 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgHiTZ at ArchEHR-QA 2025: A Two-Step Divide and Conquer Approach to Patient Question Answering for Top Factuality
Jun 15, 2025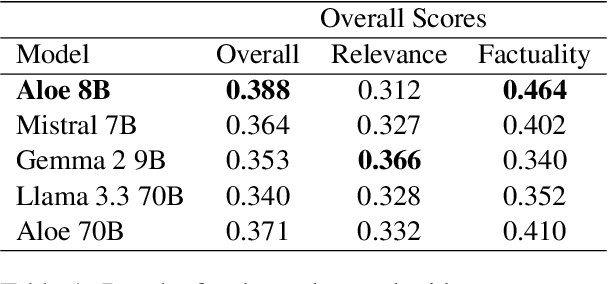
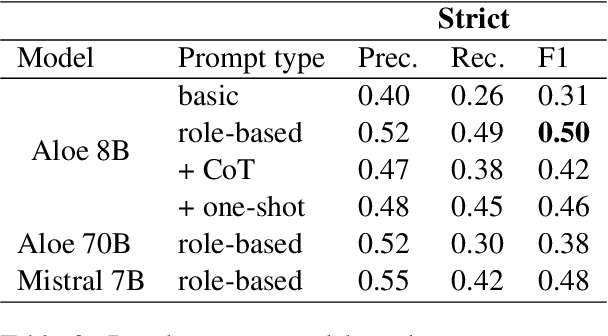
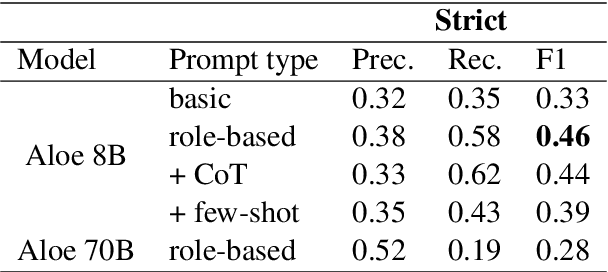
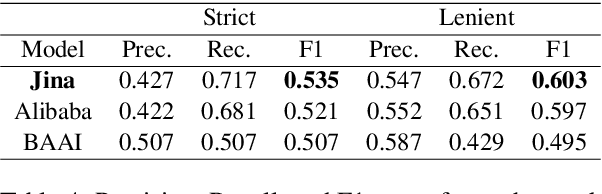
This work presents three different approaches to address the ArchEHR-QA 2025 Shared Task on automated patient question answering. We introduce an end-to-end prompt-based baseline and two two-step methods to divide the task, without utilizing any external knowledge. Both two step approaches first extract essential sentences from the clinical text, by prompt or similarity ranking, and then generate the final answer from these notes. Results indicate that the re-ranker based two-step system performs best, highlighting the importance of selecting the right approach for each subtask. Our best run achieved an overall score of 0.44, ranking 8th out of 30 on the leaderboard, securing the top position in overall factuality.
Ali-AUG: Innovative Approaches to Labeled Data Augmentation using One-Step Diffusion Model
Oct 24, 2024



This paper introduces Ali-AUG, a novel single-step diffusion model for efficient labeled data augmentation in industrial applications. Our method addresses the challenge of limited labeled data by generating synthetic, labeled images with precise feature insertion. Ali-AUG utilizes a stable diffusion architecture enhanced with skip connections and LoRA modules to efficiently integrate masks and images, ensuring accurate feature placement without affecting unrelated image content. Experimental validation across various industrial datasets demonstrates Ali-AUG's superiority in generating high-quality, defect-enhanced images while maintaining rapid single-step inference. By offering precise control over feature insertion and minimizing required training steps, our technique significantly enhances data augmentation capabilities, providing a powerful tool for improving the performance of deep learning models in scenarios with limited labeled data. Ali-AUG is especially useful for use cases like defective product image generation to train AI-based models to improve their ability to detect defects in manufacturing processes. Using different data preparation strategies, including Classification Accuracy Score (CAS) and Naive Augmentation Score (NAS), we show that Ali-AUG improves model performance by 31% compared to other augmentation methods and by 45% compared to models without data augmentation. Notably, Ali-AUG reduces training time by 32% and supports both paired and unpaired datasets, enhancing flexibility in data preparation.
Explanatory Argument Extraction of Correct Answers in Resident Medical Exams
Dec 01, 2023
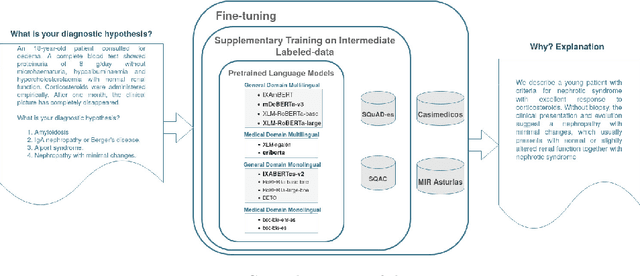


Developing the required technology to assist medical experts in their everyday activities is currently a hot topic in the Artificial Intelligence research field. Thus, a number of large language models (LLMs) and automated benchmarks have recently been proposed with the aim of facilitating information extraction in Evidence-Based Medicine (EBM) using natural language as a tool for mediating in human-AI interaction. The most representative benchmarks are limited to either multiple-choice or long-form answers and are available only in English. In order to address these shortcomings, in this paper we present a new dataset which, unlike previous work: (i) includes not only explanatory arguments for the correct answer, but also arguments to reason why the incorrect answers are not correct; (ii) the explanations are written originally by medical doctors to answer questions from the Spanish Residency Medical Exams. Furthermore, this new benchmark allows us to setup a novel extractive task which consists of identifying the explanation of the correct answer written by medical doctors. An additional benefit of our setting is that we can leverage the extractive QA paradigm to automatically evaluate performance of LLMs without resorting to costly manual evaluation by medical experts. Comprehensive experimentation with language models for Spanish shows that sometimes multilingual models fare better than monolingual ones, even outperforming models which have been adapted to the medical domain. Furthermore, results across the monolingual models are mixed, with supposedly smaller and inferior models performing competitively. In any case, the obtained results show that our novel dataset and approach can be an effective technique to help medical practitioners in identifying relevant evidence-based explanations for medical questions.
EriBERTa: A Bilingual Pre-Trained Language Model for Clinical Natural Language Processing
Jun 12, 2023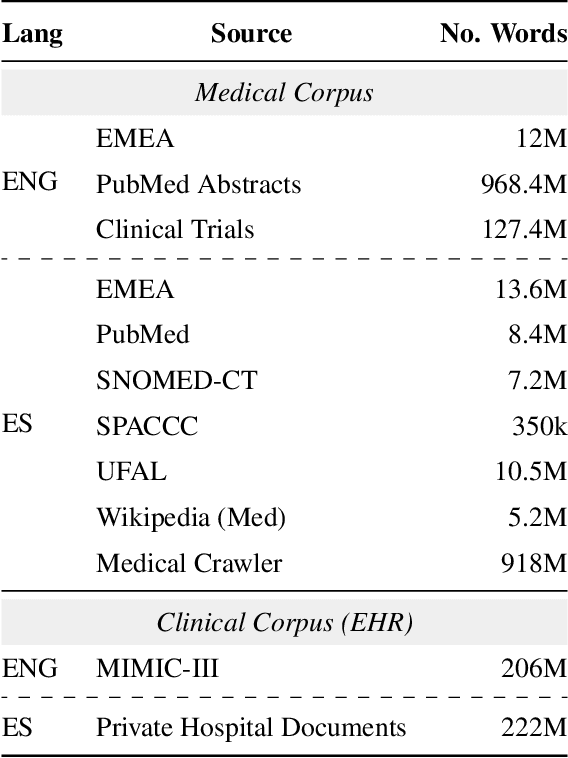
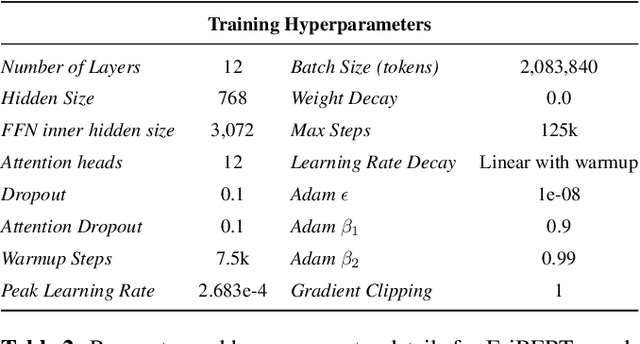
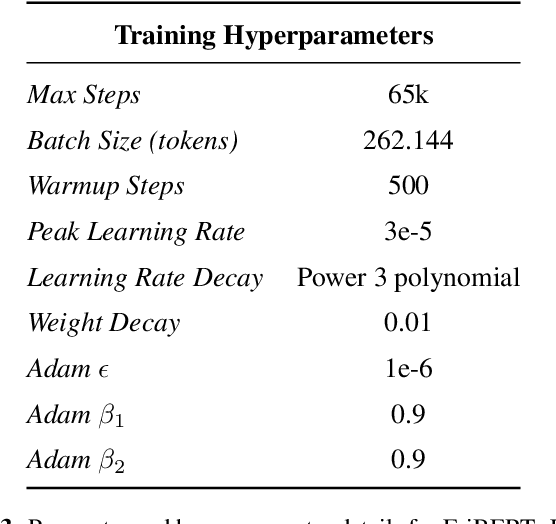
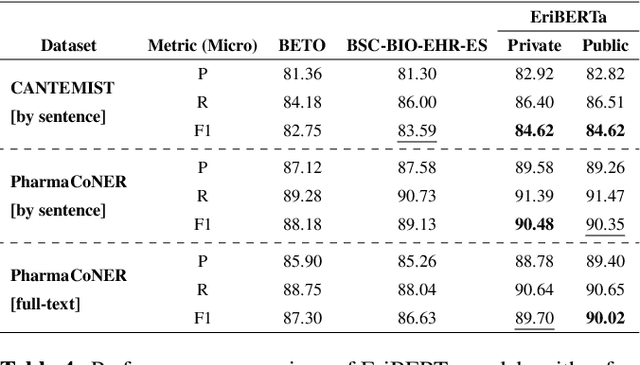
The utilization of clinical reports for various secondary purposes, including health research and treatment monitoring, is crucial for enhancing patient care. Natural Language Processing (NLP) tools have emerged as valuable assets for extracting and processing relevant information from these reports. However, the availability of specialized language models for the clinical domain in Spanish has been limited. In this paper, we introduce EriBERTa, a bilingual domain-specific language model pre-trained on extensive medical and clinical corpora. We demonstrate that EriBERTa outperforms previous Spanish language models in the clinical domain, showcasing its superior capabilities in understanding medical texts and extracting meaningful information. Moreover, EriBERTa exhibits promising transfer learning abilities, allowing for knowledge transfer from one language to another. This aspect is particularly beneficial given the scarcity of Spanish clinical data.
HiTZ@Antidote: Argumentation-driven Explainable Artificial Intelligence for Digital Medicine
Jun 09, 2023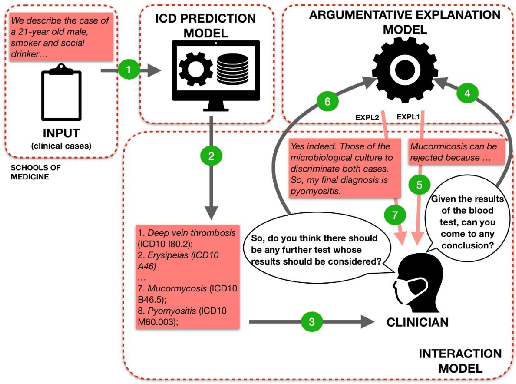
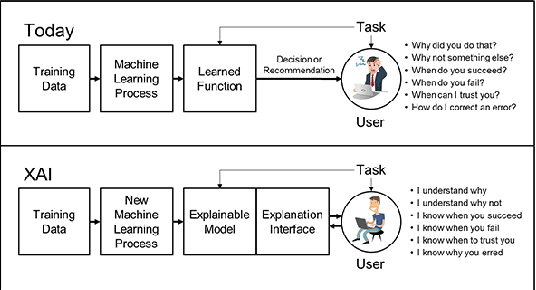
Providing high quality explanations for AI predictions based on machine learning is a challenging and complex task. To work well it requires, among other factors: selecting a proper level of generality/specificity of the explanation; considering assumptions about the familiarity of the explanation beneficiary with the AI task under consideration; referring to specific elements that have contributed to the decision; making use of additional knowledge (e.g. expert evidence) which might not be part of the prediction process; and providing evidence supporting negative hypothesis. Finally, the system needs to formulate the explanation in a clearly interpretable, and possibly convincing, way. Given these considerations, ANTIDOTE fosters an integrated vision of explainable AI, where low-level characteristics of the deep learning process are combined with higher level schemes proper of the human argumentation capacity. ANTIDOTE will exploit cross-disciplinary competences in deep learning and argumentation to support a broader and innovative view of explainable AI, where the need for high-quality explanations for clinical cases deliberation is critical. As a first result of the project, we publish the Antidote CasiMedicos dataset to facilitate research on explainable AI in general, and argumentation in the medical domain in particular.