 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Semi-supervised Learning for Text Classification Under Large-Scale Pretraining
Paper and Code
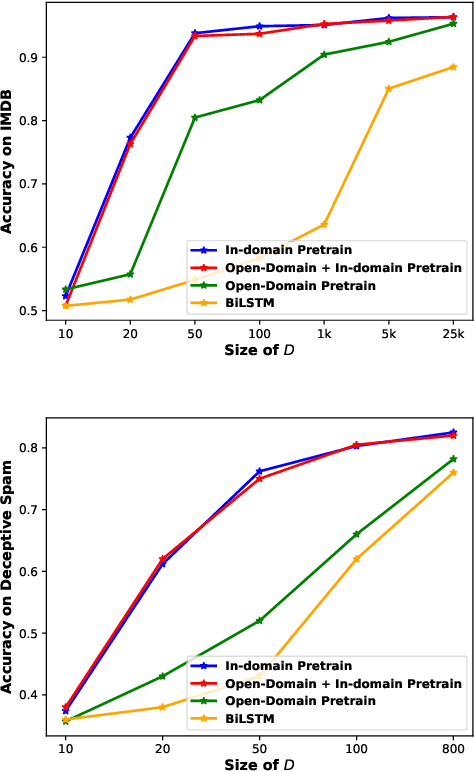
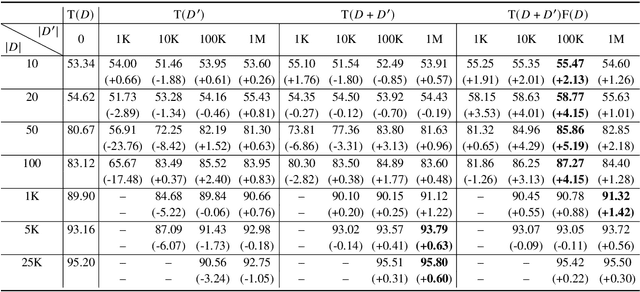
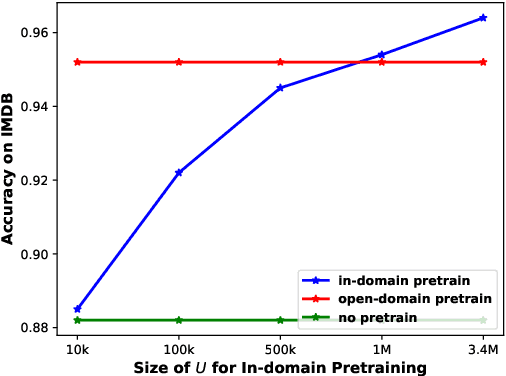

The goal of semi-supervised learning is to utilize the unlabeled, in-domain dataset U to improve models trained on the labeled dataset D. Under the context of large-scale language-model (LM) pretraining, how we can make the best use of U is poorly understood: is semi-supervised learning still beneficial with the presence of large-scale pretraining? should U be used for in-domain LM pretraining or pseudo-label generation? how should the pseudo-label based semi-supervised model be actually implemented? how different semi-supervised strategies affect performances regarding D of different sizes, U of different sizes, etc. In this paper, we conduct comprehensive studies on semi-supervised learning in the task of text classification under the context of large-scale LM pretraining. Our studies shed important lights on the behavior of semi-supervised learning methods: (1) with the presence of in-domain pretraining LM on U, open-domain LM pretraining is unnecessary; (2) both the in-domain pretraining strategy and the pseudo-label based strategy introduce significant performance boosts, with the former performing better with larger U, the latter performing better with smaller U, and the combination leading to the largest performance boost; (3) self-training (pretraining first on pseudo labels D' and then fine-tuning on D) yields better performances when D is small, while joint training on the combination of pseudo labels D' and the original dataset D yields better performances when D is large. Using semi-supervised learning strategies, we are able to achieve a performance of around 93.8% accuracy with only 50 training data points on the IMDB dataset, and a competitive performance of 96.6% with the full IMDB dataset. Our work marks an initial step in understanding the behavior of semi-supervised learning models under the context of large-scale pretraining.