 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Knowledge Integration for Evidence-Driven Counter-Argument Generation with Large Language Models
Mar 07, 2025



This paper investigates the role of dynamic external knowledge integration in improving counter-argument generation using Large Language Models (LLMs). While LLMs have shown promise in argumentative tasks, their tendency to generate lengthy, potentially unfactual responses highlights the need for more controlled and evidence-based approaches. We introduce a new manually curated dataset of argument and counter-argument pairs specifically designed to balance argumentative complexity with evaluative feasibility. We also propose a new LLM-as-a-Judge evaluation methodology that shows a stronger correlation with human judgments compared to traditional reference-based metrics. Our experimental results demonstrate that integrating dynamic external knowledge from the web significantly improves the quality of generated counter-arguments, particularly in terms of relatedness, persuasiveness, and factuality. The findings suggest that combining LLMs with real-time external knowledge retrieval offers a promising direction for developing more effective and reliable counter-argumentation systems.
Argument Mining in Data Scarce Settings: Cross-lingual Transfer and Few-shot Techniques
Jul 04, 2024



Recent research on sequence labelling has been exploring different strategies to mitigate the lack of manually annotated data for the large majority of the world languages. Among others, the most successful approaches have been based on (i) the cross-lingual transfer capabilities of multilingual pre-trained language models (model-transfer), (ii) data translation and label projection (data-transfer) and (iii), prompt-based learning by reusing the mask objective to exploit the few-shot capabilities of pre-trained language models (few-shot). Previous work seems to conclude that model-transfer outperforms data-transfer methods and that few-shot techniques based on prompting are superior to updating the model's weights via fine-tuning. In this paper, we empirically demonstrate that, for Argument Mining, a sequence labelling task which requires the detection of long and complex discourse structures, previous insights on cross-lingual transfer or few-shot learning do not apply. Contrary to previous work, we show that for Argument Mining data transfer obtains better results than model-transfer and that fine-tuning outperforms few-shot methods. Regarding the former, the domain of the dataset used for data-transfer seems to be a deciding factor, while, for few-shot, the type of task (length and complexity of the sequence spans) and sampling method prove to be crucial.
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
Apr 08, 2024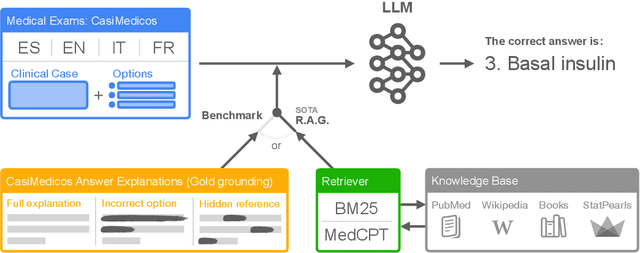


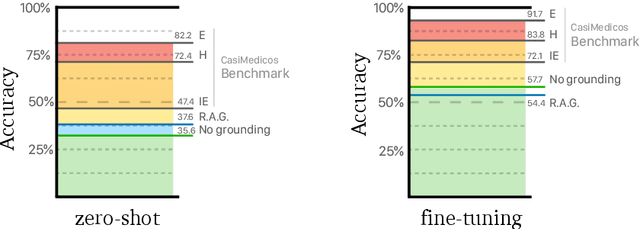
Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
Explanatory Argument Extraction of Correct Answers in Resident Medical Exams
Dec 01, 2023
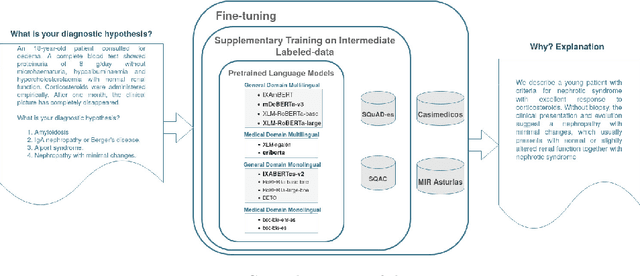


Developing the required technology to assist medical experts in their everyday activities is currently a hot topic in the Artificial Intelligence research field. Thus, a number of large language models (LLMs) and automated benchmarks have recently been proposed with the aim of facilitating information extraction in Evidence-Based Medicine (EBM) using natural language as a tool for mediating in human-AI interaction. The most representative benchmarks are limited to either multiple-choice or long-form answers and are available only in English. In order to address these shortcomings, in this paper we present a new dataset which, unlike previous work: (i) includes not only explanatory arguments for the correct answer, but also arguments to reason why the incorrect answers are not correct; (ii) the explanations are written originally by medical doctors to answer questions from the Spanish Residency Medical Exams. Furthermore, this new benchmark allows us to setup a novel extractive task which consists of identifying the explanation of the correct answer written by medical doctors. An additional benefit of our setting is that we can leverage the extractive QA paradigm to automatically evaluate performance of LLMs without resorting to costly manual evaluation by medical experts. Comprehensive experimentation with language models for Spanish shows that sometimes multilingual models fare better than monolingual ones, even outperforming models which have been adapted to the medical domain. Furthermore, results across the monolingual models are mixed, with supposedly smaller and inferior models performing competitively. In any case, the obtained results show that our novel dataset and approach can be an effective technique to help medical practitioners in identifying relevant evidence-based explanations for medical questions.
HiTZ@Antidote: Argumentation-driven Explainable Artificial Intelligence for Digital Medicine
Jun 09, 2023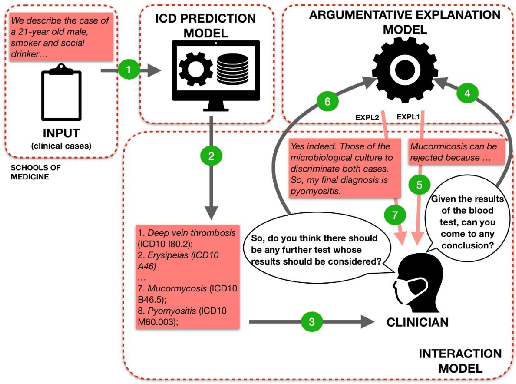
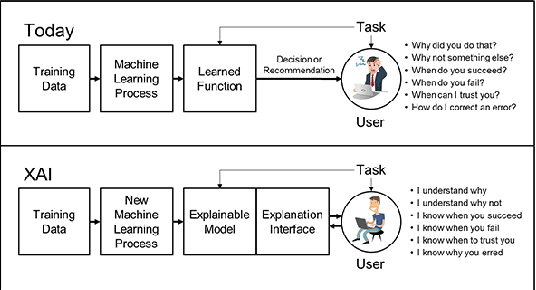
Providing high quality explanations for AI predictions based on machine learning is a challenging and complex task. To work well it requires, among other factors: selecting a proper level of generality/specificity of the explanation; considering assumptions about the familiarity of the explanation beneficiary with the AI task under consideration; referring to specific elements that have contributed to the decision; making use of additional knowledge (e.g. expert evidence) which might not be part of the prediction process; and providing evidence supporting negative hypothesis. Finally, the system needs to formulate the explanation in a clearly interpretable, and possibly convincing, way. Given these considerations, ANTIDOTE fosters an integrated vision of explainable AI, where low-level characteristics of the deep learning process are combined with higher level schemes proper of the human argumentation capacity. ANTIDOTE will exploit cross-disciplinary competences in deep learning and argumentation to support a broader and innovative view of explainable AI, where the need for high-quality explanations for clinical cases deliberation is critical. As a first result of the project, we publish the Antidote CasiMedicos dataset to facilitate research on explainable AI in general, and argumentation in the medical domain in particular.