 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ecosystem for Personal Knowledge Graphs: A Survey and Research Roadmap
Apr 19, 2023


This paper presents an ecosystem for personal knowledge graphs (PKG), commonly defined as resources of structured information about entities related to an individual, their attributes, and the relations between them. PKGs are a key enabler of secure and sophisticated personal data management and personalized services. However, there are challenges that need to be addressed before PKGs can achieve widespread adoption. One of the fundamental challenges is the very definition of what constitutes a PKG, as there are multiple interpretations of the term. We propose our own definition of a PKG, emphasizing the aspects of (1) data ownership by a single individual and (2) the delivery of personalized services as the primary purpose. We further argue that a holistic view of PKGs is needed to unlock their full potential, and propose a unified framework for PKGs, where the PKG is a part of a larger ecosystem with clear interfaces towards data services and data sources. A comprehensive survey and synthesis of existing work is conducted, with a mapping of the surveyed work into the proposed unified ecosystem. Finally, we identify open challenges and research opportunities for the ecosystem as a whole, as well as for the specific aspects of PKGs, which include population, representation and management, and utilization.
Would You Ask it that Way? Measuring and Improving Question Naturalness for Knowledge Graph Question Answering
May 25, 2022
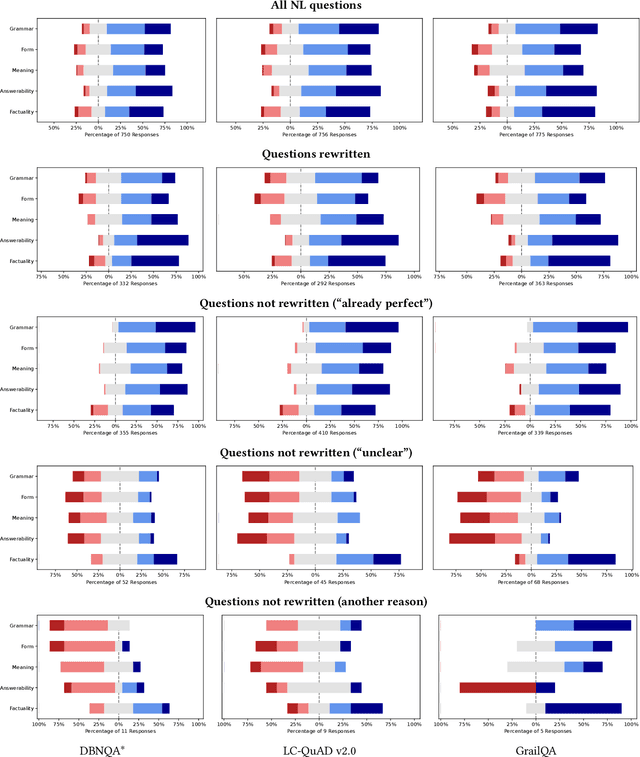
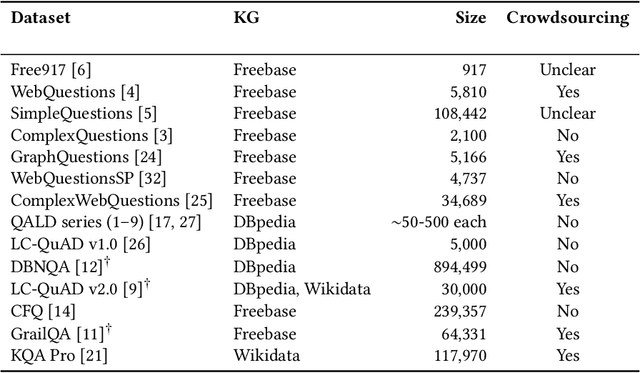
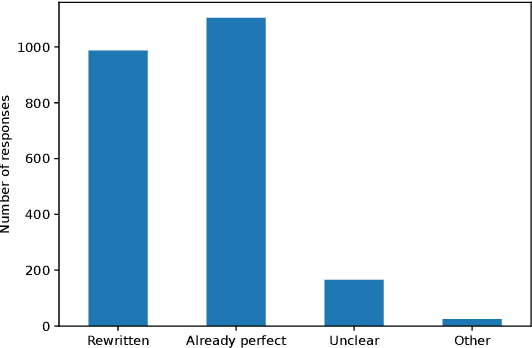
Knowledge graph question answering (KGQA) facilitates information access by leveraging structured data without requiring formal query language expertise from the user. Instead, users can express their information needs by simply asking their questions in natural language (NL). Datasets used to train KGQA models that would provide such a service are expensive to construct, both in terms of expert and crowdsourced labor. Typically, crowdsourced labor is used to improve template-based pseudo-natural questions generated from formal queries. However, the resulting datasets often fall short of representing genuinely natural and fluent language. In the present work, we investigate ways to characterize and remedy these shortcomings. We create the IQN-KGQA test collection by sampling questions from existing KGQA datasets and evaluating them with regards to five different aspects of naturalness. Then, the questions are rewritten to improve their fluency. Finally, the performance of existing KGQA models is compared on the original and rewritten versions of the NL questions. We find that some KGQA systems fare worse when presented with more realistic formulations of NL questions. The IQN-KGQA test collection is a resource to help evaluate KGQA systems in a more realistic setting. The construction of this test collection also sheds light on the challenges of constructing large-scale KGQA datasets with genuinely NL questions.
Impact of Training Dataset Size on Neural Answer Selection Models
Jan 29, 2019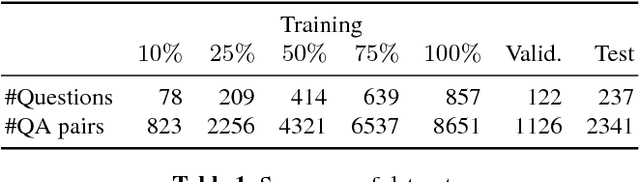
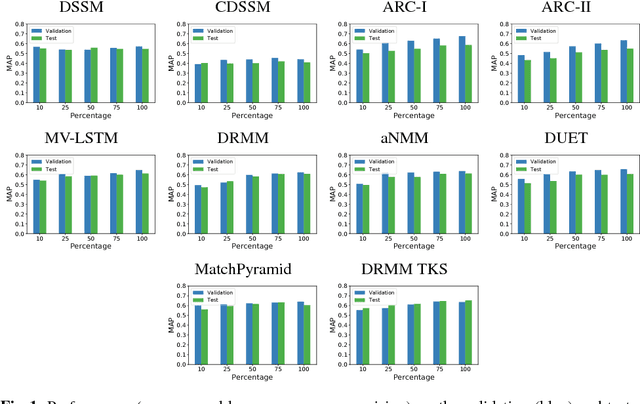

It is held as a truism that deep neural networks require large datasets to train effective models. However, large datasets, especially with high-quality labels, can be expensive to obtain. This study sets out to investigate (i) how large a dataset must be to train well-performing models, and (ii) what impact can be shown from fractional changes to the dataset size. A practical method to investigate these questions is to train a collection of deep neural answer selection models using fractional subsets of varying sizes of an initial dataset. We observe that dataset size has a conspicuous lack of effect on the training of some of these models, bringing the underlying algorithms into question.