 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Natural Language for Multi-agent Decision-Making with Multi-agentic LLMs
Aug 10, 2025Language is a ubiquitous tool that is foundational to reasoning and collaboration, ranging from everyday interactions to sophisticated problem-solving tasks. The establishment of a common language can serve as a powerful asset in ensuring clear communication and understanding amongst agents, facilitating desired coordination and strategies. In this work, we extend the capabilities of large language models (LLMs) by integrating them with advancements in multi-agent decision-making algorithms. We propose a systematic framework for the design of multi-agentic large language models (LLMs), focusing on key integration practices. These include advanced prompt engineering techniques, the development of effective memory architectures, multi-modal information processing, and alignment strategies through fine-tuning algorithms. We evaluate these design choices through extensive ablation studies on classic game settings with significant underlying social dilemmas and game-theoretic considerations.
Representation Learning For Efficient Deep Multi-Agent Reinforcement Learning
Jun 05, 2024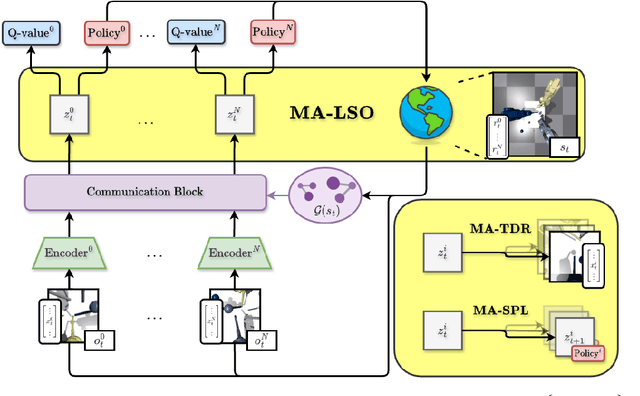
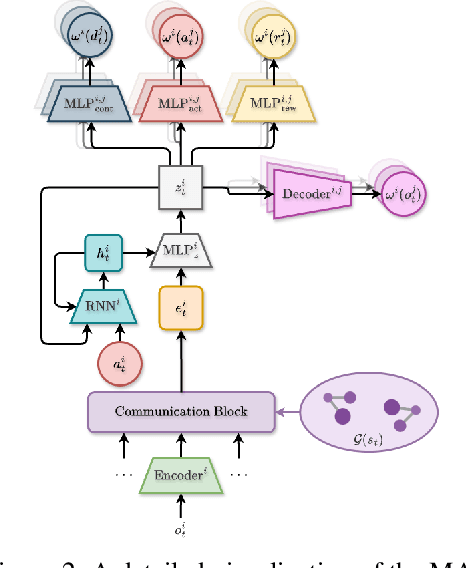
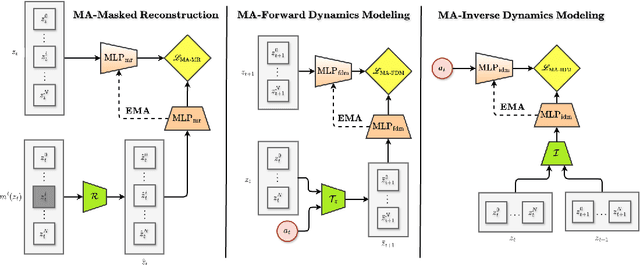
Sample efficiency remains a key challenge in multi-agent reinforcement learning (MARL). A promising approach is to learn a meaningful latent representation space through auxiliary learning objectives alongside the MARL objective to aid in learning a successful control policy. In our work, we present MAPO-LSO (Multi-Agent Policy Optimization with Latent Space Optimization) which applies a form of comprehensive representation learning devised to supplement MARL training. Specifically, MAPO-LSO proposes a multi-agent extension of transition dynamics reconstruction and self-predictive learning that constructs a latent state optimization scheme that can be trivially extended to current state-of-the-art MARL algorithms. Empirical results demonstrate MAPO-LSO to show notable improvements in sample efficiency and learning performance compared to its vanilla MARL counterpart without any additional MARL hyperparameter tuning on a diverse suite of MARL tasks.
Multi-agent Reinforcement Learning: A Comprehensive Survey
Dec 15, 2023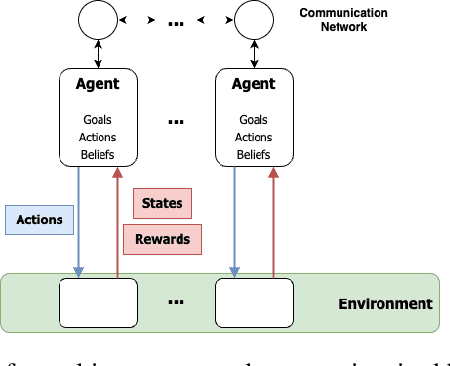
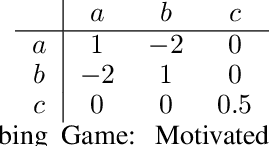
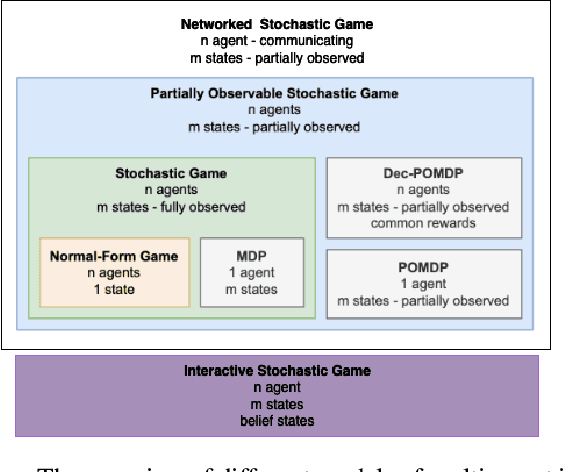
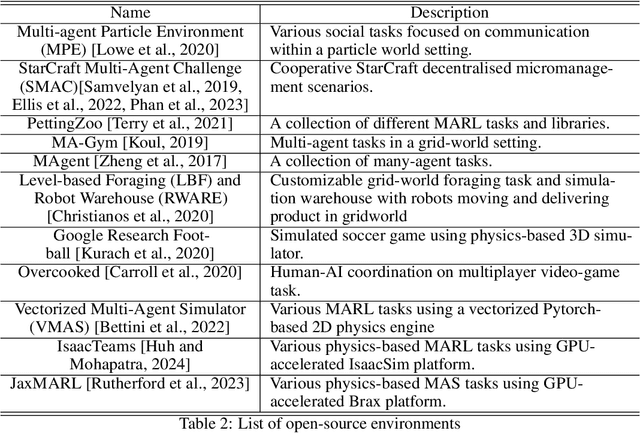
The prevalence of multi-agent applications pervades various interconnected systems in our everyday lives. Despite their ubiquity, the integration and development of intelligent decision-making agents in a shared environment pose challenges to their effective implementation. This survey delves into the domain of multi-agent systems (MAS), placing a specific emphasis on unraveling the intricacies of learning optimal control within the MAS framework, commonly known as multi-agent reinforcement learning (MARL). The objective of this survey is to provide comprehensive insights into various dimensions of MAS, shedding light on myriad opportunities while highlighting the inherent challenges that accompany multi-agent applications. We hope not only to contribute to a deeper understanding of the MAS landscape but also to provide valuable perspectives for both researchers and practitioners. By doing so, we aim to facilitate informed exploration and foster development within the dynamic realm of MAS, recognizing the need for adaptive strategies and continuous evolution in addressing emerging complexities in MARL.
Decentralized Multi-agent Filtering
Jan 21, 2023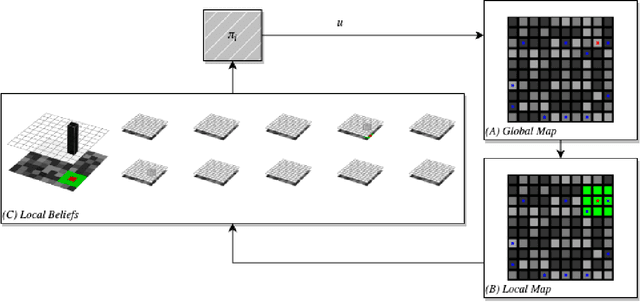

This paper addresses the considerations that comes along with adopting decentralized communication for multi-agent localization applications in discrete state spaces. In this framework, we extend the original formulation of the Bayes filter, a foundational probabilistic tool for discrete state estimation, by appending a step of greedy belief sharing as a method to propagate information and improve local estimates' posteriors. We apply our work in a model-based multi-agent grid-world setting, where each agent maintains a belief distribution for every agents' state. Our results affirm the utility of our proposed extensions for decentralized collaborative tasks. The code base for this work is available in the following repo
Mix and Mask Actor-Critic Methods
Jun 24, 2021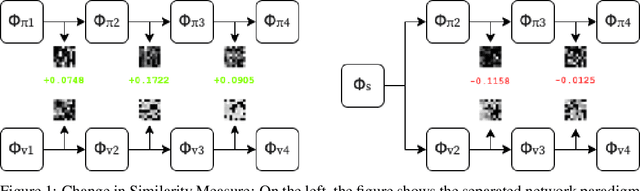
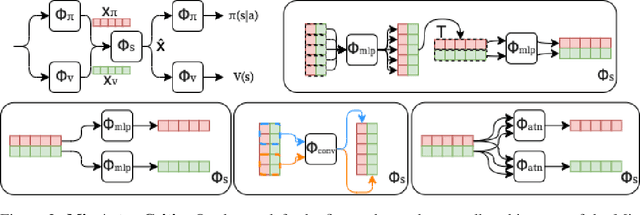
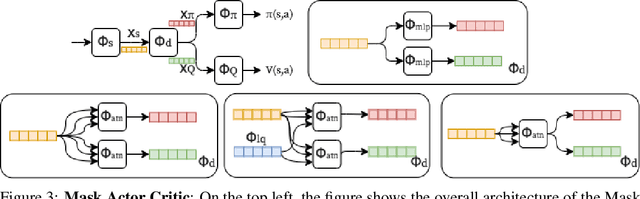
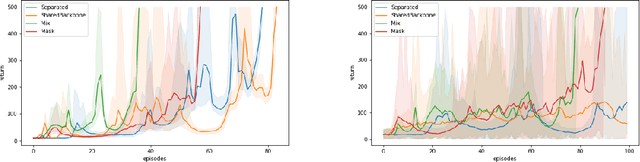
Shared feature spaces for actor-critic methods aims to capture generalized latent representations to be used by the policy and value function with the hopes for a more stable and sample-efficient optimization. However, such a paradigm present a number of challenges in practice, as parameters generating a shared representation must learn off two distinct objectives, resulting in competing updates and learning perturbations. In this paper, we present a novel feature-sharing framework to address these difficulties by introducing the mix and mask mechanisms and the distributional scalarization technique. These mechanisms behaves dynamically to couple and decouple connected latent features variably between the policy and value function, while the distributional scalarization standardizes the two objectives using a probabilistic standpoint. From our experimental results, we demonstrate significant performance improvements compared to alternative methods using separate networks and networks with a shared backbone.
Synthetic Embedding-based Data Generation Methods for Student Performance
Jan 03, 2021
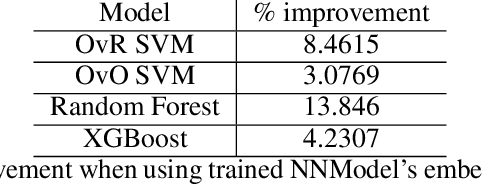
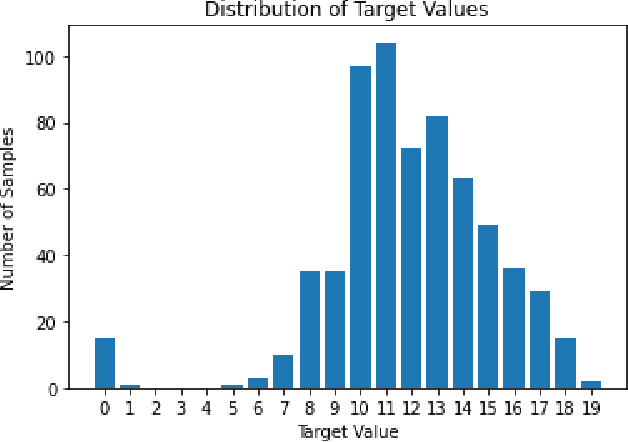
Given the inherent class imbalance issue within student performance datasets, samples belonging to the edges of the target class distribution pose a challenge for predictive machine learning algorithms to learn. In this paper, we introduce a general framework for synthetic embedding-based data generation (SEDG), a search-based approach to generate new synthetic samples using embeddings to correct the detriment effects of class imbalances optimally. We compare the SEDG framework to past synthetic data generation methods, including deep generative models, and traditional sampling methods. In our results, we find SEDG to outperform the traditional re-sampling methods for deep neural networks and perform competitively for common machine learning classifiers on the student performance task in several standard performance metrics.
Hierarchical BiGraph Neural Network as Recommendation Systems
Jul 27, 2020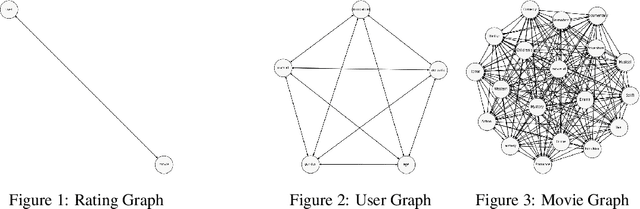
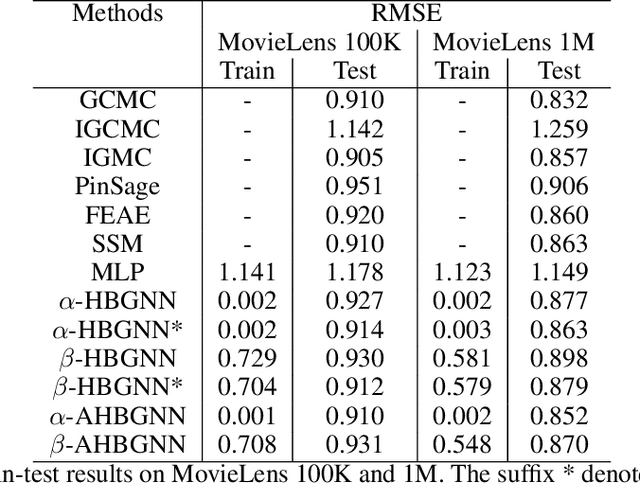

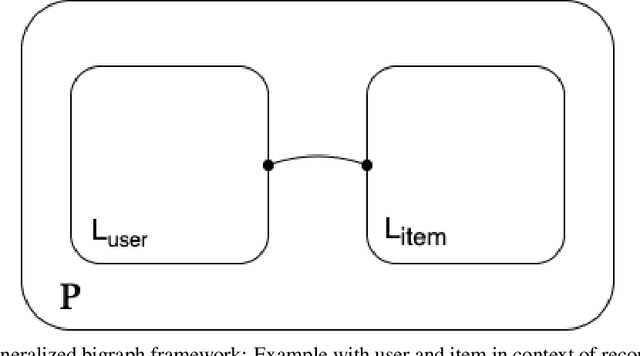
Graph neural networks emerge as a promising modeling method for applications dealing with datasets that are best represented in the graph domain. In specific, developing recommendation systems often require addressing sparse structured data which often lacks the feature richness in either the user and/or item side and requires processing within the correct context for optimal performance. These datasets intuitively can be mapped to and represented as networks or graphs. In this paper, we propose the Hierarchical BiGraph Neural Network (HBGNN), a hierarchical approach of using GNNs as recommendation systems and structuring the user-item features using a bigraph framework. Our experimental results show competitive performance with current recommendation system methods and transferability.
Greedy Bandits with Sampled Context
Jul 27, 2020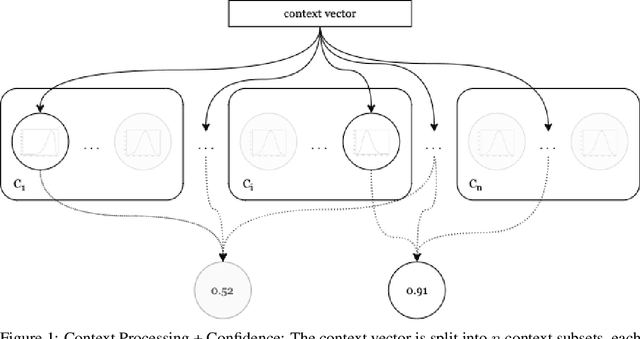
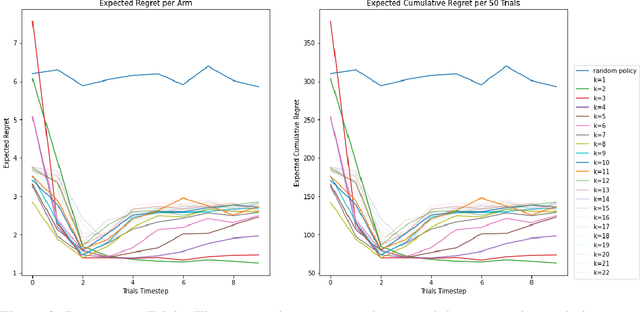
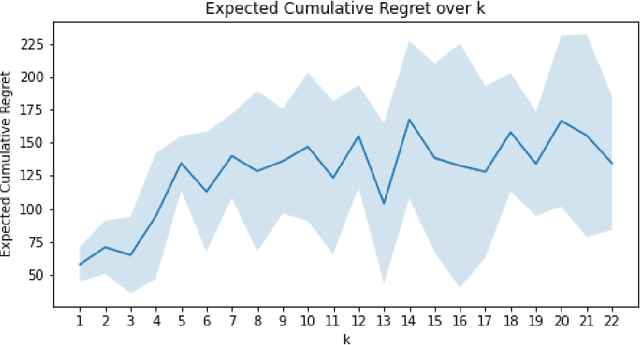
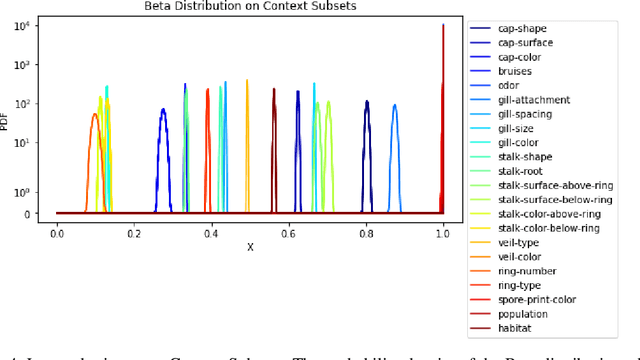
Bayesian strategies for contextual bandits have proved promising in single-state reinforcement learning tasks by modeling uncertainty using context information from the environment. In this paper, we propose Greedy Bandits with Sampled Context (GB-SC), a method for contextual multi-armed bandits to develop the prior from the context information using Thompson Sampling, and arm selection using an epsilon-greedy policy. The framework GB-SC allows for evaluation of context-reward dependency, as well as providing robustness for partially observable context vectors by leveraging the prior developed. Our experimental results show competitive performance on the Mushroom environment in terms of expected regret and expected cumulative regret, as well as insights on how each context subset affects decision-making.
Generative Multi-Stream Architecture For American Sign Language Recognition
Mar 09, 2020


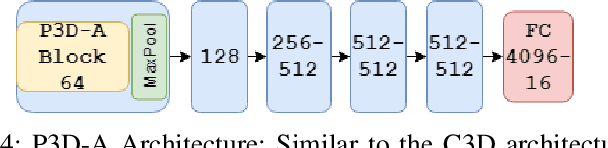
With advancements in deep model architectures, tasks in computer vision can reach optimal convergence provided proper data preprocessing and model parameter initialization. However, training on datasets with low feature-richness for complex applications limit and detriment optimal convergence below human performance. In past works, researchers have provided external sources of complementary data at the cost of supplementary hardware, which are fed in streams to counteract this limitation and boost performance. We propose a generative multi-stream architecture, eliminating the need for additional hardware with the intent to improve feature richness without risking impracticability. We also introduce the compact spatio-temporal residual block to the standard 3-dimensional convolutional model, C3D. Our rC3D model performs comparatively to the top C3D residual variant architecture, the pseudo-3D model, on the FASL-RGB dataset. Our methods have achieved 95.62% validation accuracy with a variance of 1.42% from training, outperforming past models by 0.45% in validation accuracy and 5.53% in variance.