 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Adapt or not to Adapt, Rethinking the Value of Medical Knowledge-Aware Large Language Models
Apr 08, 2026BACKGROUND: Recent studies have shown that domain-adapted large language models (LLMs) do not consistently outperform general-purpose counterparts on standard medical benchmarks, raising questions about the need for specialized clinical adaptation. METHODS: We systematically compare general and clinical LLMs on a diverse set of multiple choice clinical question answering tasks in English and Spanish. We introduce a perturbation based evaluation benchmark that probes model robustness, instruction following, and sensitivity to adversarial variations. Our evaluation includes, one-step and two-step question transformations, multi prompt testing and instruction guided assessment. We analyze a range of state-of-the-art clinical models and their general-purpose counterparts, focusing on Llama 3.1-based models. Additionally, we introduce Marmoka, a family of lightweight 8B-parameter clinical LLMs for English and Spanish, developed via continual domain-adaptive pretraining on medical corpora and instructions. RESULTS: The experiments show that clinical LLMs do not consistently outperform their general purpose counterparts on English clinical tasks, even under the proposed perturbation based benchmark. However, for the Spanish subsets the proposed Marmoka models obtain better results compared to Llama. CONCLUSIONS: Our results show that, under current short-form MCQA benchmarks, clinical LLMs offer only marginal and unstable improvements over general-purpose models in English, suggesting that existing evaluation frameworks may be insufficient to capture genuine medical expertise. We further find that both general and clinical models exhibit substantial limitations in instruction following and strict output formatting. Finally, we demonstrate that robust medical LLMs can be successfully developed for low-resource languages such as Spanish, as evidenced by the Marmoka models.
ArgHiTZ at ArchEHR-QA 2025: A Two-Step Divide and Conquer Approach to Patient Question Answering for Top Factuality
Jun 15, 2025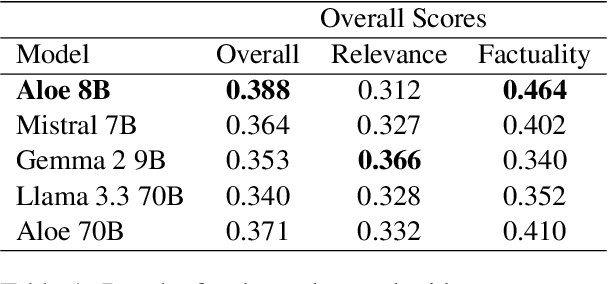
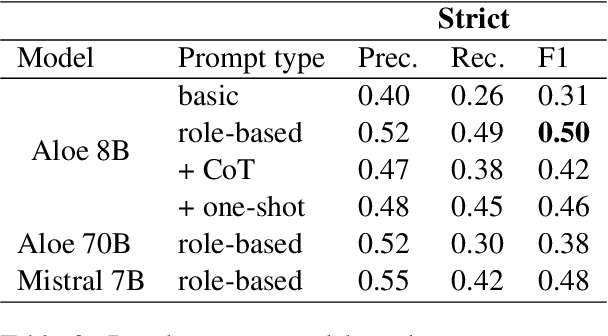
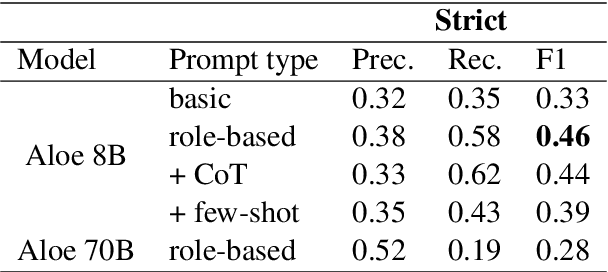
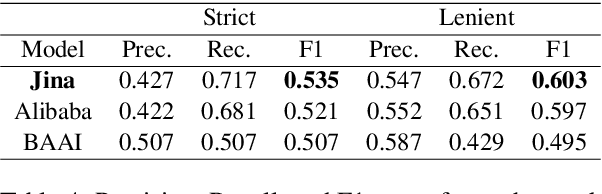
This work presents three different approaches to address the ArchEHR-QA 2025 Shared Task on automated patient question answering. We introduce an end-to-end prompt-based baseline and two two-step methods to divide the task, without utilizing any external knowledge. Both two step approaches first extract essential sentences from the clinical text, by prompt or similarity ranking, and then generate the final answer from these notes. Results indicate that the re-ranker based two-step system performs best, highlighting the importance of selecting the right approach for each subtask. Our best run achieved an overall score of 0.44, ranking 8th out of 30 on the leaderboard, securing the top position in overall factuality.
Medical Argument Mining: Exploitation of Scarce Data Using NLI Systems
Jun 15, 2025
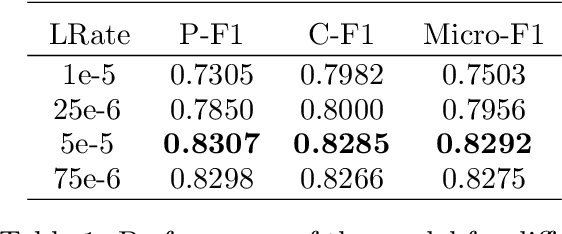
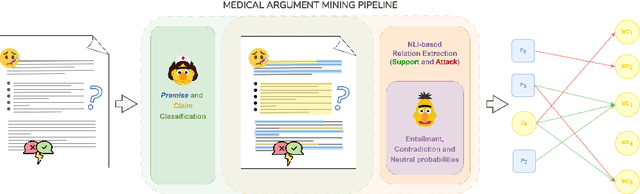
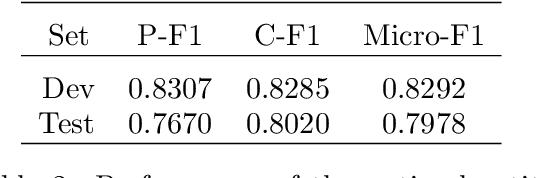
This work presents an Argument Mining process that extracts argumentative entities from clinical texts and identifies their relationships using token classification and Natural Language Inference techniques. Compared to straightforward methods like text classification, this methodology demonstrates superior performance in data-scarce settings. By assessing the effectiveness of these methods in identifying argumentative structures that support or refute possible diagnoses, this research lays the groundwork for future tools that can provide evidence-based justifications for machine-generated clinical conclusions.
Ranking Over Scoring: Towards Reliable and Robust Automated Evaluation of LLM-Generated Medical Explanatory Arguments
Sep 30, 2024



Evaluating LLM-generated text has become a key challenge, especially in domain-specific contexts like the medical field. This work introduces a novel evaluation methodology for LLM-generated medical explanatory arguments, relying on Proxy Tasks and rankings to closely align results with human evaluation criteria, overcoming the biases typically seen in LLMs used as judges. We demonstrate that the proposed evaluators are robust against adversarial attacks, including the assessment of non-argumentative text. Additionally, the human-crafted arguments needed to train the evaluators are minimized to just one example per Proxy Task. By examining multiple LLM-generated arguments, we establish a methodology for determining whether a Proxy Task is suitable for evaluating LLM-generated medical explanatory arguments, requiring only five examples and two human experts.
EriBERTa: A Bilingual Pre-Trained Language Model for Clinical Natural Language Processing
Jun 12, 2023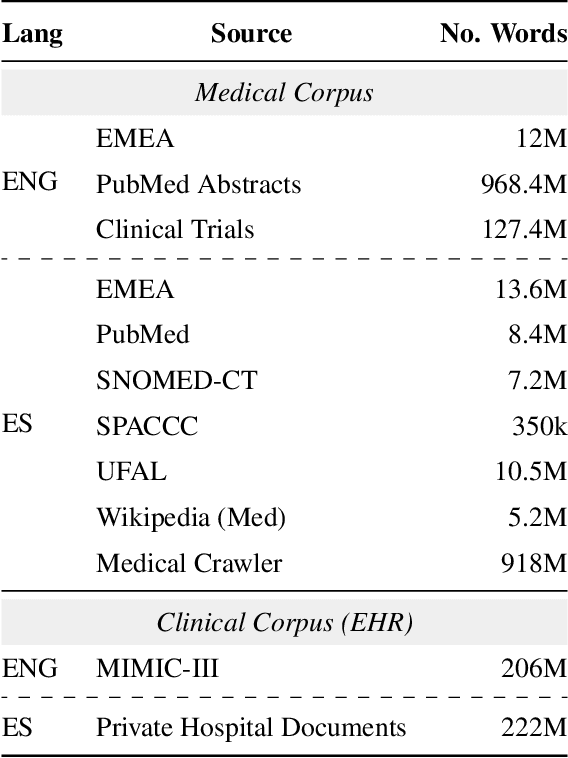
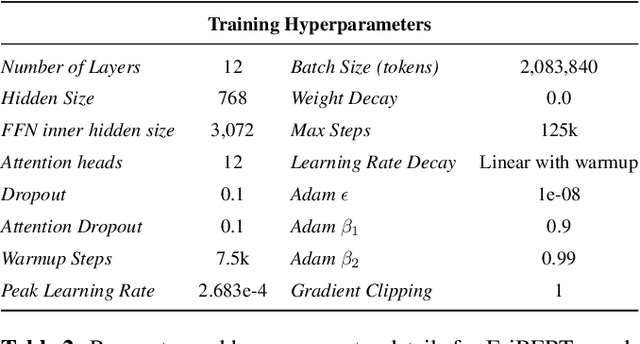
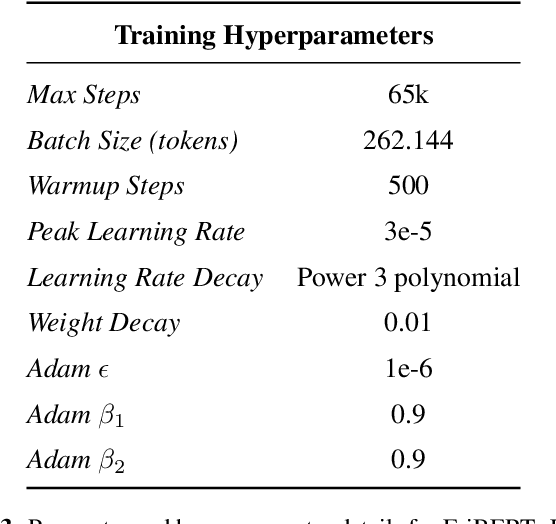
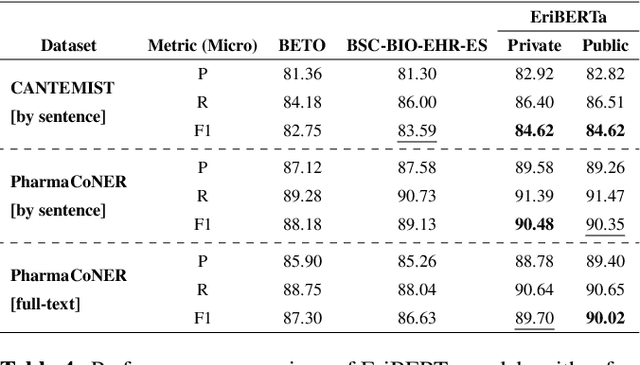
The utilization of clinical reports for various secondary purposes, including health research and treatment monitoring, is crucial for enhancing patient care. Natural Language Processing (NLP) tools have emerged as valuable assets for extracting and processing relevant information from these reports. However, the availability of specialized language models for the clinical domain in Spanish has been limited. In this paper, we introduce EriBERTa, a bilingual domain-specific language model pre-trained on extensive medical and clinical corpora. We demonstrate that EriBERTa outperforms previous Spanish language models in the clinical domain, showcasing its superior capabilities in understanding medical texts and extracting meaningful information. Moreover, EriBERTa exhibits promising transfer learning abilities, allowing for knowledge transfer from one language to another. This aspect is particularly beneficial given the scarcity of Spanish clinical data.
Label Verbalization and Entailment for Effective Zero- and Few-Shot Relation Extraction
Sep 08, 2021
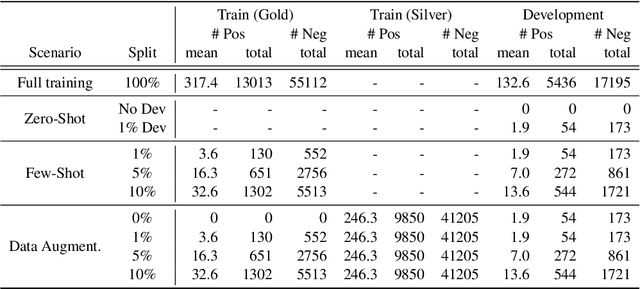

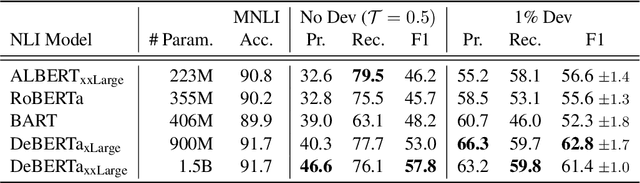
Relation extraction systems require large amounts of labeled examples which are costly to annotate. In this work we reformulate relation extraction as an entailment task, with simple, hand-made, verbalizations of relations produced in less than 15 min per relation. The system relies on a pretrained textual entailment engine which is run as-is (no training examples, zero-shot) or further fine-tuned on labeled examples (few-shot or fully trained). In our experiments on TACRED we attain 63% F1 zero-shot, 69% with 16 examples per relation (17% points better than the best supervised system on the same conditions), and only 4 points short to the state-of-the-art (which uses 20 times more training data). We also show that the performance can be improved significantly with larger entailment models, up to 12 points in zero-shot, allowing to report the best results to date on TACRED when fully trained. The analysis shows that our few-shot systems are specially effective when discriminating between relations, and that the performance difference in low data regimes comes mainly from identifying no-relation cases.
Give your Text Representation Models some Love: the Case for Basque
Apr 02, 2020
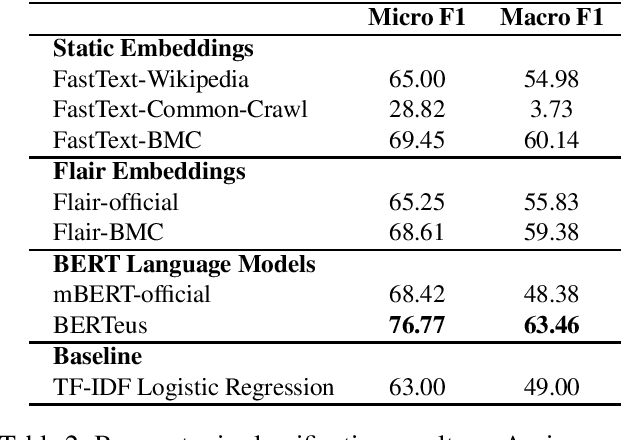
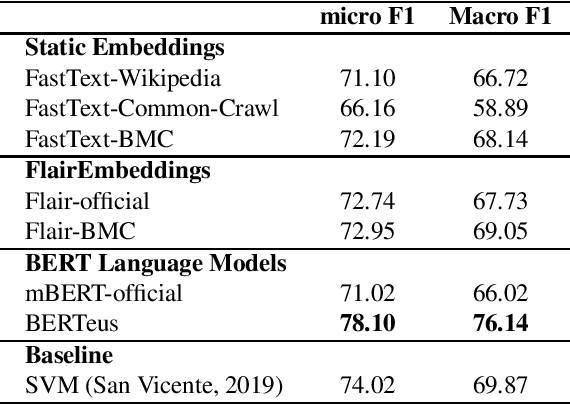
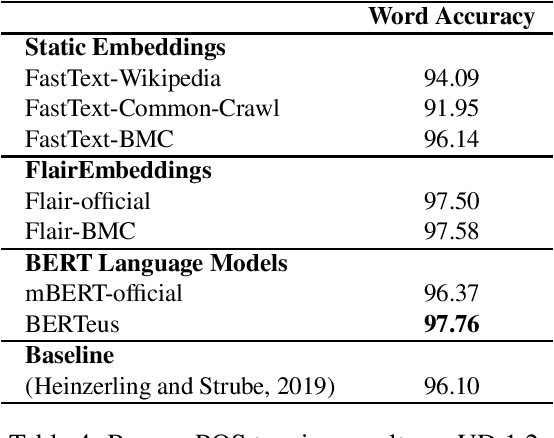
Word embeddings and pre-trained language models allow to build rich representations of text and have enabled improvements across most NLP tasks. Unfortunately they are very expensive to train, and many small companies and research groups tend to use models that have been pre-trained and made available by third parties, rather than building their own. This is suboptimal as, for many languages, the models have been trained on smaller (or lower quality) corpora. In addition, monolingual pre-trained models for non-English languages are not always available. At best, models for those languages are included in multilingual versions, where each language shares the quota of substrings and parameters with the rest of the languages. This is particularly true for smaller languages such as Basque. In this paper we show that a number of monolingual models (FastText word embeddings, FLAIR and BERT language models) trained with larger Basque corpora produce much better results than publicly available versions in downstream NLP tasks, including topic classification, sentiment classification, PoS tagging and NER. This work sets a new state-of-the-art in those tasks for Basque. All benchmarks and models used in this work are publicly available.
Studying the Wikipedia Hyperlink Graph for Relatedness and Disambiguation
Mar 12, 2015
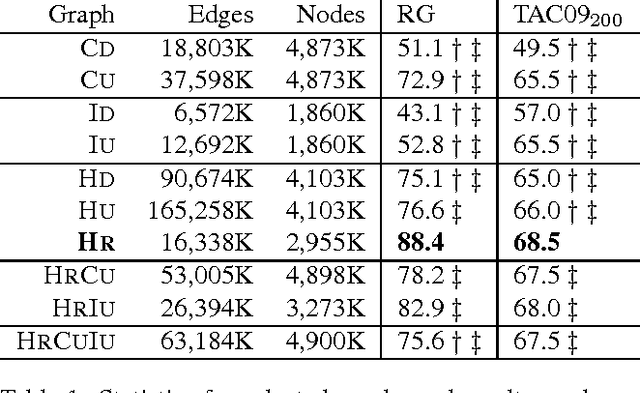

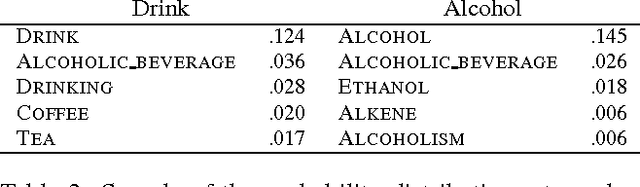
Hyperlinks and other relations in Wikipedia are a extraordinary resource which is still not fully understood. In this paper we study the different types of links in Wikipedia, and contrast the use of the full graph with respect to just direct links. We apply a well-known random walk algorithm on two tasks, word relatedness and named-entity disambiguation. We show that using the full graph is more effective than just direct links by a large margin, that non-reciprocal links harm performance, and that there is no benefit from categories and infoboxes, with coherent results on both tasks. We set new state-of-the-art figures for systems based on Wikipedia links, comparable to systems exploiting several information sources and/or supervised machine learning. Our approach is open source, with instruction to reproduce results, and amenable to be integrated with complementary text-based methods.