 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Self-supervised Trojan Attacks
Paper and Code
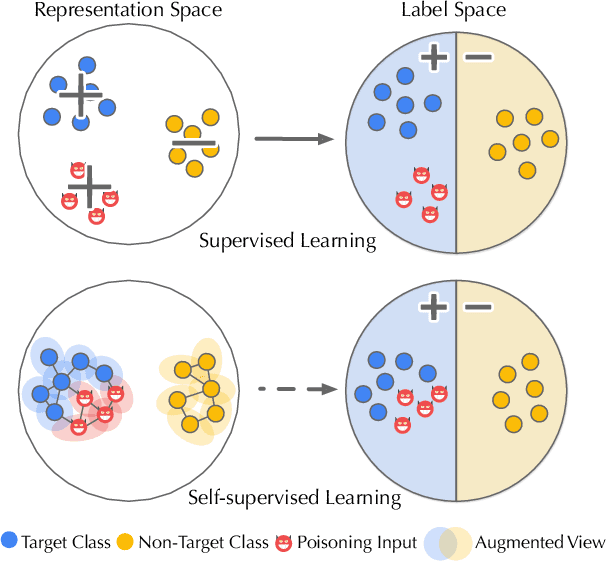
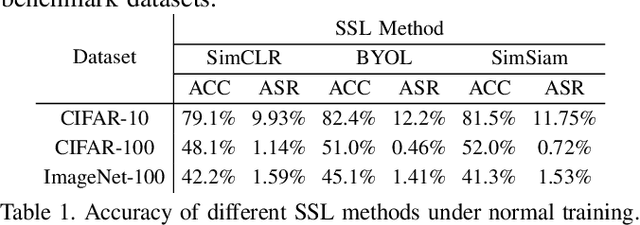
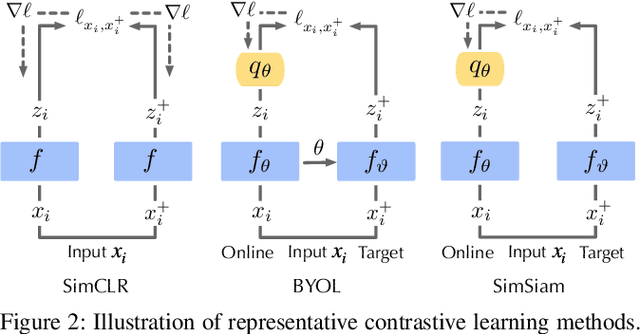
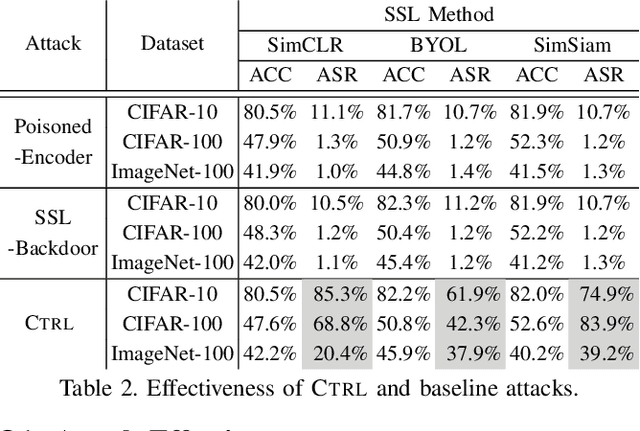
As an emerging machine learning paradigm, self-supervised learning (SSL) is able to learn high-quality representations for complex data without data labels. Prior work shows that, besides obviating the reliance on labeling, SSL also benefits adversarial robustness by making it more challenging for the adversary to manipulate model prediction. However, whether this robustness benefit generalizes to other types of attacks remains an open question. We explore this question in the context of trojan attacks by showing that SSL is comparably vulnerable as supervised learning to trojan attacks. Specifically, we design and evaluate CTRL, an extremely simple self-supervised trojan attack. By polluting a tiny fraction of training data (less than 1%) with indistinguishable poisoning samples, CTRL causes any trigger-embedded input to be misclassified to the adversary's desired class with a high probability (over 99%) at inference. More importantly, through the lens of CTRL, we study the mechanisms underlying self-supervised trojan attacks. With both empirical and analytical evidence, we reveal that the representation invariance property of SSL, which benefits adversarial robustness, may also be the very reason making SSL highly vulnerable to trojan attacks. We further discuss the fundamental challenges to defending against self-supervised trojan attacks, pointing to promising directions for future research.