 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Multi-Stream Architecture For American Sign Language Recognition
Mar 09, 2020


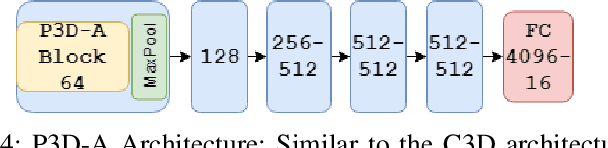
With advancements in deep model architectures, tasks in computer vision can reach optimal convergence provided proper data preprocessing and model parameter initialization. However, training on datasets with low feature-richness for complex applications limit and detriment optimal convergence below human performance. In past works, researchers have provided external sources of complementary data at the cost of supplementary hardware, which are fed in streams to counteract this limitation and boost performance. We propose a generative multi-stream architecture, eliminating the need for additional hardware with the intent to improve feature richness without risking impracticability. We also introduce the compact spatio-temporal residual block to the standard 3-dimensional convolutional model, C3D. Our rC3D model performs comparatively to the top C3D residual variant architecture, the pseudo-3D model, on the FASL-RGB dataset. Our methods have achieved 95.62% validation accuracy with a variance of 1.42% from training, outperforming past models by 0.45% in validation accuracy and 5.53% in variance.