 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalutary Labeling with Zero Human Annotation
May 27, 2024Active learning strategically selects informative unlabeled data points and queries their ground truth labels for model training. The prevailing assumption underlying this machine learning paradigm is that acquiring these ground truth labels will optimally enhance model performance. However, this assumption may not always hold true or maximize learning capacity, particularly considering the costly labor annotations required for ground truth labels. In contrast to traditional ground truth labeling, this paper proposes salutary labeling, which automatically assigns the most beneficial labels to the most informative samples without human annotation. Specifically, we utilize the influence function, a tool for estimating sample influence, to select newly added samples and assign their salutary labels by choosing the category that maximizes their positive influence. This process eliminates the need for human annotation. Extensive experiments conducted on nine benchmark datasets demonstrate the superior performance of our salutary labeling approach over traditional active learning strategies. Additionally, we provide several in-depth explorations and practical applications of large language model (LLM) fine-tuning.
Visualizing Transferred Knowledge: An Interpretive Model of Unsupervised Domain Adaptation
Mar 04, 2023Many research efforts have been committed to unsupervised domain adaptation (DA) problems that transfer knowledge learned from a labeled source domain to an unlabeled target domain. Various DA methods have achieved remarkable results recently in terms of predicting ability, which implies the effectiveness of the aforementioned knowledge transferring. However, state-of-the-art methods rarely probe deeper into the transferred mechanism, leaving the true essence of such knowledge obscure. Recognizing its importance in the adaptation process, we propose an interpretive model of unsupervised domain adaptation, as the first attempt to visually unveil the mystery of transferred knowledge. Adapting the existing concept of the prototype from visual image interpretation to the DA task, our model similarly extracts shared information from the domain-invariant representations as prototype vectors. Furthermore, we extend the current prototype method with our novel prediction calibration and knowledge fidelity preservation modules, to orientate the learned prototypes to the actual transferred knowledge. By visualizing these prototypes, our method not only provides an intuitive explanation for the base model's predictions but also unveils transfer knowledge by matching the image patches with the same semantics across both source and target domains. Comprehensive experiments and in-depth explorations demonstrate the efficacy of our method in understanding the transferred mechanism and its potential in downstream tasks including model diagnosis.
Learnable Visual Words for Interpretable Image Recognition
May 26, 2022
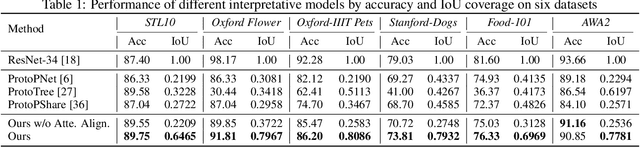


To interpret deep models' predictions, attention-based visual cues are widely used in addressing \textit{why} deep models make such predictions. Beyond that, the current research community becomes more interested in reasoning \textit{how} deep models make predictions, where some prototype-based methods employ interpretable representations with their corresponding visual cues to reveal the black-box mechanism of deep model behaviors. However, these pioneering attempts only either learn the category-specific prototypes and deteriorate their generalizing capacities, or demonstrate several illustrative examples without a quantitative evaluation of visual-based interpretability with further limitations on their practical usages. In this paper, we revisit the concept of visual words and propose the Learnable Visual Words (LVW) to interpret the model prediction behaviors with two novel modules: semantic visual words learning and dual fidelity preservation. The semantic visual words learning relaxes the category-specific constraint, enabling the general visual words shared across different categories. Beyond employing the visual words for prediction to align visual words with the base model, our dual fidelity preservation also includes the attention guided semantic alignment that encourages the learned visual words to focus on the same conceptual regions for prediction. Experiments on six visual benchmarks demonstrate the superior effectiveness of our proposed LVW in both accuracy and model interpretation over the state-of-the-art methods. Moreover, we elaborate on various in-depth analyses to further explore the learned visual words and the generalizability of our method for unseen categories.