 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking Over Scoring: Towards Reliable and Robust Automated Evaluation of LLM-Generated Medical Explanatory Arguments
Sep 30, 2024



Evaluating LLM-generated text has become a key challenge, especially in domain-specific contexts like the medical field. This work introduces a novel evaluation methodology for LLM-generated medical explanatory arguments, relying on Proxy Tasks and rankings to closely align results with human evaluation criteria, overcoming the biases typically seen in LLMs used as judges. We demonstrate that the proposed evaluators are robust against adversarial attacks, including the assessment of non-argumentative text. Additionally, the human-crafted arguments needed to train the evaluators are minimized to just one example per Proxy Task. By examining multiple LLM-generated arguments, we establish a methodology for determining whether a Proxy Task is suitable for evaluating LLM-generated medical explanatory arguments, requiring only five examples and two human experts.
Explanatory Argument Extraction of Correct Answers in Resident Medical Exams
Dec 01, 2023
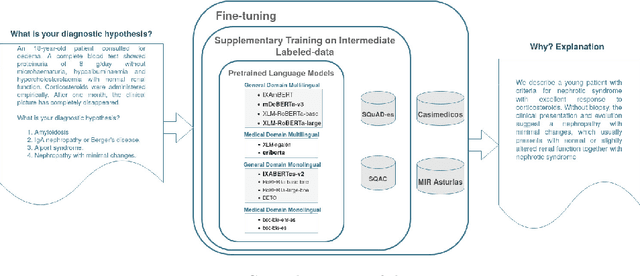


Developing the required technology to assist medical experts in their everyday activities is currently a hot topic in the Artificial Intelligence research field. Thus, a number of large language models (LLMs) and automated benchmarks have recently been proposed with the aim of facilitating information extraction in Evidence-Based Medicine (EBM) using natural language as a tool for mediating in human-AI interaction. The most representative benchmarks are limited to either multiple-choice or long-form answers and are available only in English. In order to address these shortcomings, in this paper we present a new dataset which, unlike previous work: (i) includes not only explanatory arguments for the correct answer, but also arguments to reason why the incorrect answers are not correct; (ii) the explanations are written originally by medical doctors to answer questions from the Spanish Residency Medical Exams. Furthermore, this new benchmark allows us to setup a novel extractive task which consists of identifying the explanation of the correct answer written by medical doctors. An additional benefit of our setting is that we can leverage the extractive QA paradigm to automatically evaluate performance of LLMs without resorting to costly manual evaluation by medical experts. Comprehensive experimentation with language models for Spanish shows that sometimes multilingual models fare better than monolingual ones, even outperforming models which have been adapted to the medical domain. Furthermore, results across the monolingual models are mixed, with supposedly smaller and inferior models performing competitively. In any case, the obtained results show that our novel dataset and approach can be an effective technique to help medical practitioners in identifying relevant evidence-based explanations for medical questions.
HiTZ@Antidote: Argumentation-driven Explainable Artificial Intelligence for Digital Medicine
Jun 09, 2023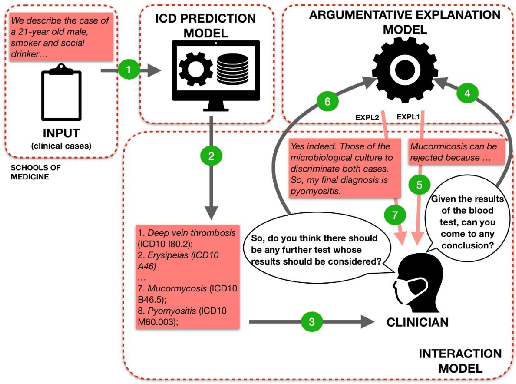
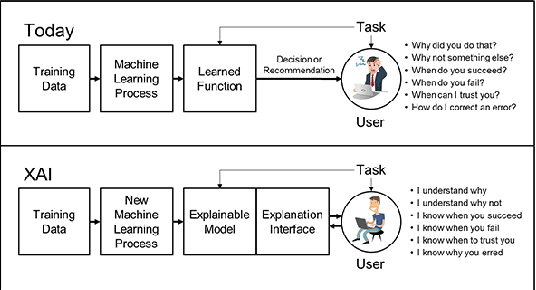
Providing high quality explanations for AI predictions based on machine learning is a challenging and complex task. To work well it requires, among other factors: selecting a proper level of generality/specificity of the explanation; considering assumptions about the familiarity of the explanation beneficiary with the AI task under consideration; referring to specific elements that have contributed to the decision; making use of additional knowledge (e.g. expert evidence) which might not be part of the prediction process; and providing evidence supporting negative hypothesis. Finally, the system needs to formulate the explanation in a clearly interpretable, and possibly convincing, way. Given these considerations, ANTIDOTE fosters an integrated vision of explainable AI, where low-level characteristics of the deep learning process are combined with higher level schemes proper of the human argumentation capacity. ANTIDOTE will exploit cross-disciplinary competences in deep learning and argumentation to support a broader and innovative view of explainable AI, where the need for high-quality explanations for clinical cases deliberation is critical. As a first result of the project, we publish the Antidote CasiMedicos dataset to facilitate research on explainable AI in general, and argumentation in the medical domain in particular.