 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Variation? Evaluating NLI Performance in Basque and Spanish Geographical Variants
Jun 18, 2025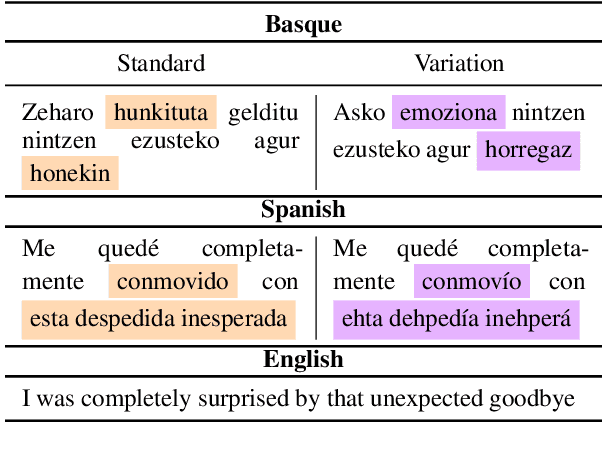
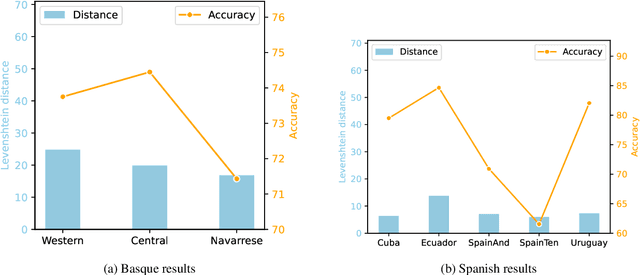

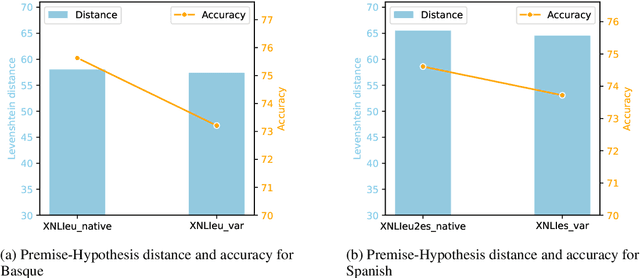
In this paper, we evaluate the capacity of current language technologies to understand Basque and Spanish language varieties. We use Natural Language Inference (NLI) as a pivot task and introduce a novel, manually-curated parallel dataset in Basque and Spanish, along with their respective variants. Our empirical analysis of crosslingual and in-context learning experiments using encoder-only and decoder-based Large Language Models (LLMs) shows a performance drop when handling linguistic variation, especially in Basque. Error analysis suggests that this decline is not due to lexical overlap, but rather to the linguistic variation itself. Further ablation experiments indicate that encoder-only models particularly struggle with Western Basque, which aligns with linguistic theory that identifies peripheral dialects (e.g., Western) as more distant from the standard. All data and code are publicly available.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
HiTZ at VarDial 2025 NorSID: Overcoming Data Scarcity with Language Transfer and Automatic Data Annotation
Dec 13, 2024In this paper we present our submission for the NorSID Shared Task as part of the 2025 VarDial Workshop (Scherrer et al., 2025), consisting of three tasks: Intent Detection, Slot Filling and Dialect Identification, evaluated using data in different dialects of the Norwegian language. For Intent Detection and Slot Filling, we have fine-tuned a multitask model in a cross-lingual setting, to leverage the xSID dataset available in 17 languages. In the case of Dialect Identification, our final submission consists of a model fine-tuned on the provided development set, which has obtained the highest scores within our experiments. Our final results on the test set show that our models do not drop in performance compared to the development set, likely due to the domain-specificity of the dataset and the similar distribution of both subsets. Finally, we also report an in-depth analysis of the provided datasets and their artifacts, as well as other sets of experiments that have been carried out but did not yield the best results. Additionally, we present an analysis on the reasons why some methods have been more successful than others; mainly the impact of the combination of languages and domain-specificity of the training data on the results.
Basque and Spanish Counter Narrative Generation: Data Creation and Evaluation
Mar 14, 2024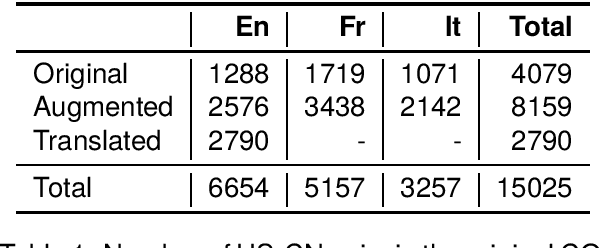
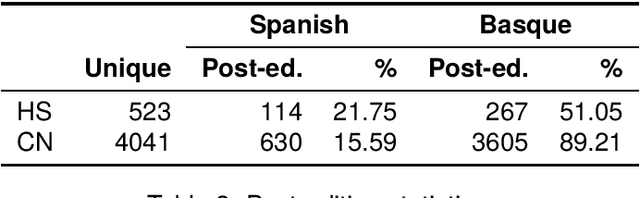
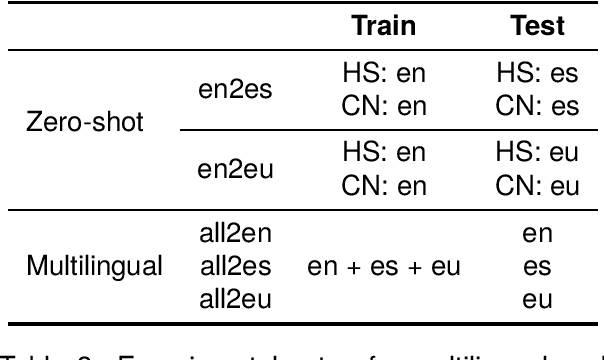
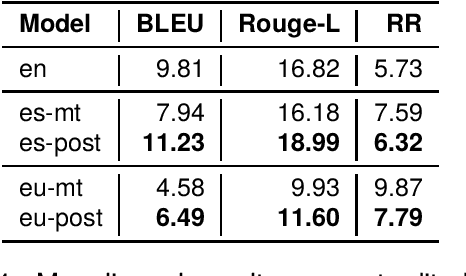
Counter Narratives (CNs) are non-negative textual responses to Hate Speech (HS) aiming at defusing online hatred and mitigating its spreading across media. Despite the recent increase in HS content posted online, research on automatic CN generation has been relatively scarce and predominantly focused on English. In this paper, we present CONAN-EUS, a new Basque and Spanish dataset for CN generation developed by means of Machine Translation (MT) and professional post-edition. Being a parallel corpus, also with respect to the original English CONAN, it allows to perform novel research on multilingual and crosslingual automatic generation of CNs. Our experiments on CN generation with mT5, a multilingual encoder-decoder model, show that generation greatly benefits from training on post-edited data, as opposed to relying on silver MT data only. These results are confirmed by their correlation with a qualitative manual evaluation, demonstrating that manually revised training data remains crucial for the quality of the generated CNs. Furthermore, multilingual data augmentation improves results over monolingual settings for structurally similar languages such as English and Spanish, while being detrimental for Basque, a language isolate. Similar findings occur in zero-shot crosslingual evaluations, where model transfer (fine-tuning in English and generating in a different target language) outperforms fine-tuning mT5 on machine translated data for Spanish but not for Basque. This provides an interesting insight into the asymmetry in the multilinguality of generative models, a challenging topic which is still open to research.