 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Visual Words for Interpretable Image Recognition
Paper and Code

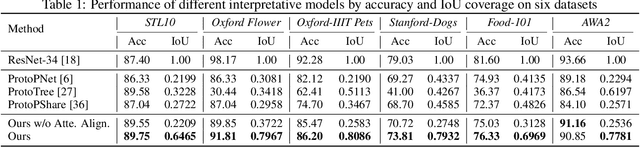


To interpret deep models' predictions, attention-based visual cues are widely used in addressing \textit{why} deep models make such predictions. Beyond that, the current research community becomes more interested in reasoning \textit{how} deep models make predictions, where some prototype-based methods employ interpretable representations with their corresponding visual cues to reveal the black-box mechanism of deep model behaviors. However, these pioneering attempts only either learn the category-specific prototypes and deteriorate their generalizing capacities, or demonstrate several illustrative examples without a quantitative evaluation of visual-based interpretability with further limitations on their practical usages. In this paper, we revisit the concept of visual words and propose the Learnable Visual Words (LVW) to interpret the model prediction behaviors with two novel modules: semantic visual words learning and dual fidelity preservation. The semantic visual words learning relaxes the category-specific constraint, enabling the general visual words shared across different categories. Beyond employing the visual words for prediction to align visual words with the base model, our dual fidelity preservation also includes the attention guided semantic alignment that encourages the learned visual words to focus on the same conceptual regions for prediction. Experiments on six visual benchmarks demonstrate the superior effectiveness of our proposed LVW in both accuracy and model interpretation over the state-of-the-art methods. Moreover, we elaborate on various in-depth analyses to further explore the learned visual words and the generalizability of our method for unseen categories.