 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePronoun-Targeted Fine-tuning for NMT with Hybrid Losses
Oct 15, 2020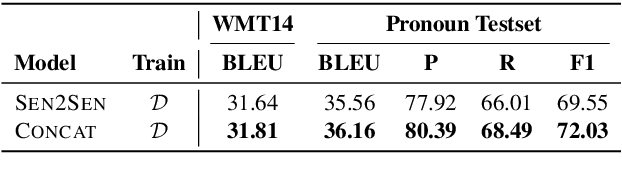
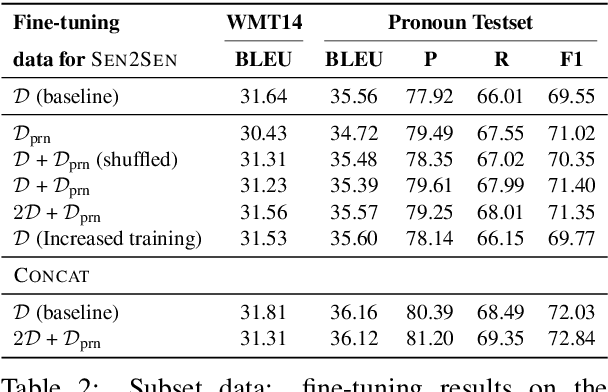


Popular Neural Machine Translation model training uses strategies like backtranslation to improve BLEU scores, requiring large amounts of additional data and training. We introduce a class of conditional generative-discriminative hybrid losses that we use to fine-tune a trained machine translation model. Through a combination of targeted fine-tuning objectives and intuitive re-use of the training data the model has failed to adequately learn from, we improve the model performance of both a sentence-level and a contextual model without using any additional data. We target the improvement of pronoun translations through our fine-tuning and evaluate our models on a pronoun benchmark testset. Our sentence-level model shows a 0.5 BLEU improvement on both the WMT14 and the IWSLT13 De-En testsets, while our contextual model achieves the best results, improving from 31.81 to 32 BLEU on WMT14 De-En testset, and from 32.10 to 33.13 on the IWSLT13 De-En testset, with corresponding improvements in pronoun translation. We further show the generalizability of our method by reproducing the improvements on two additional language pairs, Fr-En and Cs-En. Code available at <https://github.com/ntunlp/pronoun-finetuning>.