 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultipath parsing in the brain
Jan 31, 2024



Humans understand sentences word-by-word, in the order that they hear them. This incrementality entails resolving temporary ambiguities about syntactic relationships. We investigate how humans process these syntactic ambiguities by correlating predictions from incremental generative dependency parsers with timecourse data from people undergoing functional neuroimaging while listening to an audiobook. In particular, we compare competing hypotheses regarding the number of developing syntactic analyses in play during word-by-word comprehension: one vs more than one. This comparison involves evaluating syntactic surprisal from a state-of-the-art dependency parser with LLM-adapted encodings against an existing fMRI dataset. In both English and Chinese data, we find evidence for multipath parsing. Brain regions associated with this multipath effect include bilateral superior temporal gyrus.
SynJax: Structured Probability Distributions for JAX
Aug 15, 2023



The development of deep learning software libraries enabled significant progress in the field by allowing users to focus on modeling, while letting the library to take care of the tedious and time-consuming task of optimizing execution for modern hardware accelerators. However, this has benefited only particular types of deep learning models, such as Transformers, whose primitives map easily to the vectorized computation. The models that explicitly account for structured objects, such as trees and segmentations, did not benefit equally because they require custom algorithms that are difficult to implement in a vectorized form. SynJax directly addresses this problem by providing an efficient vectorized implementation of inference algorithms for structured distributions covering alignment, tagging, segmentation, constituency trees and spanning trees. With SynJax we can build large-scale differentiable models that explicitly model structure in the data. The code is available at https://github.com/deepmind/synjax.
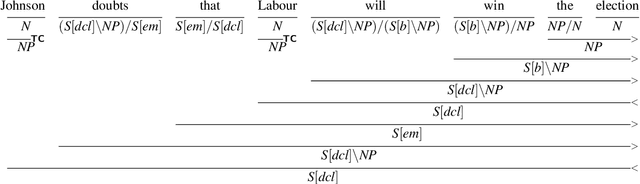
Modeling structure-building in the brain with CCG parsing and large language models
Nov 01, 2022To model behavioral and neural correlates of language comprehension in naturalistic environments, researchers have turned to broad-coverage tools from natural-language processing and machine learning. Where syntactic structure is explicitly modeled, prior work has relied predominantly on context-free grammars (CFG), yet such formalisms are not sufficiently expressive for human languages. Combinatory Categorial Grammars (CCGs) are sufficiently expressive directly compositional models of grammar with flexible constituency that affords incremental interpretation. In this work we evaluate whether a more expressive CCG provides a better model than a CFG for human neural signals collected with fMRI while participants listen to an audiobook story. We further test between variants of CCG that differ in how they handle optional adjuncts. These evaluations are carried out against a baseline that includes estimates of next-word predictability from a Transformer neural network language model. Such a comparison reveals unique contributions of CCG structure-building predominantly in the left posterior temporal lobe: CCG-derived measures offer a superior fit to neural signals compared to those derived from a CFG. These effects are spatially distinct from bilateral superior temporal effects that are unique to predictability. Neural effects for structure-building are thus separable from predictability during naturalistic listening, and those effects are best characterized by a grammar whose expressive power is motivated on independent linguistic grounds.
Unbiased and Efficient Sampling of Dependency Trees
May 25, 2022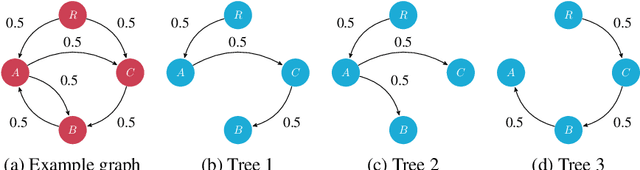
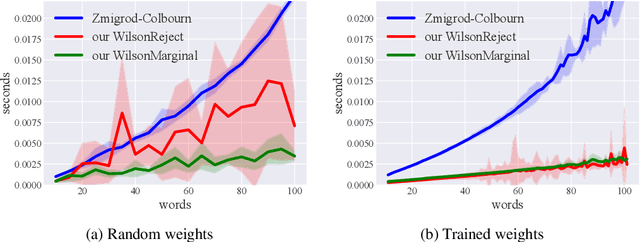
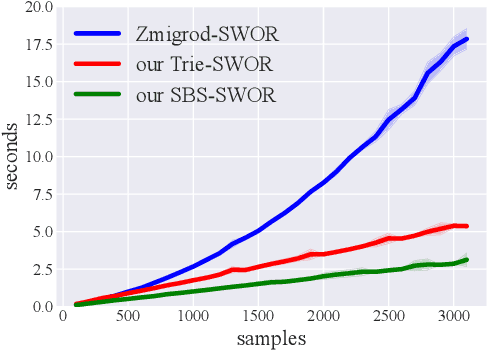
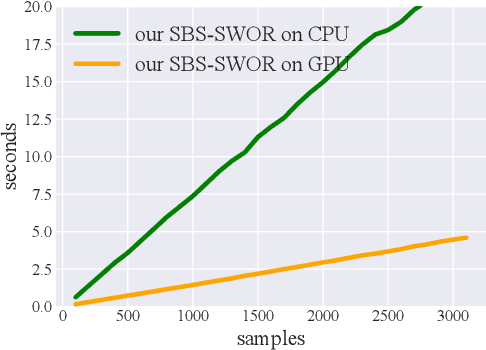
Distributions over spanning trees are the most common way of computational modeling of dependency syntax. However, most treebanks require that every valid dependency tree has a single edge coming out of the ROOT node, a constraint that is not part of the definition of spanning trees. For this reason all standard inference algorithms for spanning trees are sub-optimal for modeling dependency trees. Zmigrod et al. (2021b) have recently proposed algorithms for sampling with and without replacement from the single-root dependency tree distribution. In this paper we show that their fastest algorithm for sampling with replacement, Wilson-RC, is in fact producing biased samples and we provide two alternatives that are unbiased. Additionally, we propose two algorithms (one incremental, one parallel) that reduce the asymptotic runtime of their algorithm for sampling $k$ trees without replacement to $\mathcal{O}(kn^3)$. These algorithms are both asymptotically and practically more efficient.
Transformer Grammars: Augmenting Transformer Language Models with Syntactic Inductive Biases at Scale
Mar 01, 2022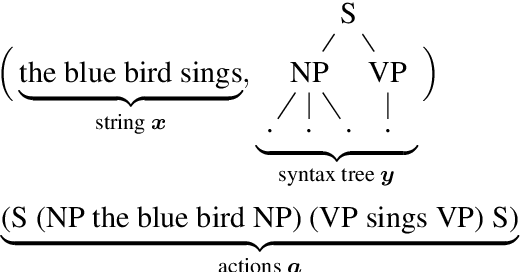
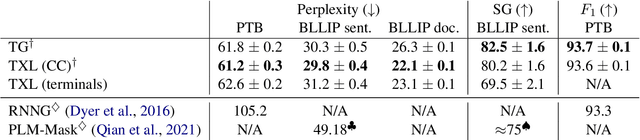
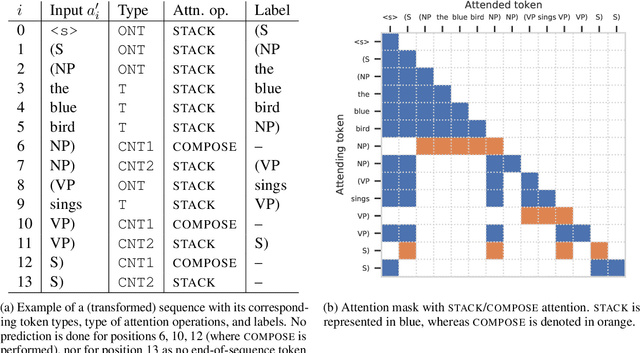
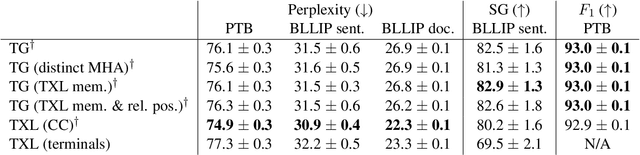
Transformer language models that are trained on vast amounts of data have achieved remarkable success at various NLP benchmarks. Intriguingly, this success is achieved by models that lack an explicit modeling of hierarchical syntactic structures, which were hypothesized by decades of linguistic research to be necessary for good generalization. This naturally leaves a question: to what extent can we further improve the performance of Transformer language models, through an inductive bias that encourages the model to explain the data through the lens of recursive syntactic compositions? Although the benefits of modeling recursive syntax have been shown at the small data and model scales, it remains an open question whether -- and to what extent -- a similar design principle is still beneficial in the case of powerful Transformer language models that work well at scale. To answer these questions, we introduce Transformer Grammars -- a novel class of Transformer language models that combine: (i) the expressive power, scalability, and strong performance of Transformers, and (ii) recursive syntactic compositions, which here are implemented through a special attention mask. We find that Transformer Grammars outperform various strong baselines on multiple syntax-sensitive language modeling evaluation metrics, in addition to sentence-level language modeling perplexity. Nevertheless, we find that the recursive syntactic composition bottleneck harms perplexity on document-level modeling, providing evidence that a different kind of memory mechanism -- that works independently of syntactic structures -- plays an important role in the processing of long-form text.
Modality and Negation in Event Extraction
Sep 20, 2021
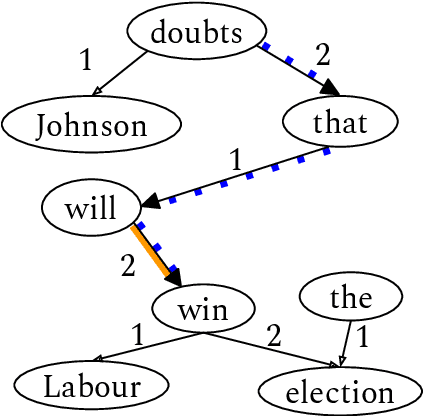
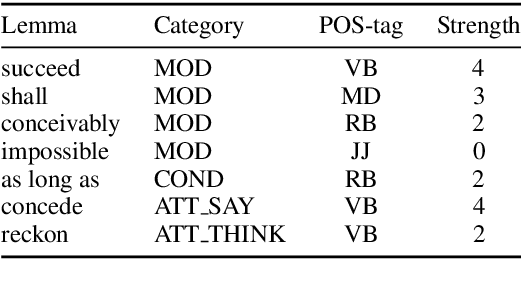
Language provides speakers with a rich system of modality for expressing thoughts about events, without being committed to their actual occurrence. Modality is commonly used in the political news domain, where both actual and possible courses of events are discussed. NLP systems struggle with these semantic phenomena, often incorrectly extracting events which did not happen, which can lead to issues in downstream applications. We present an open-domain, lexicon-based event extraction system that captures various types of modality. This information is valuable for Question Answering, Knowledge Graph construction and Fact-checking tasks, and our evaluation shows that the system is sufficiently strong to be used in downstream applications.
* S. Bijl de Vroe, L. Guillou, M. Stanojevi\'c, N. McKenna, and M. Steedman. 2021. Modality and Negation in Event Extraction. In Proceedings of the 4th Workshop on Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2021), pages 31-42, online. Association for Computational Linguistics
Removing Biases from Trainable MT Metrics by Using Self-Training
Aug 10, 2015

Most trainable machine translation (MT) metrics train their weights on human judgments of state-of-the-art MT systems outputs. This makes trainable metrics biases in many ways. One of them is preferring longer translations. These biased metrics when used for tuning are evaluating different types of translations -- n-best lists of translations with very diverse quality. Systems tuned with these metrics tend to produce overly long translations that are preferred by the metric but not by humans. This is usually solved by manually tweaking metric's weights to equally value recall and precision. Our solution is more general: (1) it does not address only the recall bias but also all other biases that might be present in the data and (2) it does not require any knowledge of the types of features used which is useful in cases when manual tuning of metric's weights is not possible. This is accomplished by self-training on unlabeled n-best lists by using metric that was initially trained on standard human judgments. One way of looking at this is as domain adaptation from the domain of state-of-the-art MT translations to diverse n-best list translations.