 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCohEval: Benchmarking Coherence Models
Paper and Code

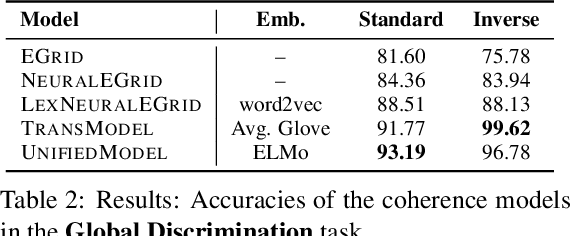
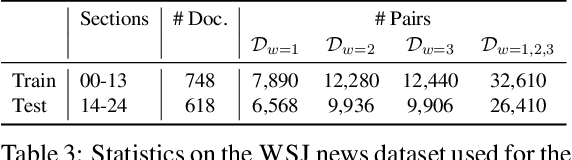
Although coherence modeling has come a long way in developing novel models, their evaluation on downstream applications has largely been neglected. With the advancements made by neural approaches in applications such as machine translation, text summarization and dialogue systems, the need for standard coherence evaluation is now more crucial than ever. In this paper, we propose to benchmark coherence models on a number of synthetic and downstream tasks. In particular, we evaluate well-known traditional and neural coherence models on sentence ordering tasks, and also on three downstream applications including coherence evaluation for machine translation, summarization and next utterance prediction. We also show model produced rankings for pre-trained language model outputs as another use-case. Our results demonstrate a weak correlation between the model performances in the synthetic tasks and the downstream applications, motivating alternate evaluation methods for coherence models. This work has led us to create a leaderboard to foster further research in coherence modeling.