 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAS-Orchestra: Understanding and Improving Multi-Agent Reasoning Through Holistic Orchestration and Controlled Benchmarks
Jan 21, 2026While multi-agent systems (MAS) promise elevated intelligence through coordination of agents, current approaches to automatic MAS design under-deliver. Such shortcomings stem from two key factors: (1) methodological complexity - agent orchestration is performed using sequential, code-level execution that limits global system-level holistic reasoning and scales poorly with agent complexity - and (2) efficacy uncertainty - MAS are deployed without understanding if there are tangible benefits compared to single-agent systems (SAS). We propose MAS-Orchestra, a training-time framework that formulates MAS orchestration as a function-calling reinforcement learning problem with holistic orchestration, generating an entire MAS at once. In MAS-Orchestra, complex, goal-oriented sub-agents are abstracted as callable functions, enabling global reasoning over system structure while hiding internal execution details. To rigorously study when and why MAS are beneficial, we introduce MASBENCH, a controlled benchmark that characterizes tasks along five axes: Depth, Horizon, Breadth, Parallel, and Robustness. Our analysis reveals that MAS gains depend critically on task structure, verification protocols, and the capabilities of both orchestrator and sub-agents, rather than holding universally. Guided by these insights, MAS-Orchestra achieves consistent improvements on public benchmarks including mathematical reasoning, multi-hop QA, and search-based QA. Together, MAS-Orchestra and MASBENCH enable better training and understanding of MAS in the pursuit of multi-agent intelligence.
MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers
Aug 20, 2025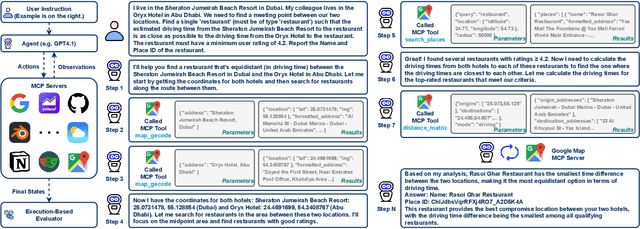
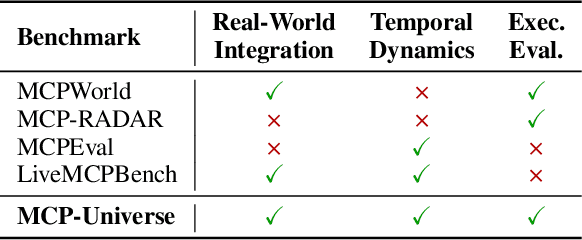
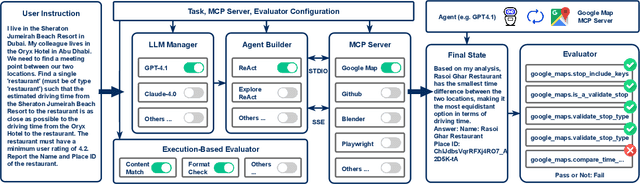
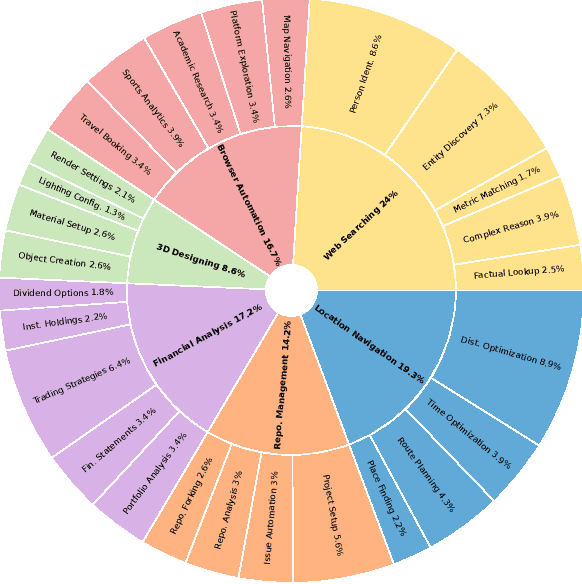
The Model Context Protocol has emerged as a transformative standard for connecting large language models to external data sources and tools, rapidly gaining adoption across major AI providers and development platforms. However, existing benchmarks are overly simplistic and fail to capture real application challenges such as long-horizon reasoning and large, unfamiliar tool spaces. To address this critical gap, we introduce MCP-Universe, the first comprehensive benchmark specifically designed to evaluate LLMs in realistic and hard tasks through interaction with real-world MCP servers. Our benchmark encompasses 6 core domains spanning 11 different MCP servers: Location Navigation, Repository Management, Financial Analysis, 3D Design, Browser Automation, and Web Searching. To ensure rigorous evaluation, we implement execution-based evaluators, including format evaluators for agent format compliance, static evaluators for time-invariant content matching, and dynamic evaluators that automatically retrieve real-time ground truth for temporally sensitive tasks. Through extensive evaluation of leading LLMs, we find that even SOTA models such as GPT-5 (43.72%), Grok-4 (33.33%) and Claude-4.0-Sonnet (29.44%) exhibit significant performance limitations. In addition, our benchmark poses a significant long-context challenge for LLM agents, as the number of input tokens increases rapidly with the number of interaction steps. Moreover, it introduces an unknown-tools challenge, as LLM agents often lack familiarity with the precise usage of the MCP servers. Notably, enterprise-level agents like Cursor cannot achieve better performance than standard ReAct frameworks. Beyond evaluation, we open-source our extensible evaluation framework with UI support, enabling researchers and practitioners to seamlessly integrate new agents and MCP servers while fostering innovation in the rapidly evolving MCP ecosystem.
RakutenAI-7B: Extending Large Language Models for Japanese
Mar 21, 2024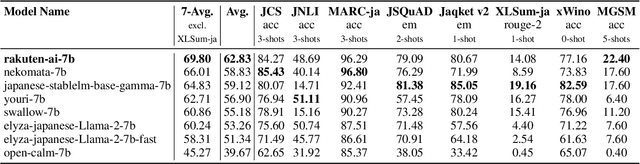
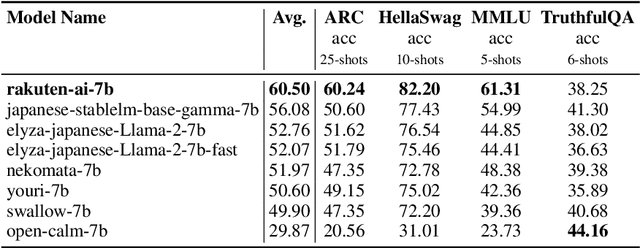
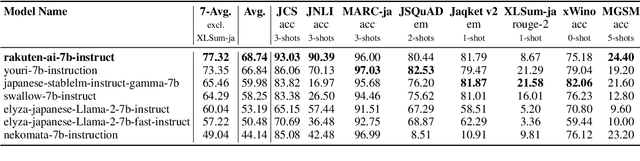
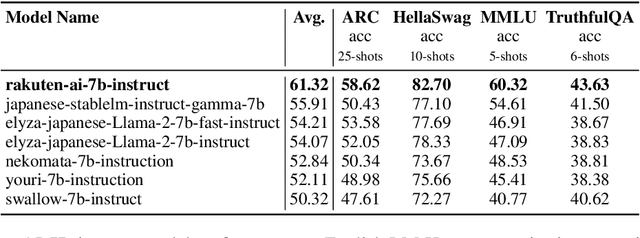
We introduce RakutenAI-7B, a suite of Japanese-oriented large language models that achieve the best performance on the Japanese LM Harness benchmarks among the open 7B models. Along with the foundation model, we release instruction- and chat-tuned models, RakutenAI-7B-instruct and RakutenAI-7B-chat respectively, under the Apache 2.0 license.
Dynamic Scheduled Sampling with Imitation Loss for Neural Text Generation
Jan 31, 2023State-of-the-art neural text generation models are typically trained to maximize the likelihood of each token in the ground-truth sequence conditioned on the previous target tokens. However, during inference, the model needs to make a prediction conditioned on the tokens generated by itself. This train-test discrepancy is referred to as exposure bias. Scheduled sampling is a curriculum learning strategy that gradually exposes the model to its own predictions during training to mitigate this bias. Most of the proposed approaches design a scheduler based on training steps, which generally requires careful tuning depending on the training setup. In this work, we introduce Dynamic Scheduled Sampling with Imitation Loss (DySI), which maintains the schedule based solely on the training time accuracy, while enhancing the curriculum learning by introducing an imitation loss, which attempts to make the behavior of the decoder indistinguishable from the behavior of a teacher-forced decoder. DySI is universally applicable across training setups with minimal tuning. Extensive experiments and analysis show that DySI not only achieves notable improvements on standard machine translation benchmarks, but also significantly improves the robustness of other text generation models.
Rethinking Self-Supervision Objectives for Generalizable Coherence Modeling
Oct 14, 2021
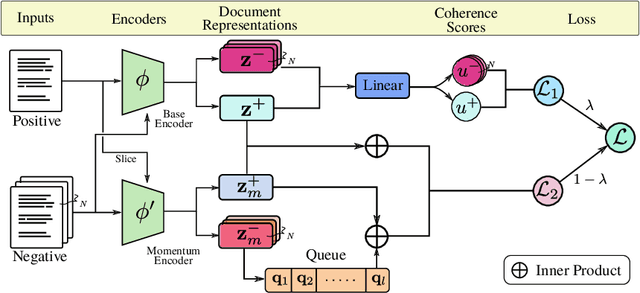
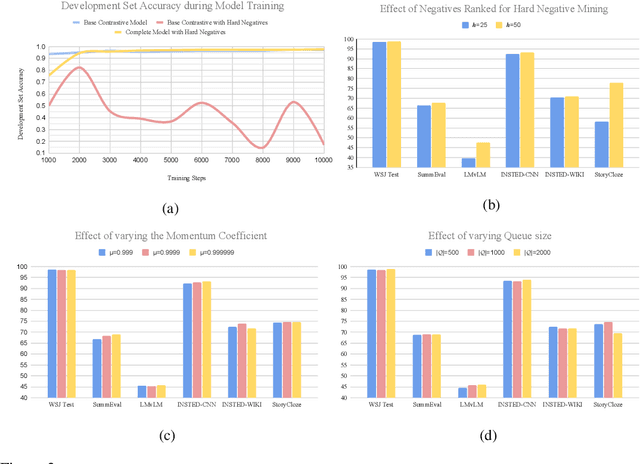

Although large-scale pre-trained neural models have shown impressive performances in a variety of tasks, their ability to generate coherent text that appropriately models discourse phenomena is harder to evaluate and less understood. Given the claims of improved text generation quality across various systems, we consider the coherence evaluation of machine generated text to be one of the principal applications of coherence models that needs to be investigated. We explore training data and self-supervision objectives that result in a model that generalizes well across tasks and can be used off-the-shelf to perform such evaluations. Prior work in neural coherence modeling has primarily focused on devising new architectures, and trained the model to distinguish coherent and incoherent text through pairwise self-supervision on the permuted documents task. We instead use a basic model architecture and show significant improvements over state of the art within the same training regime. We then design a harder self-supervision objective by increasing the ratio of negative samples within a contrastive learning setup, and enhance the model further through automatic hard negative mining coupled with a large global negative queue encoded by a momentum encoder. We show empirically that increasing the density of negative samples improves the basic model, and using a global negative queue further improves and stabilizes the model while training with hard negative samples. We evaluate the coherence model on task-independent test sets that resemble real-world use cases and show significant improvements in coherence evaluations of downstream applications.
Pronoun-Targeted Fine-tuning for NMT with Hybrid Losses
Oct 15, 2020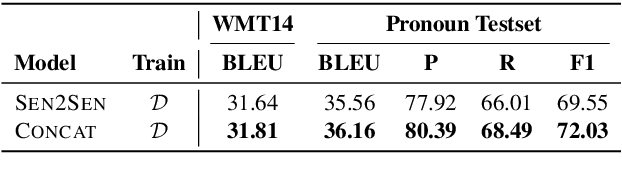
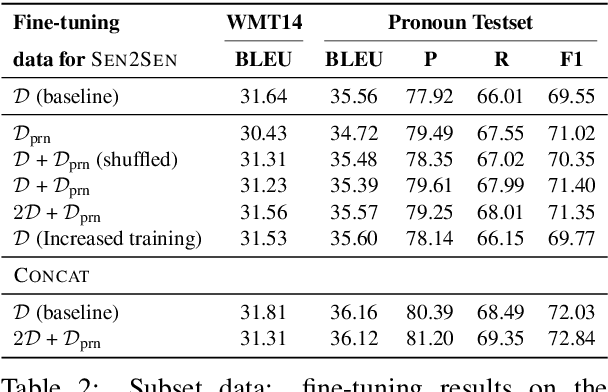


Popular Neural Machine Translation model training uses strategies like backtranslation to improve BLEU scores, requiring large amounts of additional data and training. We introduce a class of conditional generative-discriminative hybrid losses that we use to fine-tune a trained machine translation model. Through a combination of targeted fine-tuning objectives and intuitive re-use of the training data the model has failed to adequately learn from, we improve the model performance of both a sentence-level and a contextual model without using any additional data. We target the improvement of pronoun translations through our fine-tuning and evaluate our models on a pronoun benchmark testset. Our sentence-level model shows a 0.5 BLEU improvement on both the WMT14 and the IWSLT13 De-En testsets, while our contextual model achieves the best results, improving from 31.81 to 32 BLEU on WMT14 De-En testset, and from 32.10 to 33.13 on the IWSLT13 De-En testset, with corresponding improvements in pronoun translation. We further show the generalizability of our method by reproducing the improvements on two additional language pairs, Fr-En and Cs-En. Code available at <https://github.com/ntunlp/pronoun-finetuning>.
CohEval: Benchmarking Coherence Models
Apr 30, 2020
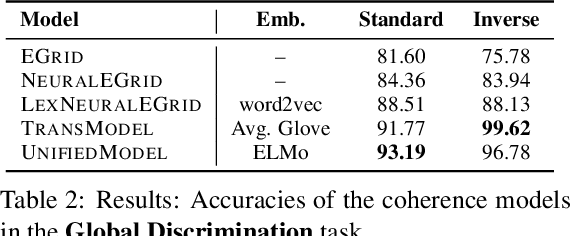
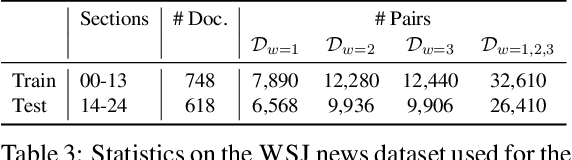
Although coherence modeling has come a long way in developing novel models, their evaluation on downstream applications has largely been neglected. With the advancements made by neural approaches in applications such as machine translation, text summarization and dialogue systems, the need for standard coherence evaluation is now more crucial than ever. In this paper, we propose to benchmark coherence models on a number of synthetic and downstream tasks. In particular, we evaluate well-known traditional and neural coherence models on sentence ordering tasks, and also on three downstream applications including coherence evaluation for machine translation, summarization and next utterance prediction. We also show model produced rankings for pre-trained language model outputs as another use-case. Our results demonstrate a weak correlation between the model performances in the synthetic tasks and the downstream applications, motivating alternate evaluation methods for coherence models. This work has led us to create a leaderboard to foster further research in coherence modeling.
Can Your Context-Aware MT System Pass the DiP Benchmark Tests? : Evaluation Benchmarks for Discourse Phenomena in Machine Translation
Apr 30, 2020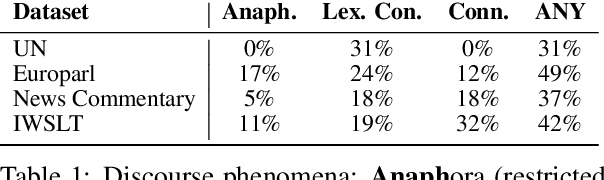

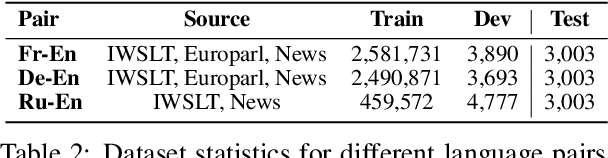

Despite increasing instances of machine translation (MT) systems including contextual information, the evidence for translation quality improvement is sparse, especially for discourse phenomena. Popular metrics like BLEU are not expressive or sensitive enough to capture quality improvements or drops that are minor in size but significant in perception. We introduce the first of their kind MT benchmark datasets that aim to track and hail improvements across four main discourse phenomena: anaphora, lexical consistency, coherence and readability, and discourse connective translation. We also introduce evaluation methods for these tasks, and evaluate several baseline MT systems on the curated datasets. Surprisingly, we find that existing context-aware models do not improve discourse-related translations consistently across languages and phenomena.
Zero-Resource Cross-Lingual Named Entity Recognition
Nov 22, 2019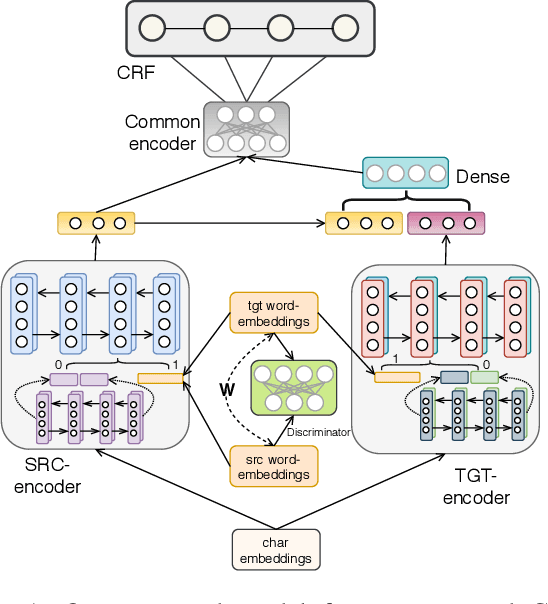
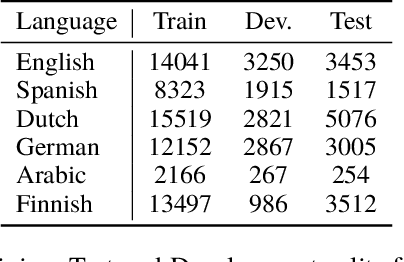


Recently, neural methods have achieved state-of-the-art (SOTA) results in Named Entity Recognition (NER) tasks for many languages without the need for manually crafted features. However, these models still require manually annotated training data, which is not available for many languages. In this paper, we propose an unsupervised cross-lingual NER model that can transfer NER knowledge from one language to another in a completely unsupervised way without relying on any bilingual dictionary or parallel data. Our model achieves this through word-level adversarial learning and augmented fine-tuning with parameter sharing and feature augmentation. Experiments on five different languages demonstrate the effectiveness of our approach, outperforming existing models by a good margin and setting a new SOTA for each language pair.
Evaluating Pronominal Anaphora in Machine Translation: An Evaluation Measure and a Test Suite
Aug 31, 2019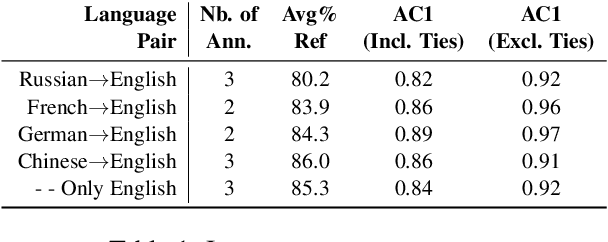

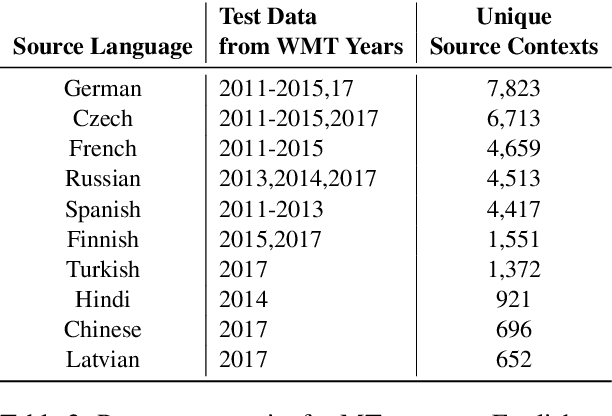
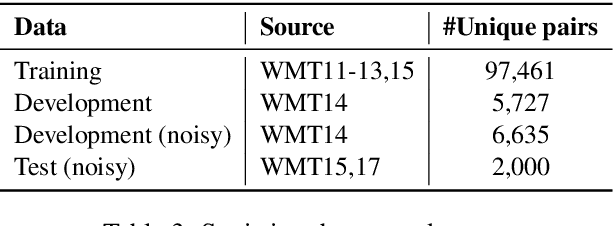
The ongoing neural revolution in machine translation has made it easier to model larger contexts beyond the sentence-level, which can potentially help resolve some discourse-level ambiguities such as pronominal anaphora, thus enabling better translations. Unfortunately, even when the resulting improvements are seen as substantial by humans, they remain virtually unnoticed by traditional automatic evaluation measures like BLEU, as only a few words end up being affected. Thus, specialized evaluation measures are needed. With this aim in mind, we contribute an extensive, targeted dataset that can be used as a test suite for pronoun translation, covering multiple source languages and different pronoun errors drawn from real system translations, for English. We further propose an evaluation measure to differentiate good and bad pronoun translations. We also conduct a user study to report correlations with human judgments.