 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal graph models fail to capture global temporal dynamics
Sep 29, 2023
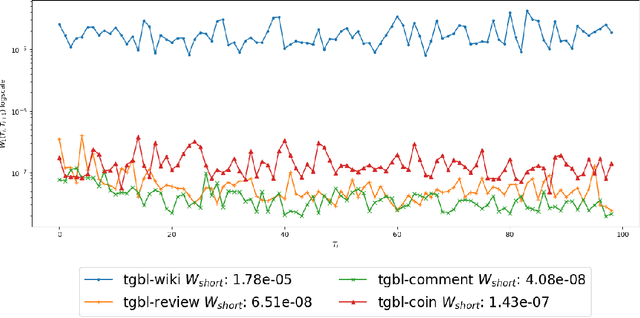

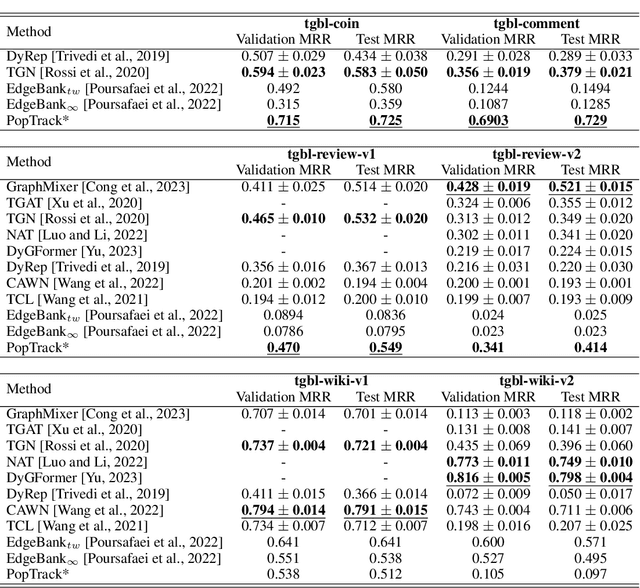
A recently released Temporal Graph Benchmark is analyzed in the context of Dynamic Link Property Prediction. We outline our observations and propose a trivial optimization-free baseline of "recently popular nodes" outperforming other methods on medium and large-size datasets in the Temporal Graph Benchmark. We propose two measures based on Wasserstein distance which can quantify the strength of short-term and long-term global dynamics of datasets. By analyzing our unexpectedly strong baseline, we show how standard negative sampling evaluation can be unsuitable for datasets with strong temporal dynamics. We also show how simple negative-sampling can lead to model degeneration during training, resulting in impossible to rank, fully saturated predictions of temporal graph networks. We propose improved negative sampling schemes for both training and evaluation and prove their usefulness. We conduct a comparison with a model trained non-contrastively without negative sampling. Our results provide a challenging baseline and indicate that temporal graph network architectures need deep rethinking for usage in problems with significant global dynamics, such as social media, cryptocurrency markets or e-commerce. We open-source the code for baselines, measures and proposed negative sampling schemes.
Synerise at RecSys 2021: Twitter user engagement prediction with a fast neural model
Sep 28, 2021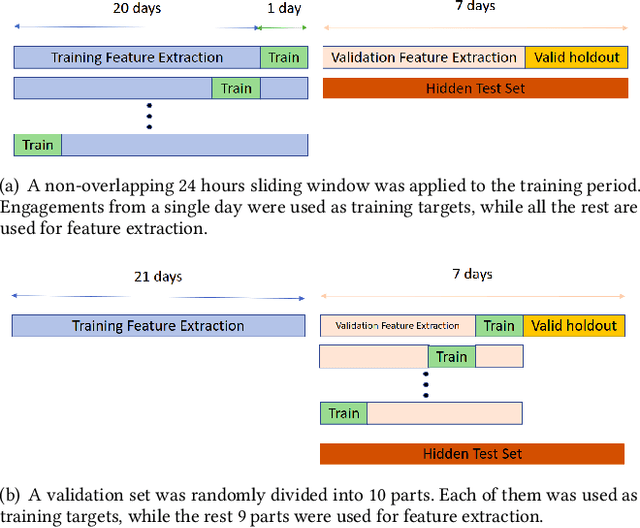

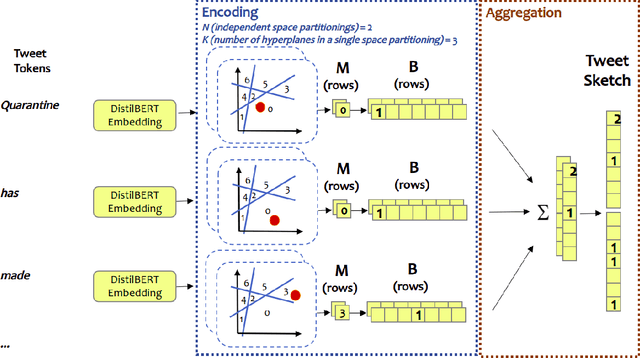

In this paper we present our 2nd place solution to ACM RecSys 2021 Challenge organized by Twitter. The challenge aims to predict user engagement for a set of tweets, offering an exceptionally large data set of 1 billion data points sampled from over four weeks of real Twitter interactions. Each data point contains multiple sources of information, such as tweet text along with engagement features, user features, and tweet features. The challenge brings the problem close to a real production environment by introducing strict latency constraints in the model evaluation phase: the average inference time for single tweet engagement prediction is limited to 6ms on a single CPU core with 64GB memory. Our proposed model relies on extensive feature engineering performed with methods such as the Efficient Manifold Density Estimator (EMDE) - our previously introduced algorithm based on Locality Sensitive Hashing method, and novel Fourier Feature Encoding, among others. In total, we create numerous features describing a user's Twitter account status and the content of a tweet. In order to adhere to the strict latency constraints, the underlying model is a simple residual feed-forward neural network. The system is a variation of our previous methods which proved successful in KDD Cup 2021, WSDM Challenge 2021, and SIGIR eCom Challenge 2020. We release the source code at: https://github.com/Synerise/recsys-challenge-2021
Modeling Multi-Destination Trips with Sketch-Based Model
Mar 04, 2021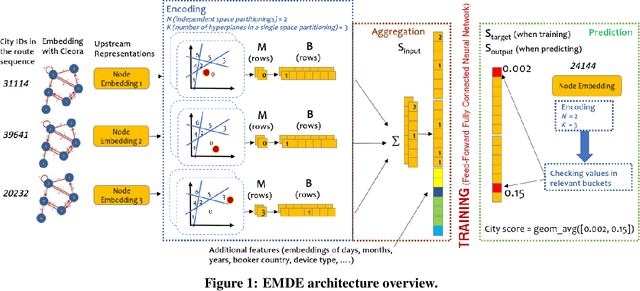
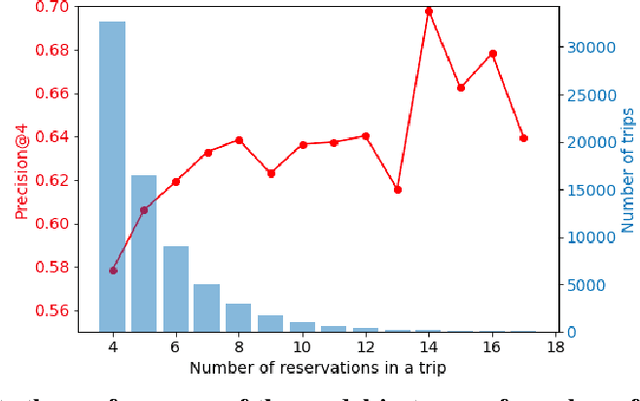

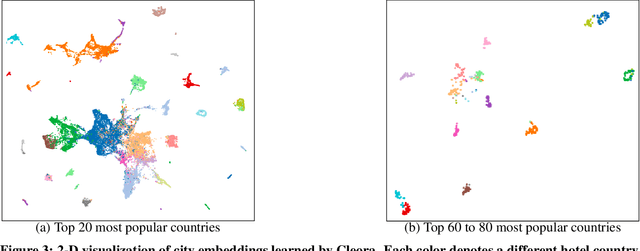
The recently proposed EMDE (Efficient Manifold Density Estimator) model achieves state of-the-art results in session-based recommendation. In this work we explore its application to Booking Data Challenge competition. The aim of the challenge is to make the best recommendation for the next destination of a user trip, based on dataset with millions of real anonymized accommodation reservations. We achieve 2nd place in this competition. First, we use Cleora - our graph embedding method - to represent cities as a directed graph and learn their vector representation. Next, we apply EMDE to predict the next user destination based on previously visited cities and some features associated with each trip. We release the source code at: https://github.com/Synerise/booking-challenge.
I know why you like this movie: Interpretable Efficient Multimodal Recommender
Jun 09, 2020
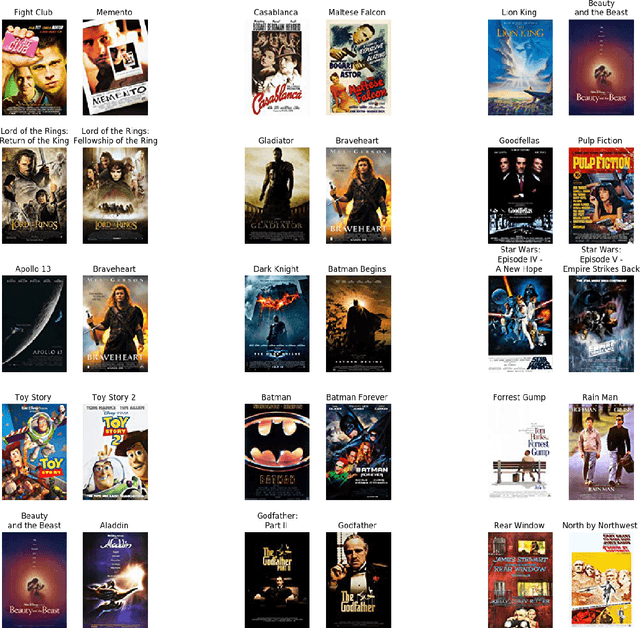


Recently, the Efficient Manifold Density Estimator (EMDE) model has been introduced. The model exploits Local Sensitive Hashing and Count-Min Sketch algorithms, combining them with a neural network to achieve state-of-the-art results on multiple recommender datasets. However, this model ingests a compressed joint representation of all input items for each user/session, so calculating attributions for separate items via gradient-based methods seems not applicable. We prove that interpreting this model in a white-box setting is possible thanks to the properties of EMDE item retrieval method. By exploiting multimodal flexibility of this model, we obtain meaningful results showing the influence of multiple modalities: text, categorical features, and images, on movie recommendation output.
An efficient manifold density estimator for all recommendation systems
Jun 05, 2020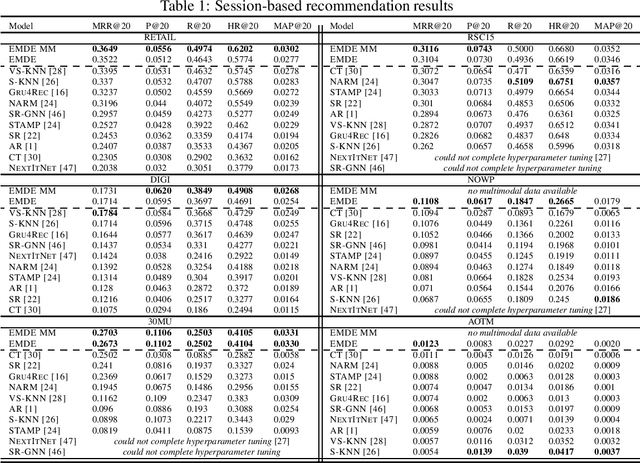
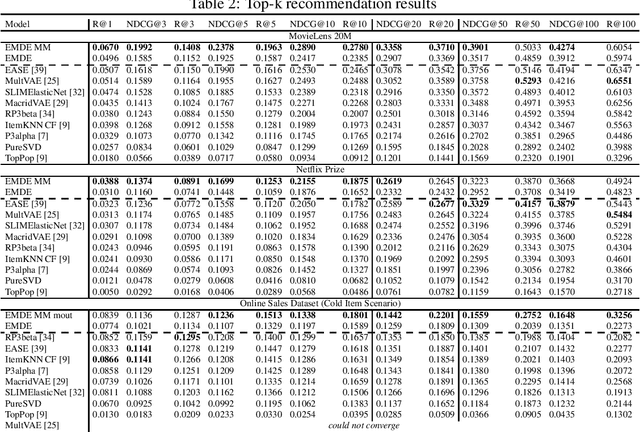

Many unsupervised representation learning methods belong to the class of similarity learning models. While various modality-specific approaches exist for different types of data, a core property of many methods is that representations of similar inputs are close under some similarity function. We propose EMDE (Efficient Manifold Density Estimator) - a framework utilizing arbitrary vector representations with the property of local similarity to succinctly represent smooth probability densities on Riemannian manifolds. Our approximate representation has the desirable properties of being fixed-size and having simple additive compositionality, thus being especially amenable to treatment with neural networks - both as input and output format, producing efficient conditional estimators. We generalize and reformulate the problem of multi-modal recommendations as conditional, weighted density estimation on manifolds. Our approach allows for trivial inclusion of multiple interaction types, modalities of data as well as interaction strengths for any recommendation setting. Applying EMDE to both top-k and session-based recommendation settings, we establish new state-of-the-art results on multiple open datasets in both uni-modal and multi-modal settings. We release the source code and our own real-world dataset of e-commerce product purchases, with special focus on modeling of the item cold-start problem.
Frustratingly Short Attention Spans in Neural Language Modeling
Feb 15, 2017

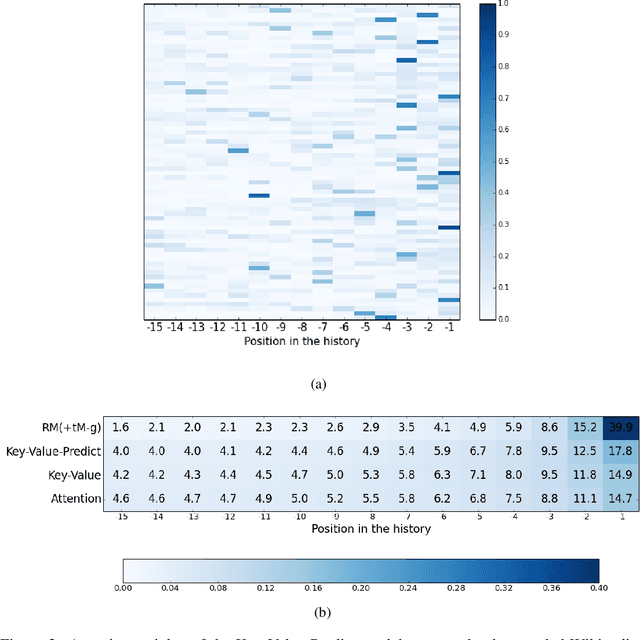
Neural language models predict the next token using a latent representation of the immediate token history. Recently, various methods for augmenting neural language models with an attention mechanism over a differentiable memory have been proposed. For predicting the next token, these models query information from a memory of the recent history which can facilitate learning mid- and long-range dependencies. However, conventional attention mechanisms used in memory-augmented neural language models produce a single output vector per time step. This vector is used both for predicting the next token as well as for the key and value of a differentiable memory of a token history. In this paper, we propose a neural language model with a key-value attention mechanism that outputs separate representations for the key and value of a differentiable memory, as well as for encoding the next-word distribution. This model outperforms existing memory-augmented neural language models on two corpora. Yet, we found that our method mainly utilizes a memory of the five most recent output representations. This led to the unexpected main finding that a much simpler model based only on the concatenation of recent output representations from previous time steps is on par with more sophisticated memory-augmented neural language models.