 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Pronominal Anaphora in Machine Translation: An Evaluation Measure and a Test Suite
Aug 31, 2019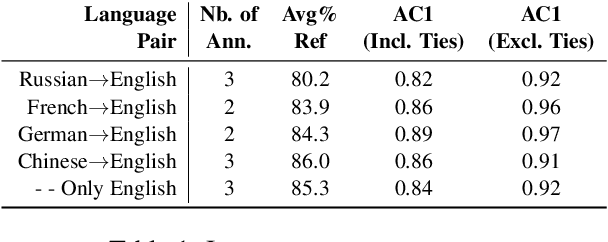

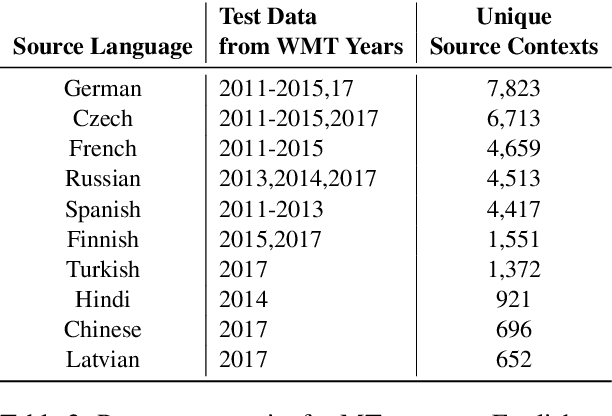
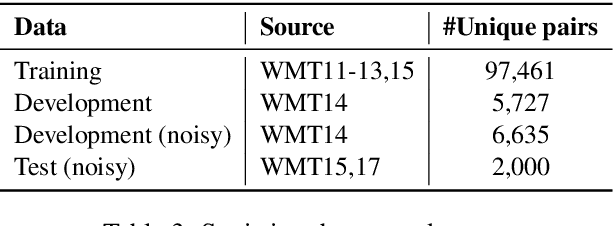
The ongoing neural revolution in machine translation has made it easier to model larger contexts beyond the sentence-level, which can potentially help resolve some discourse-level ambiguities such as pronominal anaphora, thus enabling better translations. Unfortunately, even when the resulting improvements are seen as substantial by humans, they remain virtually unnoticed by traditional automatic evaluation measures like BLEU, as only a few words end up being affected. Thus, specialized evaluation measures are needed. With this aim in mind, we contribute an extensive, targeted dataset that can be used as a test suite for pronoun translation, covering multiple source languages and different pronoun errors drawn from real system translations, for English. We further propose an evaluation measure to differentiate good and bad pronoun translations. We also conduct a user study to report correlations with human judgments.
Enabling Medical Translation for Low-Resource Languages
Oct 09, 2016



We present research towards bridging the language gap between migrant workers in Qatar and medical staff. In particular, we present the first steps towards the development of a real-world Hindi-English machine translation system for doctor-patient communication. As this is a low-resource language pair, especially for speech and for the medical domain, our initial focus has been on gathering suitable training data from various sources. We applied a variety of methods ranging from fully automatic extraction from the Web to manual annotation of test data. Moreover, we developed a method for automatically augmenting the training data with synthetically generated variants, which yielded a very sizable improvement of more than 3 BLEU points absolute.
Multilingual person name recognition and transliteration
Sep 11, 2006
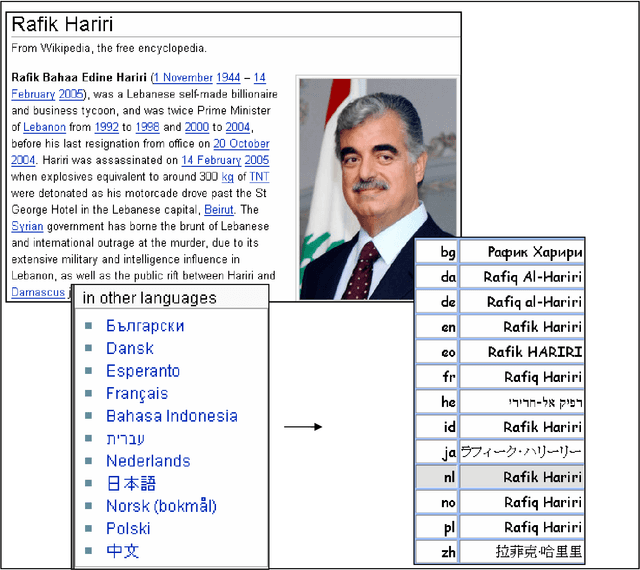
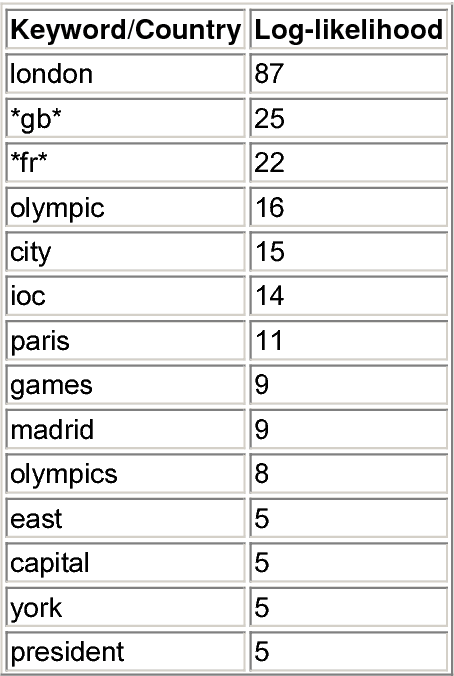
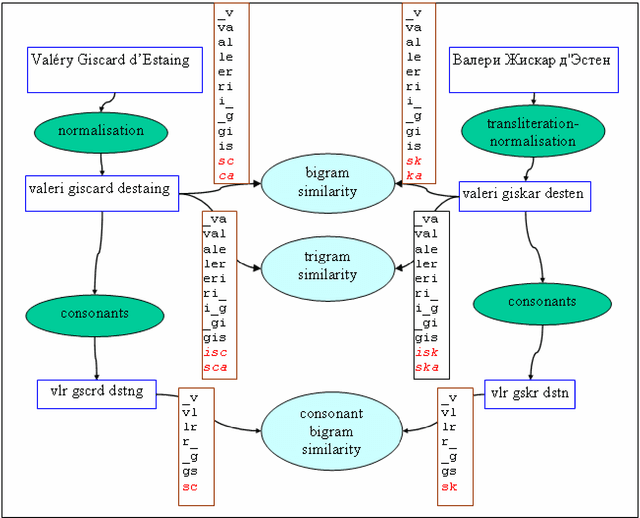
We present an exploratory tool that extracts person names from multilingual news collections, matches name variants referring to the same person, and infers relationships between people based on the co-occurrence of their names in related news. A novel feature is the matching of name variants across languages and writing systems, including names written with the Greek, Cyrillic and Arabic writing system. Due to our highly multilingual setting, we use an internal standard representation for name representation and matching, instead of adopting the traditional bilingual approach to transliteration. This work is part of the news analysis system NewsExplorer that clusters an average of 25,000 news articles per day to detect related news within the same and across different languages.
* Explains the technology behind the JRC's NewsExplorer application, which is freely accessible at http://press.jrc.it/NewsExplorer