 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
Paper and Code
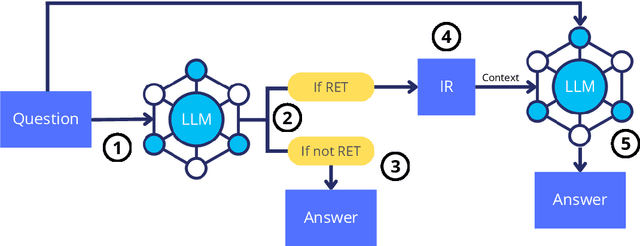

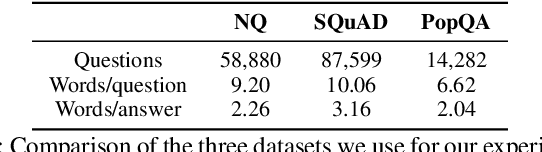
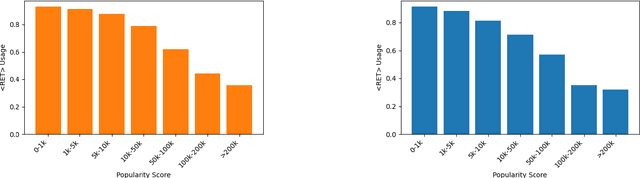
In this paper, we demonstrate how Large Language Models (LLMs) can effectively learn to use an off-the-shelf information retrieval (IR) system specifically when additional context is required to answer a given question. Given the performance of IR systems, the optimal strategy for question answering does not always entail external information retrieval; rather, it often involves leveraging the parametric memory of the LLM itself. Prior research has identified this phenomenon in the PopQA dataset, wherein the most popular questions are effectively addressed using the LLM's parametric memory, while less popular ones require IR system usage. Following this, we propose a tailored training approach for LLMs, leveraging existing open-domain question answering datasets. Here, LLMs are trained to generate a special token, <RET>, when they do not know the answer to a question. Our evaluation of the Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset showcases improvements over the same LLM under three configurations: (i) retrieving information for all the questions, (ii) using always the parametric memory of the LLM, and (iii) using a popularity threshold to decide when to use a retriever. Through our analysis, we demonstrate that Adapt-LLM is able to generate the <RET> token when it determines that it does not know how to answer a question, indicating the need for IR, while it achieves notably high accuracy levels when it chooses to rely only on its parametric memory.