 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlindness to Modality Helps Entailment Graph Mining
Sep 21, 2021
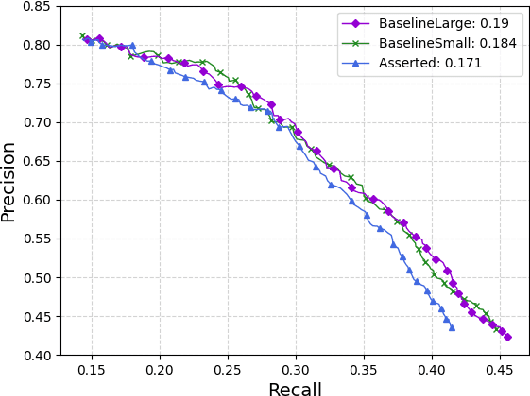
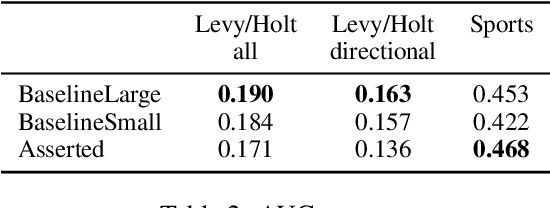
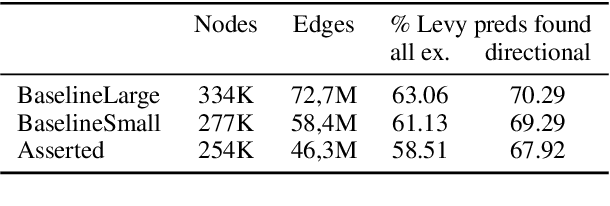
Understanding linguistic modality is widely seen as important for downstream tasks such as Question Answering and Knowledge Graph Population. Entailment Graph learning might also be expected to benefit from attention to modality. We build Entailment Graphs using a news corpus filtered with a modality parser, and show that stripping modal modifiers from predicates in fact increases performance. This suggests that for some tasks, the pragmatics of modal modification of predicates allows them to contribute as evidence of entailment.
Incorporating Temporal Information in Entailment Graph Mining
Sep 20, 2021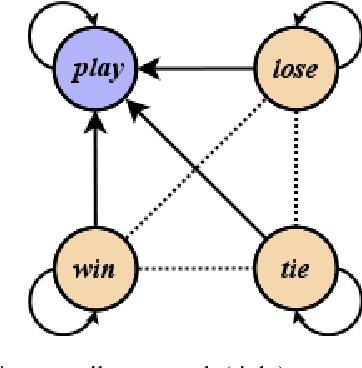
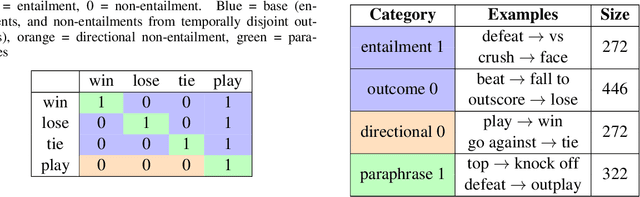
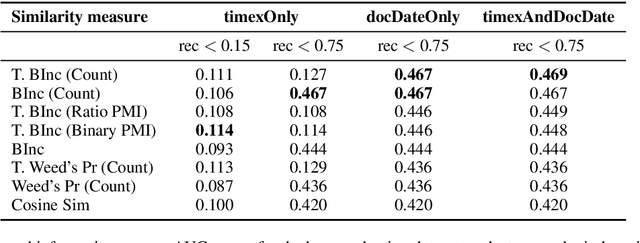
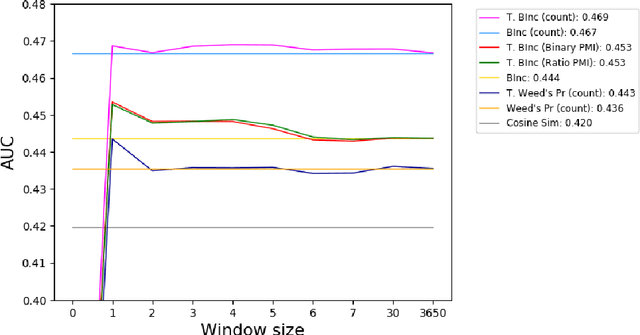
We present a novel method for injecting temporality into entailment graphs to address the problem of spurious entailments, which may arise from similar but temporally distinct events involving the same pair of entities. We focus on the sports domain in which the same pairs of teams play on different occasions, with different outcomes. We present an unsupervised model that aims to learn entailments such as win/lose $\rightarrow$ play, while avoiding the pitfall of learning non-entailments such as win $\not\rightarrow$ lose. We evaluate our model on a manually constructed dataset, showing that incorporating time intervals and applying a temporal window around them, are effective strategies.
* L. Guillou, S. Bijl de Vroe, M.J. Hosseini, M. Johnson, and M. Steedman. 2020. Incorporating temporal information in entailment graph mining. In Proceedings of the Graph-based Methods for Natural Language Processing (TextGraphs), pages 60-71, Barcelona, Spain (Online). Association for Computational Linguistics
Modality and Negation in Event Extraction
Sep 20, 2021
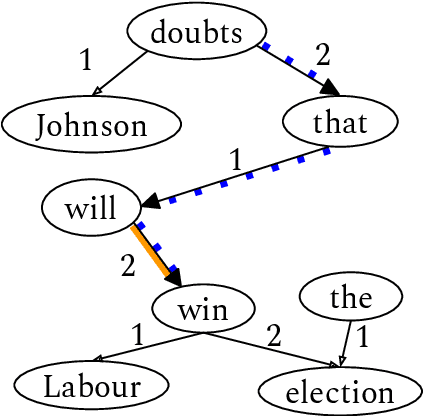
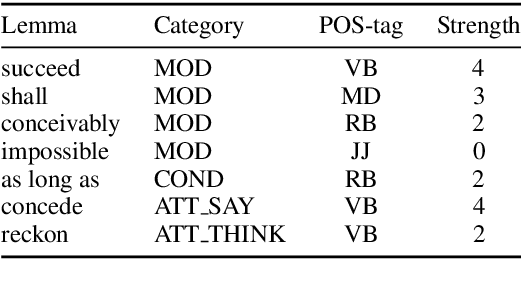
Language provides speakers with a rich system of modality for expressing thoughts about events, without being committed to their actual occurrence. Modality is commonly used in the political news domain, where both actual and possible courses of events are discussed. NLP systems struggle with these semantic phenomena, often incorrectly extracting events which did not happen, which can lead to issues in downstream applications. We present an open-domain, lexicon-based event extraction system that captures various types of modality. This information is valuable for Question Answering, Knowledge Graph construction and Fact-checking tasks, and our evaluation shows that the system is sufficiently strong to be used in downstream applications.
* S. Bijl de Vroe, L. Guillou, M. Stanojevi\'c, N. McKenna, and M. Steedman. 2021. Modality and Negation in Event Extraction. In Proceedings of the 4th Workshop on Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2021), pages 31-42, online. Association for Computational Linguistics
Multivalent Entailment Graphs for Question Answering
Apr 16, 2021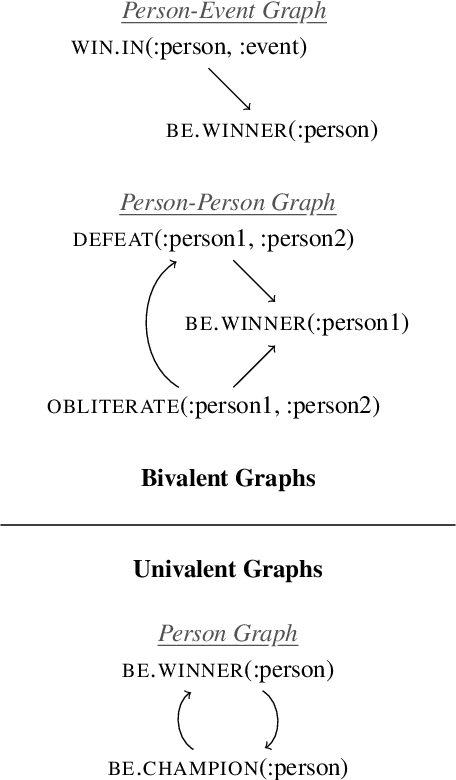
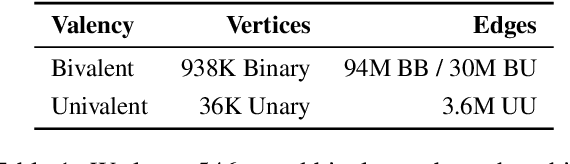

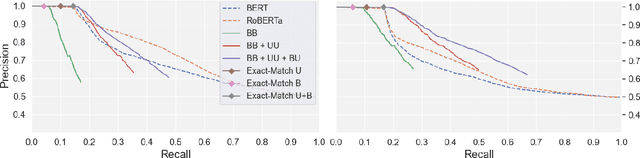
Drawing inferences between open-domain natural language predicates is a necessity for true language understanding. There has been much progress in unsupervised learning of entailment graphs for this purpose. We make three contributions: (1) we reinterpret the Distributional Inclusion Hypothesis to model entailment between predicates of different valencies, like DEFEAT(Biden, Trump) entails WIN(Biden); (2) we actualize this theory by learning unsupervised Multivalent Entailment Graphs of open-domain predicates; and (3) we demonstrate the capabilities of these graphs on a novel question answering task. We show that directional entailment is more helpful for inference than bidirectional similarity on questions of fine-grained semantics. We also show that drawing on evidence across valencies answers more questions than by using only the same valency evidence.
Temporal and Aspectual Entailment
Apr 02, 2019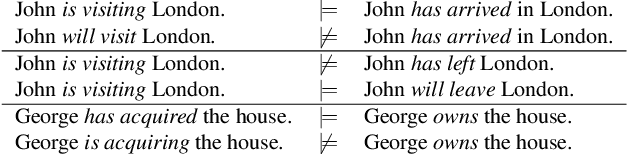
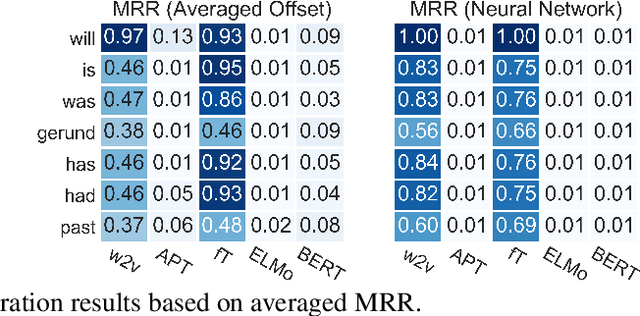
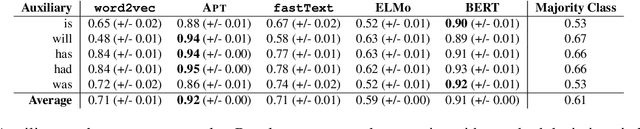
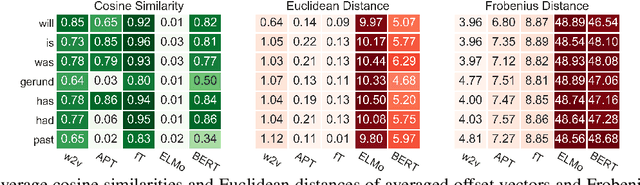
Inferences regarding "Jane's arrival in London" from predications such as "Jane is going to London" or "Jane has gone to London" depend on tense and aspect of the predications. Tense determines the temporal location of the predication in the past, present or future of the time of utterance. The aspectual auxiliaries on the other hand specify the internal constituency of the event, i.e. whether the event of "going to London" is completed and whether its consequences hold at that time or not. While tense and aspect are among the most important factors for determining natural language inference, there has been very little work to show whether modern NLP models capture these semantic concepts. In this paper we propose a novel entailment dataset and analyse the ability of a range of recently proposed NLP models to perform inference on temporal predications. We show that the models encode a substantial amount of morphosyntactic information relating to tense and aspect, but fail to model inferences that require reasoning with these semantic properties.