 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Zero-Shot Abstractive Summarization in the Era of Large Language Models from the Perspective of Position Bias
Paper and Code
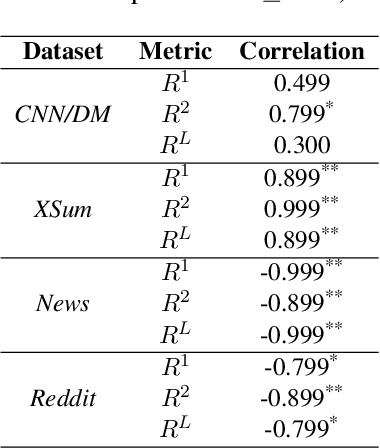
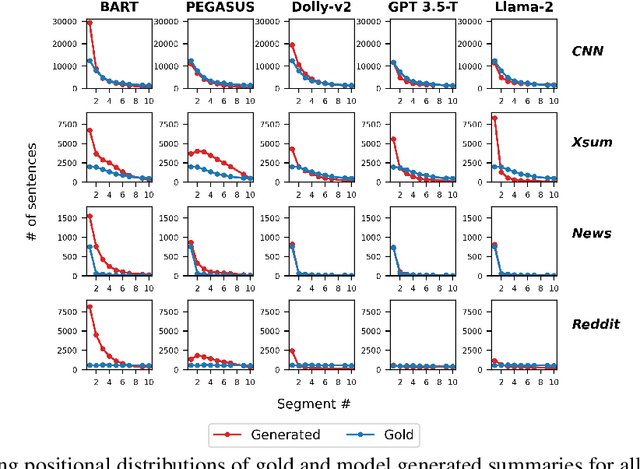
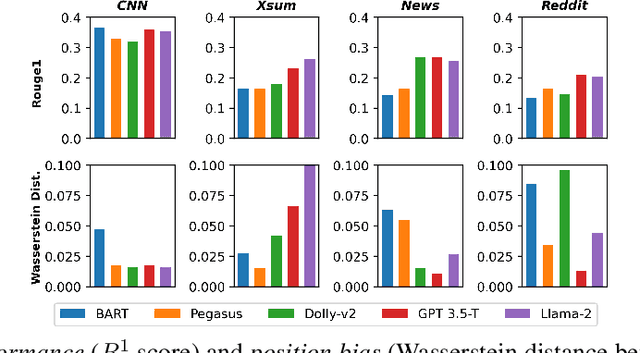
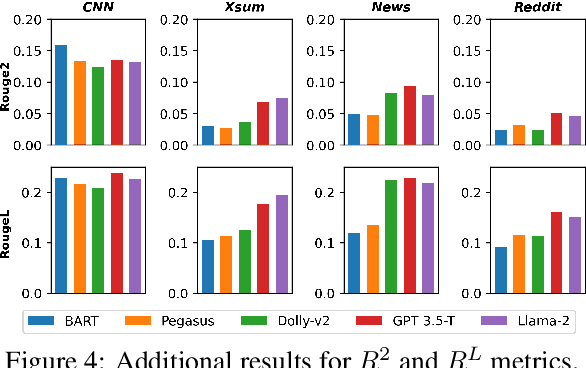
We characterize and study zero-shot abstractive summarization in Large Language Models (LLMs) by measuring position bias, which we propose as a general formulation of the more restrictive lead bias phenomenon studied previously in the literature. Position bias captures the tendency of a model unfairly prioritizing information from certain parts of the input text over others, leading to undesirable behavior. Through numerous experiments on four diverse real-world datasets, we study position bias in multiple LLM models such as GPT 3.5-Turbo, Llama-2, and Dolly-v2, as well as state-of-the-art pretrained encoder-decoder abstractive summarization models such as Pegasus and BART. Our findings lead to novel insights and discussion on performance and position bias of models for zero-shot summarization tasks.