 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
An Ecosystem for Personal Knowledge Graphs: A Survey and Research Roadmap
Apr 19, 2023


This paper presents an ecosystem for personal knowledge graphs (PKG), commonly defined as resources of structured information about entities related to an individual, their attributes, and the relations between them. PKGs are a key enabler of secure and sophisticated personal data management and personalized services. However, there are challenges that need to be addressed before PKGs can achieve widespread adoption. One of the fundamental challenges is the very definition of what constitutes a PKG, as there are multiple interpretations of the term. We propose our own definition of a PKG, emphasizing the aspects of (1) data ownership by a single individual and (2) the delivery of personalized services as the primary purpose. We further argue that a holistic view of PKGs is needed to unlock their full potential, and propose a unified framework for PKGs, where the PKG is a part of a larger ecosystem with clear interfaces towards data services and data sources. A comprehensive survey and synthesis of existing work is conducted, with a mapping of the surveyed work into the proposed unified ecosystem. Finally, we identify open challenges and research opportunities for the ecosystem as a whole, as well as for the specific aspects of PKGs, which include population, representation and management, and utilization.
From Baseline to Top Performer: A Reproducibility Study of Approaches at the TREC 2021 Conversational Assistance Track
Jan 25, 2023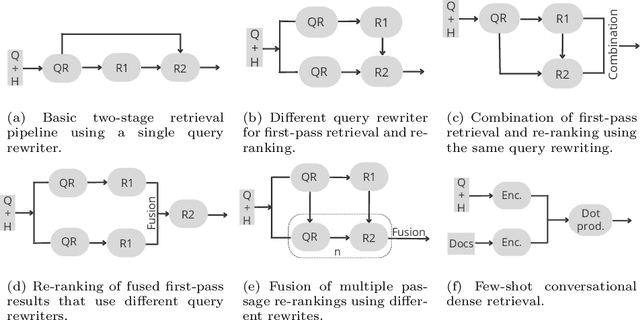

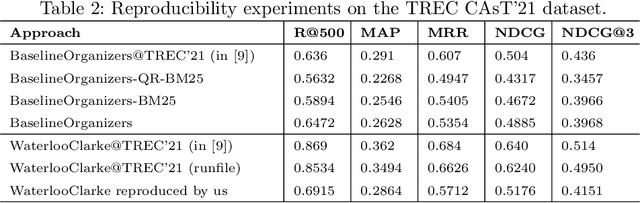

This paper reports on an effort of reproducing the organizers' baseline as well as the top performing participant submission at the 2021 edition of the TREC Conversational Assistance track. TREC systems are commonly regarded as reference points for effectiveness comparison. Yet, the papers accompanying them have less strict requirements than peer-reviewed publications, which can make reproducibility challenging. Our results indicate that key practical information is indeed missing. While the results can be reproduced within a 19% relative margin with respect to the main evaluation measure, the relative difference between the baseline and the top performing approach shrinks from the reported 18% to 5%. Additionally, we report on a new set of experiments aimed at understanding the impact of various pipeline components. We show that end-to-end system performance can indeed benefit from advanced retrieval techniques in either stage of a two-stage retrieval pipeline. We also measure the impact of the dataset used for fine-tuning the query rewriter and find that employing different query rewriting methods in different stages of the retrieval pipeline might be beneficial. Moreover, these results are shown to generalize across the 2020 and 2021 editions of the track. We conclude our study with a list of lessons learned and practical suggestions.
DAGFiNN: A Conversational Conference Assistant
Nov 29, 2022


DAGFiNN is a conversational conference assistant that can be made available for a given conference both as a chatbot on the website and as a Furhat robot physically exhibited at the conference venue. Conference participants can interact with the assistant to get advice on various questions, ranging from where to eat in the city or how to get to the airport to which sessions we recommend them to attend based on the information we have about them. The overall objective is to provide a personalized and engaging experience and allow users to ask a broad range of questions that naturally arise before and during the conference.
ProtagonistTagger -- a Tool for Entity Linkage of Persons in Texts from Various Languages and Domains
Mar 13, 2022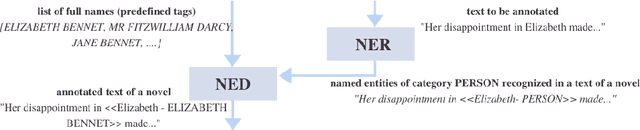


Named entities recognition (NER) and disambiguation (NED) can add semantic context to the recognized named entities in texts. Named entity linkage in texts, regardless of a domain, provides links between the entities mentioned in unstructured texts and individual instances of real-world objects. In this poster, we present a tool - protagonistTagger - for person NER and NED in texts. The tool was tested on texts extracted from classic English novels and Polish Internet news. The tool's performance (both precision and recall) fluctuates between 78% and even 88%.