 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMzansiText and MzansiLM: An Open Corpus and Decoder-Only Language Model for South African Languages
Mar 21, 2026Decoder-only language models can be adapted to diverse tasks through instruction finetuning, but the extent to which this generalizes at small scale for low-resource languages remains unclear. We focus on the languages of South Africa, where we are not aware of a publicly available decoder-only model that explicitly targets all eleven official written languages, nine of which are low-resource. We introduce MzansiText, a curated multilingual pretraining corpus with a reproducible filtering pipeline, and MzansiLM, a 125M-parameter language model trained from scratch. We evaluate MzansiLM on natural language understanding and generation using three adaptation regimes: monolingual task-specific finetuning, multilingual task-specific finetuning, and general multi-task instruction finetuning. Monolingual task-specific finetuning achieves strong performance on data-to-text generation, reaching 20.65 BLEU on isiXhosa and competing with encoder-decoder baselines over ten times larger. Multilingual task-specific finetuning benefits closely related languages on topic classification, achieving 78.5% macro-F1 on isiXhosa news classification. While MzansiLM adapts effectively to supervised NLU and NLG tasks, few-shot reasoning remains challenging at this model size, with performance near chance even for much larger decoder-only models. We release MzansiText and MzansiLM to provide a reproducible decoder-only baseline and clear guidance on adaptation strategies for South African languages at small scale.
The Learning Dynamics of Subword Segmentation for Morphologically Diverse Languages
Nov 19, 2025Subword segmentation is typically applied in preprocessing and stays fixed during training. Alternatively, it can be learned during training to optimise the training objective. In this paper we study the learning dynamics of subword segmentation: if a language model can dynamically optimise tokenisation, how do its subwords evolve during pretraining and finetuning? To explore this, we extend the subword segmental language model (SSLM), a framework for learning subwords during training, to support pretraining and finetuning. We train models for three typologically diverse languages to study learning dynamics across the morphological spectrum: Isi-Xhosa is conjunctive (long word forms composed of many morphemes), Setswana is disjunctive (morphemes written as separate words), and English represents a typological middle ground. We analyse subword dynamics from a linguistic perspective, tracking morphology, productivity, and fertility. We identify four stages of subword learning, with the morphologically complex isi-Xhosa exhibiting greater instability. During finetuning, subword boundaries shift to become finer-grained. Lastly, we show that learnable subwords offers a promising approach to improve text generation and cross-lingual transfer for low-resource, morphologically complex languages.
A Systematic Analysis of Subwords and Cross-Lingual Transfer in Multilingual Translation
Mar 29, 2024



Multilingual modelling can improve machine translation for low-resource languages, partly through shared subword representations. This paper studies the role of subword segmentation in cross-lingual transfer. We systematically compare the efficacy of several subword methods in promoting synergy and preventing interference across different linguistic typologies. Our findings show that subword regularisation boosts synergy in multilingual modelling, whereas BPE more effectively facilitates transfer during cross-lingual fine-tuning. Notably, our results suggest that differences in orthographic word boundary conventions (the morphological granularity of written words) may impede cross-lingual transfer more significantly than linguistic unrelatedness. Our study confirms that decisions around subword modelling can be key to optimising the benefits of multilingual modelling.
Triples-to-isiXhosa (T2X): Addressing the Challenges of Low-Resource Agglutinative Data-to-Text Generation
Mar 12, 2024



Most data-to-text datasets are for English, so the difficulties of modelling data-to-text for low-resource languages are largely unexplored. In this paper we tackle data-to-text for isiXhosa, which is low-resource and agglutinative. We introduce Triples-to-isiXhosa (T2X), a new dataset based on a subset of WebNLG, which presents a new linguistic context that shifts modelling demands to subword-driven techniques. We also develop an evaluation framework for T2X that measures how accurately generated text describes the data. This enables future users of T2X to go beyond surface-level metrics in evaluation. On the modelling side we explore two classes of methods - dedicated data-to-text models trained from scratch and pretrained language models (PLMs). We propose a new dedicated architecture aimed at agglutinative data-to-text, the Subword Segmental Pointer Generator (SSPG). It jointly learns to segment words and copy entities, and outperforms existing dedicated models for 2 agglutinative languages (isiXhosa and Finnish). We investigate pretrained solutions for T2X, which reveals that standard PLMs come up short. Fine-tuning machine translation models emerges as the best method overall. These findings underscore the distinct challenge presented by T2X: neither well-established data-to-text architectures nor customary pretrained methodologies prove optimal. We conclude with a qualitative analysis of generation errors and an ablation study.
Multipath parsing in the brain
Jan 31, 2024



Humans understand sentences word-by-word, in the order that they hear them. This incrementality entails resolving temporary ambiguities about syntactic relationships. We investigate how humans process these syntactic ambiguities by correlating predictions from incremental generative dependency parsers with timecourse data from people undergoing functional neuroimaging while listening to an audiobook. In particular, we compare competing hypotheses regarding the number of developing syntactic analyses in play during word-by-word comprehension: one vs more than one. This comparison involves evaluating syntactic surprisal from a state-of-the-art dependency parser with LLM-adapted encodings against an existing fMRI dataset. In both English and Chinese data, we find evidence for multipath parsing. Brain regions associated with this multipath effect include bilateral superior temporal gyrus.
Subword Segmental Machine Translation: Unifying Segmentation and Target Sentence Generation
May 11, 2023Subword segmenters like BPE operate as a preprocessing step in neural machine translation and other (conditional) language models. They are applied to datasets before training, so translation or text generation quality relies on the quality of segmentations. We propose a departure from this paradigm, called subword segmental machine translation (SSMT). SSMT unifies subword segmentation and MT in a single trainable model. It learns to segment target sentence words while jointly learning to generate target sentences. To use SSMT during inference we propose dynamic decoding, a text generation algorithm that adapts segmentations as it generates translations. Experiments across 6 translation directions show that SSMT improves chrF scores for morphologically rich agglutinative languages. Gains are strongest in the very low-resource scenario. SSMT also learns subwords that are closer to morphemes compared to baselines and proves more robust on a test set constructed for evaluating morphological compositional generalisation.
Subword Segmental Language Modelling for Nguni Languages
Oct 12, 2022
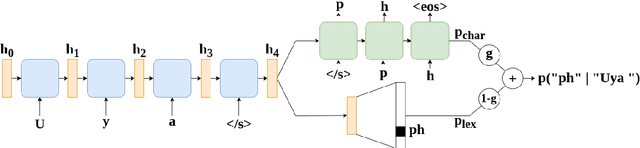
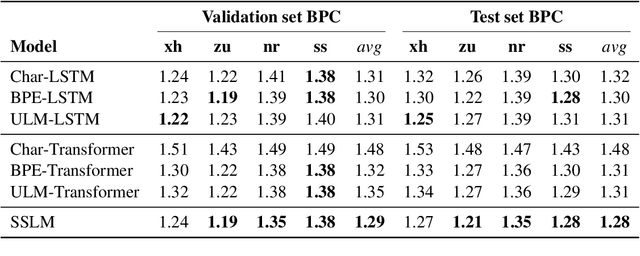
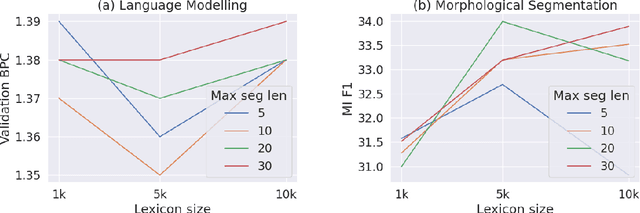
Subwords have become the standard units of text in NLP, enabling efficient open-vocabulary models. With algorithms like byte-pair encoding (BPE), subword segmentation is viewed as a preprocessing step applied to the corpus before training. This can lead to sub-optimal segmentations for low-resource languages with complex morphologies. We propose a subword segmental language model (SSLM) that learns how to segment words while being trained for autoregressive language modelling. By unifying subword segmentation and language modelling, our model learns subwords that optimise LM performance. We train our model on the 4 Nguni languages of South Africa. These are low-resource agglutinative languages, so subword information is critical. As an LM, SSLM outperforms existing approaches such as BPE-based models on average across the 4 languages. Furthermore, it outperforms standard subword segmenters on unsupervised morphological segmentation. We also train our model as a word-level sequence model, resulting in an unsupervised morphological segmenter that outperforms existing methods by a large margin for all 4 languages. Our results show that learning subword segmentation is an effective alternative to existing subword segmenters, enabling the model to discover morpheme-like subwords that improve its LM capabilities.
Low-Resource Language Modelling of South African Languages
Apr 01, 2021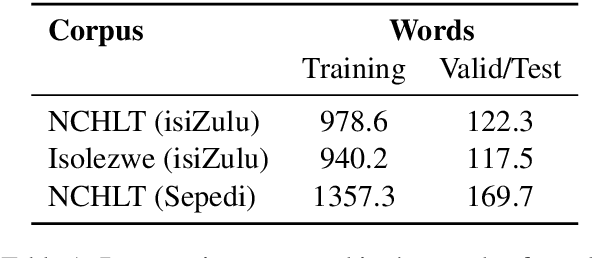
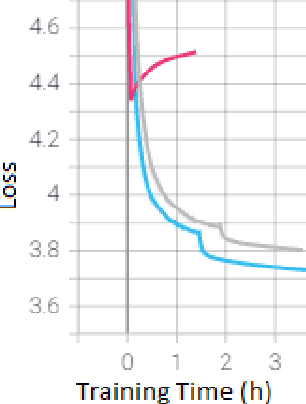
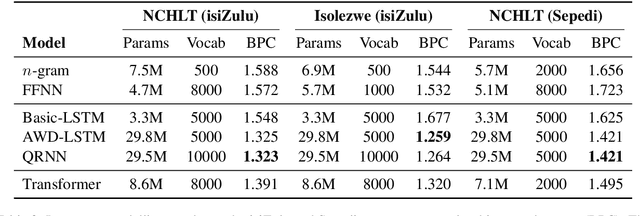
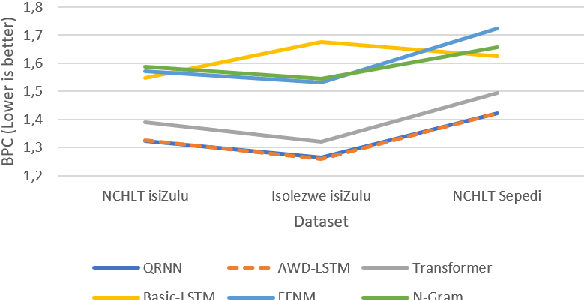
Language models are the foundation of current neural network-based models for natural language understanding and generation. However, research on the intrinsic performance of language models on African languages has been extremely limited, which is made more challenging by the lack of large or standardised training and evaluation sets that exist for English and other high-resource languages. In this paper, we evaluate the performance of open-vocabulary language models on low-resource South African languages, using byte-pair encoding to handle the rich morphology of these languages. We evaluate different variants of n-gram models, feedforward neural networks, recurrent neural networks (RNNs), and Transformers on small-scale datasets. Overall, well-regularized RNNs give the best performance across two isiZulu and one Sepedi datasets. Multilingual training further improves performance on these datasets. We hope that this research will open new avenues for research into multilingual and low-resource language modelling for African languages.
Canonical and Surface Morphological Segmentation for Nguni Languages
Apr 01, 2021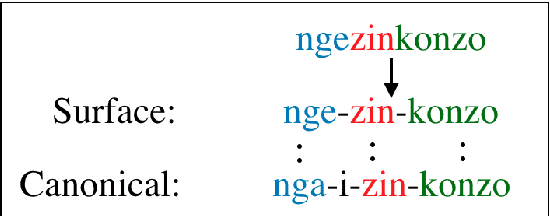
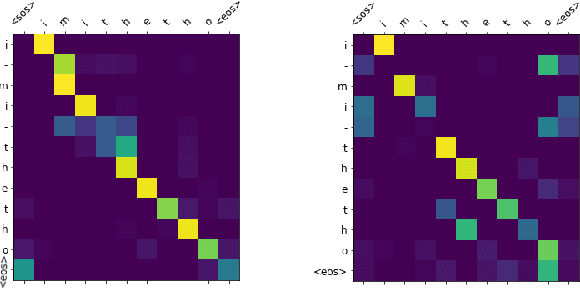
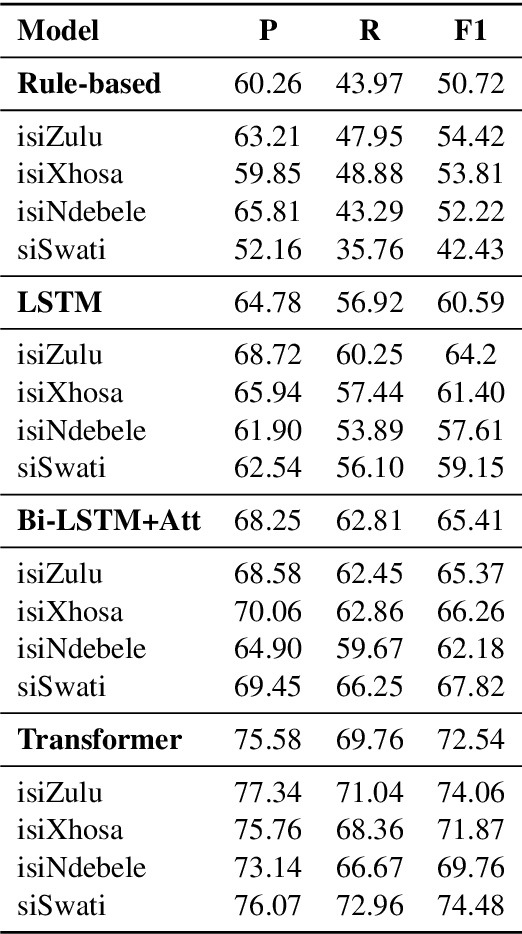
Morphological Segmentation involves decomposing words into morphemes, the smallest meaning-bearing units of language. This is an important NLP task for morphologically-rich agglutinative languages such as the Southern African Nguni language group. In this paper, we investigate supervised and unsupervised models for two variants of morphological segmentation: canonical and surface segmentation. We train sequence-to-sequence models for canonical segmentation, where the underlying morphemes may not be equal to the surface form of the word, and Conditional Random Fields (CRF) for surface segmentation. Transformers outperform LSTMs with attention on canonical segmentation, obtaining an average F1 score of 72.5% across 4 languages. Feature-based CRFs outperform bidirectional LSTM-CRFs to obtain an average of 97.1% F1 on surface segmentation. In the unsupervised setting, an entropy-based approach using a character-level LSTM language model fails to outperforms a Morfessor baseline, while on some of the languages neither approach performs much better than a random baseline. We hope that the high performance of the supervised segmentation models will help to facilitate the development of better NLP tools for Nguni languages.
BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle
Sep 20, 2019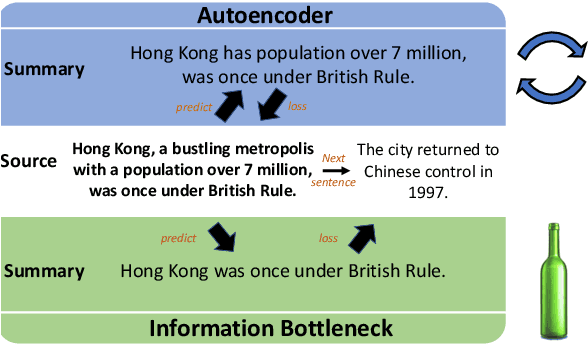
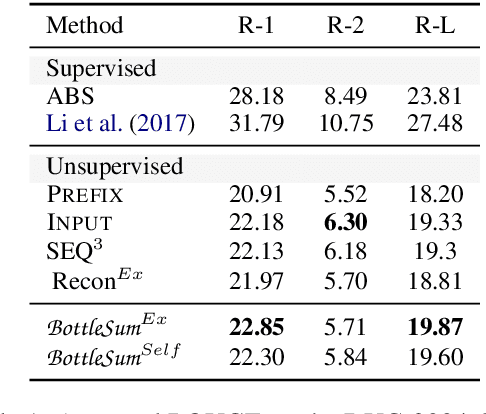
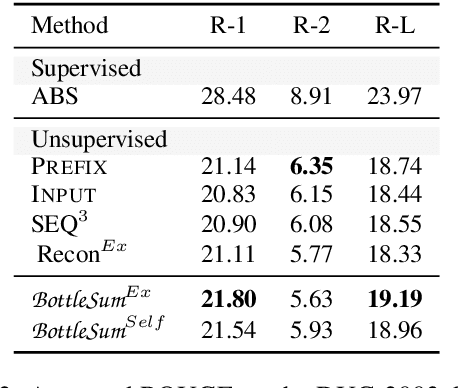
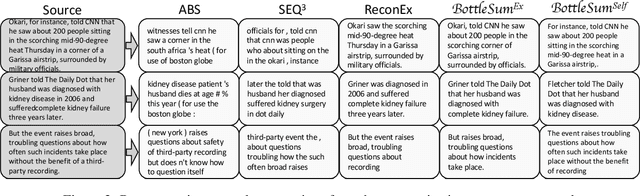
The principle of the Information Bottleneck (Tishby et al. 1999) is to produce a summary of information X optimized to predict some other relevant information Y. In this paper, we propose a novel approach to unsupervised sentence summarization by mapping the Information Bottleneck principle to a conditional language modelling objective: given a sentence, our approach seeks a compressed sentence that can best predict the next sentence. Our iterative algorithm under the Information Bottleneck objective searches gradually shorter subsequences of the given sentence while maximizing the probability of the next sentence conditioned on the summary. Using only pretrained language models with no direct supervision, our approach can efficiently perform extractive sentence summarization over a large corpus. Building on our unsupervised extractive summarization (BottleSumEx), we then present a new approach to self-supervised abstractive summarization (BottleSumSelf), where a transformer-based language model is trained on the output summaries of our unsupervised method. Empirical results demonstrate that our extractive method outperforms other unsupervised models on multiple automatic metrics. In addition, we find that our self-supervised abstractive model outperforms unsupervised baselines (including our own) by human evaluation along multiple attributes.