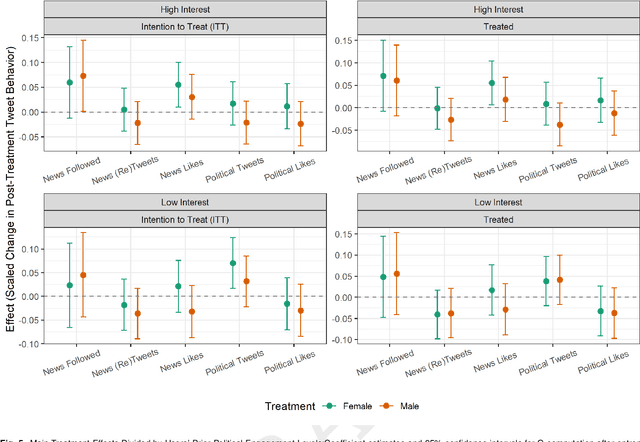
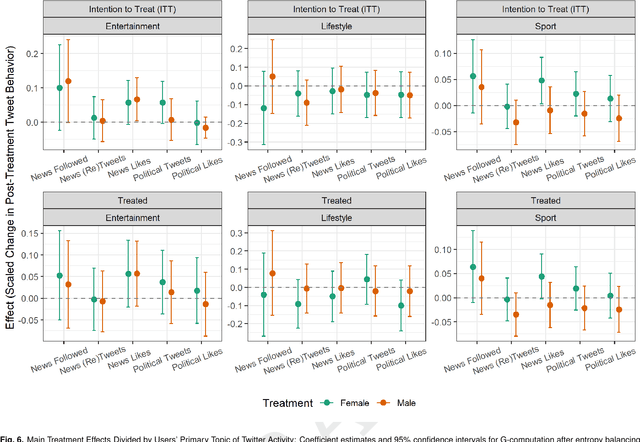
Polarization, declining trust, and wavering support for democratic norms are pressing threats to U.S. democracy. Exposure to verified and quality news may lower individual susceptibility to these threats and make citizens more resilient to misinformation, populism, and hyperpartisan rhetoric. This project examines how to enhance users' exposure to and engagement with verified and ideologically balanced news in an ecologically valid setting. We rely on a large-scale two-week long field experiment (from 1/19/2023 to 2/3/2023) on 28,457 Twitter users. We created 28 bots utilizing GPT-2 that replied to users tweeting about sports, entertainment, or lifestyle with a contextual reply containing two hardcoded elements: a URL to the topic-relevant section of quality news organization and an encouragement to follow its Twitter account. To further test differential effects by gender of the bots, treated users were randomly assigned to receive responses by bots presented as female or male. We examine whether our over-time intervention enhances the following of news media organization, the sharing and the liking of news content and the tweeting about politics and the liking of political content. We find that the treated users followed more news accounts and the users in the female bot treatment were more likely to like news content than the control. Most of these results, however, were small in magnitude and confined to the already politically interested Twitter users, as indicated by their pre-treatment tweeting about politics. These findings have implications for social media and news organizations, and also offer direction for future work on how Large Language Models and other computational interventions can effectively enhance individual on-platform engagement with quality news and public affairs.
Revisiting Zero-Shot Abstractive Summarization in the Era of Large Language Models from the Perspective of Position Bias
Jan 03, 2024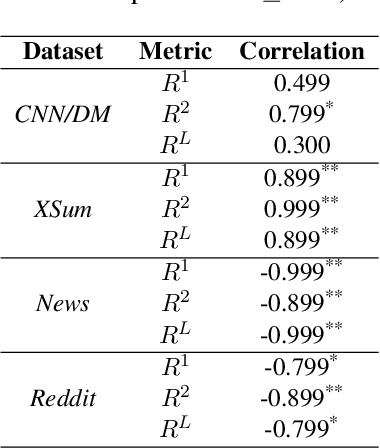
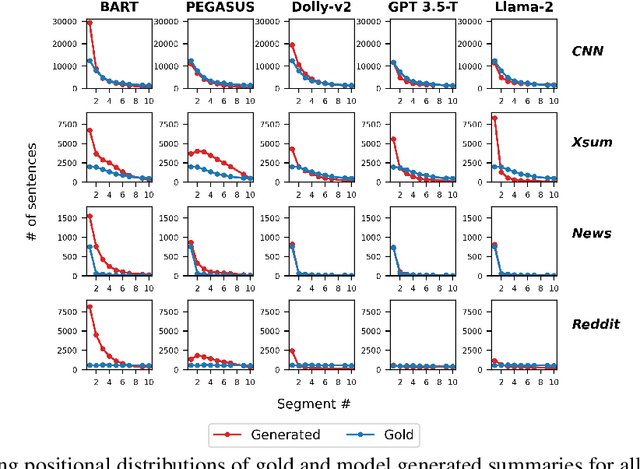
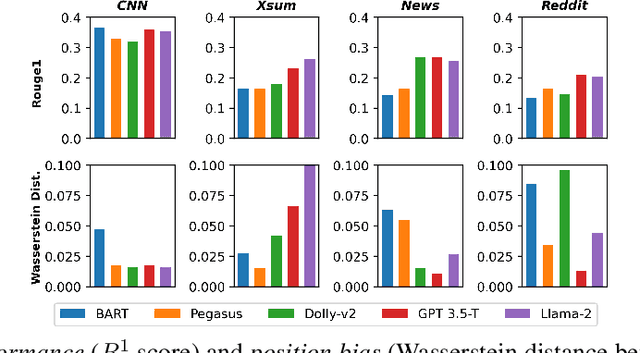
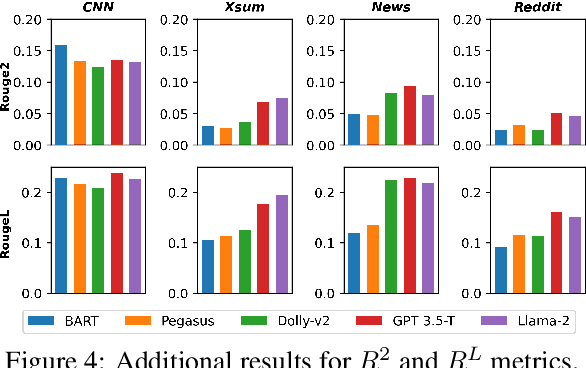
We characterize and study zero-shot abstractive summarization in Large Language Models (LLMs) by measuring position bias, which we propose as a general formulation of the more restrictive lead bias phenomenon studied previously in the literature. Position bias captures the tendency of a model unfairly prioritizing information from certain parts of the input text over others, leading to undesirable behavior. Through numerous experiments on four diverse real-world datasets, we study position bias in multiple LLM models such as GPT 3.5-Turbo, Llama-2, and Dolly-v2, as well as state-of-the-art pretrained encoder-decoder abstractive summarization models such as Pegasus and BART. Our findings lead to novel insights and discussion on performance and position bias of models for zero-shot summarization tasks.