 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnraveling ChatGPT: A Critical Analysis of AI-Generated Goal-Oriented Dialogues and Annotations
May 23, 2023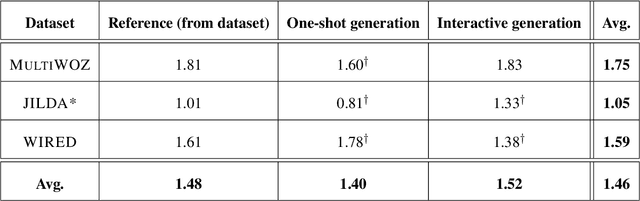
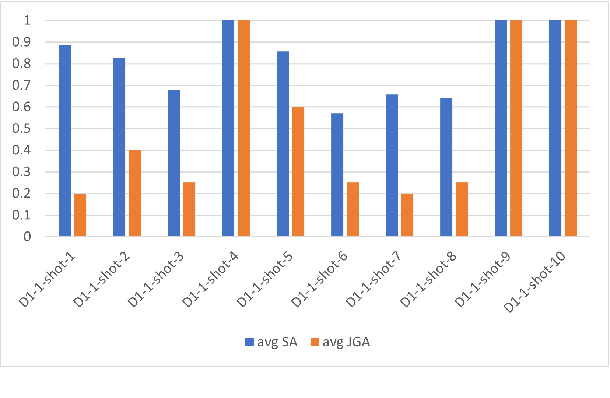

Large pre-trained language models have exhibited unprecedented capabilities in producing high-quality text via prompting techniques. This fact introduces new possibilities for data collection and annotation, particularly in situations where such data is scarce, complex to gather, expensive, or even sensitive. In this paper, we explore the potential of these models to generate and annotate goal-oriented dialogues, and conduct an in-depth analysis to evaluate their quality. Our experiments employ ChatGPT, and encompass three categories of goal-oriented dialogues (task-oriented, collaborative, and explanatory), two generation modes (interactive and one-shot), and two languages (English and Italian). Based on extensive human-based evaluations, we demonstrate that the quality of generated dialogues and annotations is on par with those generated by humans.