 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWould You Ask it that Way? Measuring and Improving Question Naturalness for Knowledge Graph Question Answering
Paper and Code

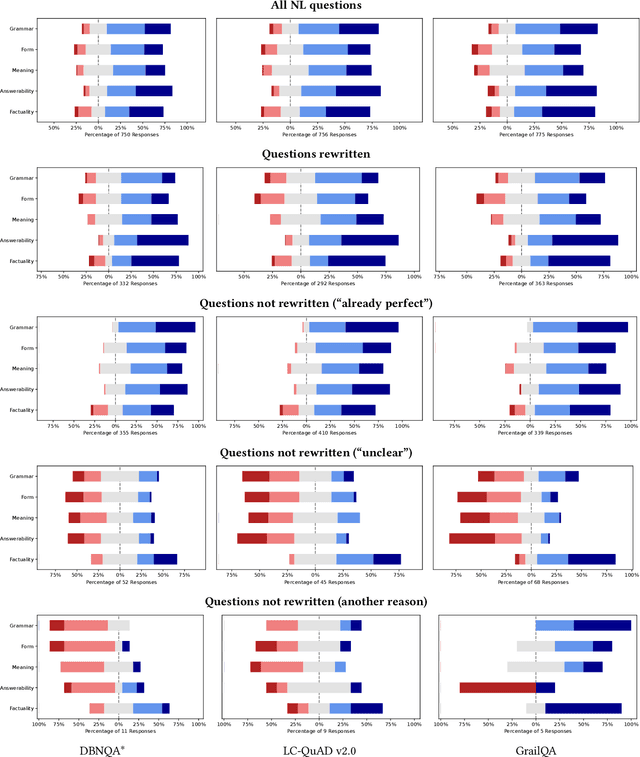
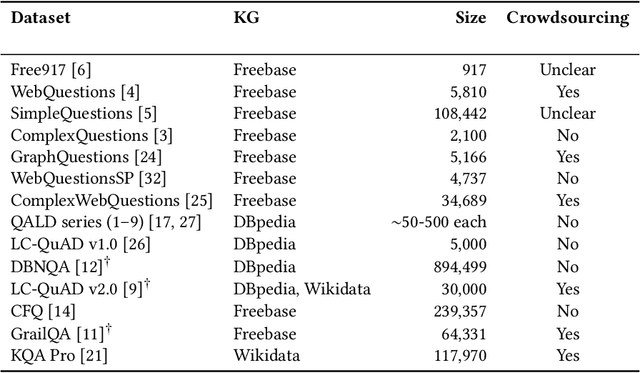
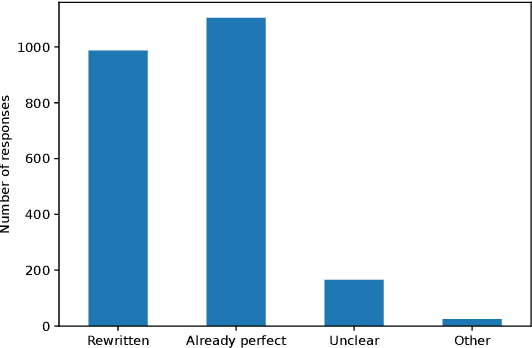
Knowledge graph question answering (KGQA) facilitates information access by leveraging structured data without requiring formal query language expertise from the user. Instead, users can express their information needs by simply asking their questions in natural language (NL). Datasets used to train KGQA models that would provide such a service are expensive to construct, both in terms of expert and crowdsourced labor. Typically, crowdsourced labor is used to improve template-based pseudo-natural questions generated from formal queries. However, the resulting datasets often fall short of representing genuinely natural and fluent language. In the present work, we investigate ways to characterize and remedy these shortcomings. We create the IQN-KGQA test collection by sampling questions from existing KGQA datasets and evaluating them with regards to five different aspects of naturalness. Then, the questions are rewritten to improve their fluency. Finally, the performance of existing KGQA models is compared on the original and rewritten versions of the NL questions. We find that some KGQA systems fare worse when presented with more realistic formulations of NL questions. The IQN-KGQA test collection is a resource to help evaluate KGQA systems in a more realistic setting. The construction of this test collection also sheds light on the challenges of constructing large-scale KGQA datasets with genuinely NL questions.