 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubword Segmental Language Modelling for Nguni Languages
Paper and Code

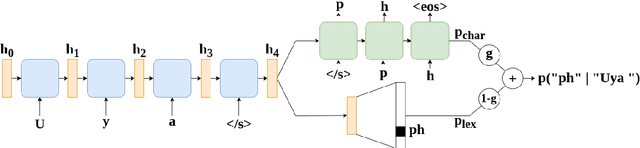
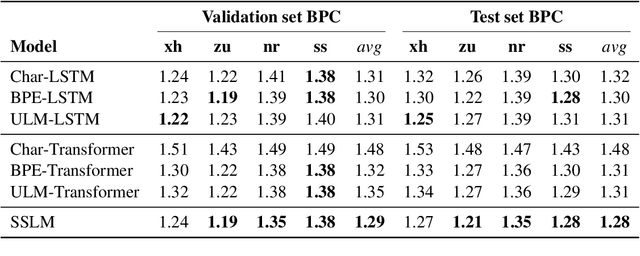
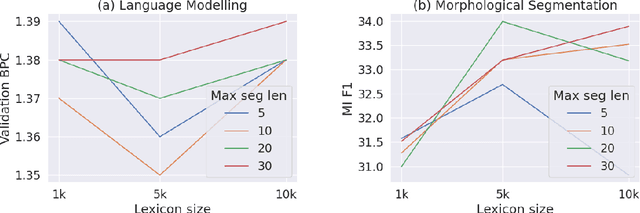
Subwords have become the standard units of text in NLP, enabling efficient open-vocabulary models. With algorithms like byte-pair encoding (BPE), subword segmentation is viewed as a preprocessing step applied to the corpus before training. This can lead to sub-optimal segmentations for low-resource languages with complex morphologies. We propose a subword segmental language model (SSLM) that learns how to segment words while being trained for autoregressive language modelling. By unifying subword segmentation and language modelling, our model learns subwords that optimise LM performance. We train our model on the 4 Nguni languages of South Africa. These are low-resource agglutinative languages, so subword information is critical. As an LM, SSLM outperforms existing approaches such as BPE-based models on average across the 4 languages. Furthermore, it outperforms standard subword segmenters on unsupervised morphological segmentation. We also train our model as a word-level sequence model, resulting in an unsupervised morphological segmenter that outperforms existing methods by a large margin for all 4 languages. Our results show that learning subword segmentation is an effective alternative to existing subword segmenters, enabling the model to discover morpheme-like subwords that improve its LM capabilities.