 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Based Named Entity Recognition
Paper and Code
Aug 24, 2019
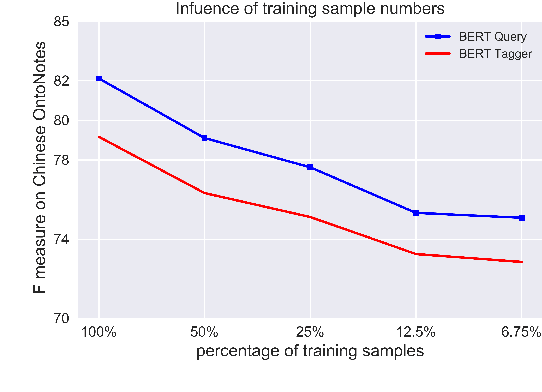
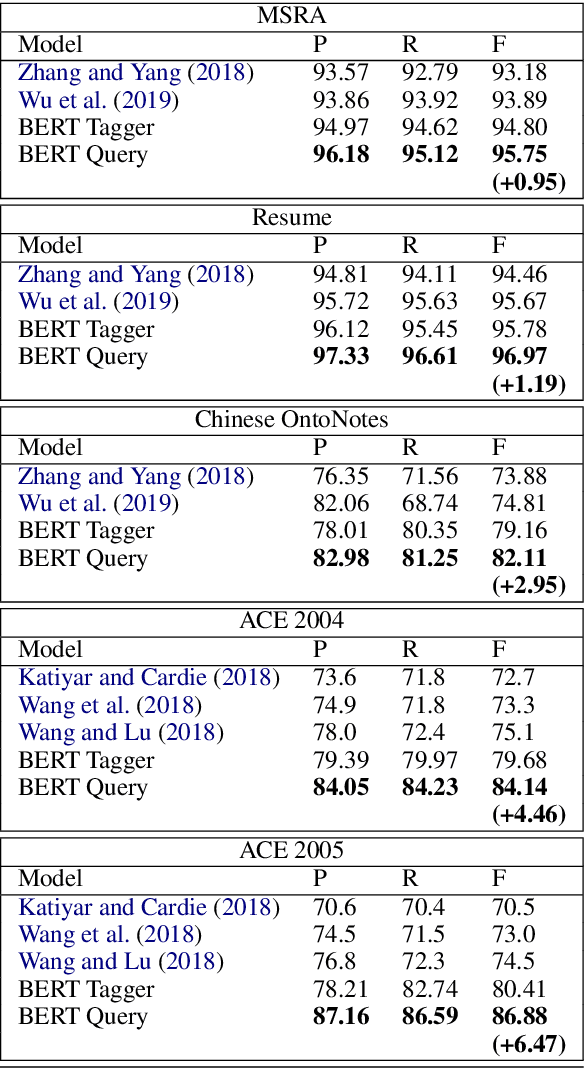
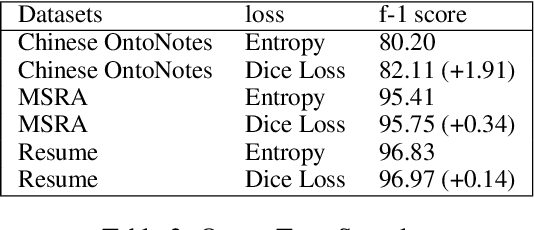
In this paper, we propose a new strategy for the task of named entity recognition (NER). We cast the task as a query-based machine reading comprehension task: e.g., the task of extracting entities with PER is formalized as answering the question of "which person is mentioned in the text ?". Such a strategy comes with the advantage that it solves the long-standing issue of handling overlapping or nested entities (the same token that participates in more than one entity categories) with sequence-labeling techniques for NER. Additionally, since the query encodes informative prior knowledge, this strategy facilitates the process of entity extraction, leading to better performances. We experiment the proposed model on five widely used NER datasets on English and Chinese, including MSRA, Resume, OntoNotes, ACE04 and ACE05. The proposed model sets new SOTA results on all of these datasets.