 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA tool set for the quick and efficient exploration of large document collections
Sep 12, 2006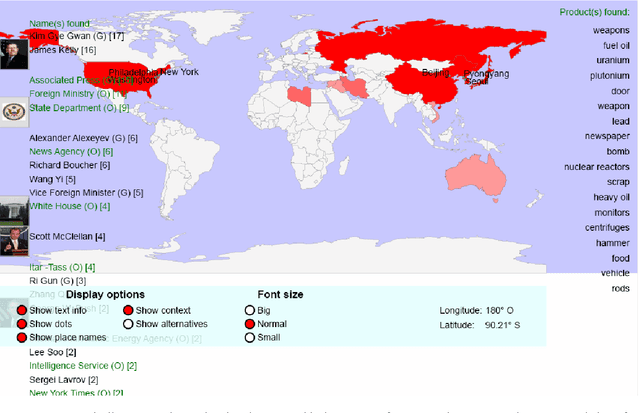



We are presenting a set of multilingual text analysis tools that can help analysts in any field to explore large document collections quickly in order to determine whether the documents contain information of interest, and to find the relevant text passages. The automatic tool, which currently exists as a fully functional prototype, is expected to be particularly useful when users repeatedly have to sieve through large collections of documents such as those downloaded automatically from the internet. The proposed system takes a whole document collection as input. It first carries out some automatic analysis tasks (named entity recognition, geo-coding, clustering, term extraction), annotates the texts with the generated meta-information and stores the meta-information in a database. The system then generates a zoomable and hyperlinked geographic map enhanced with information on entities and terms found. When the system is used on a regular basis, it builds up a historical database that contains information on which names have been mentioned together with which other names or places, and users can query this database to retrieve information extracted in the past.
* 10 pages
Building and displaying name relations using automatic unsupervised analysis of newspaper articles
Sep 12, 2006
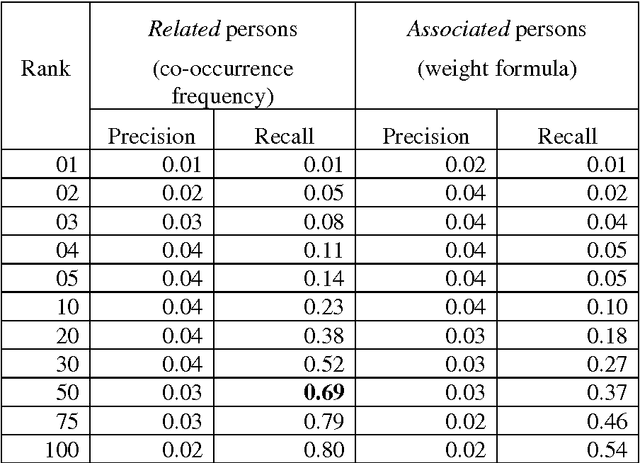

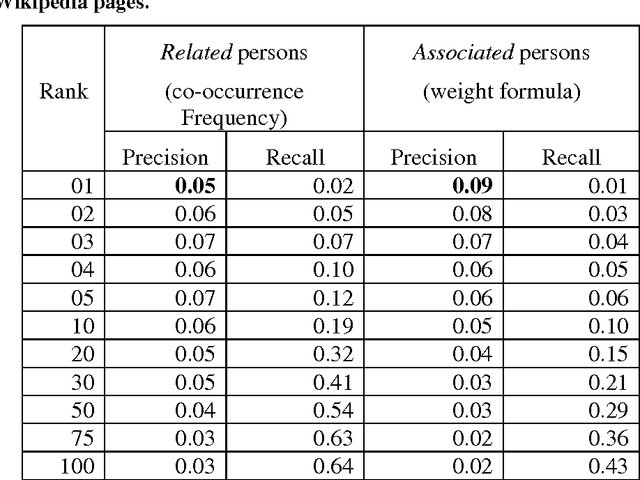
We present a tool that, from automatically recognised names, tries to infer inter-person relations in order to present associated people on maps. Based on an in-house Named Entity Recognition tool, applied on clusters of an average of 15,000 news articles per day, in 15 different languages, we build a knowledge base that allows extracting statistical co-occurrences of persons and visualising them on a per-person page or in various graphs.
* Builds upon the recognition of person names described in paper cs.CL/0609051. Resulting person relations can be explored in the multilingual online application NewsExplorer at http://press.jrc.it/NewsExplorer . 12 pages
Geocoding multilingual texts: Recognition, disambiguation and visualisation
Sep 12, 2006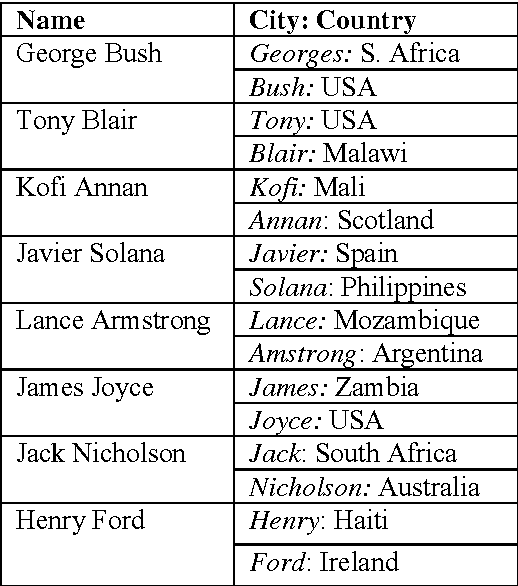
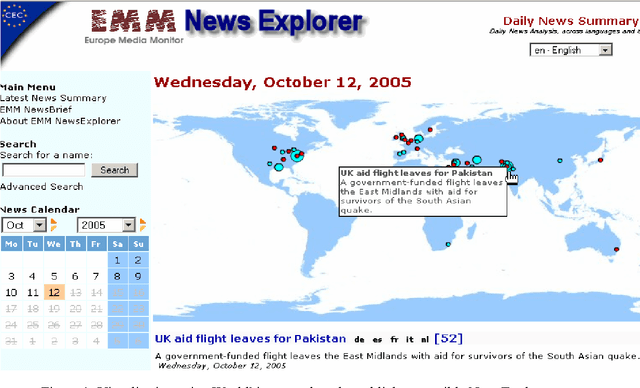
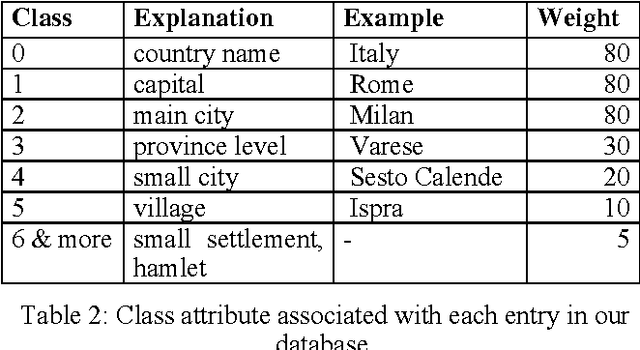
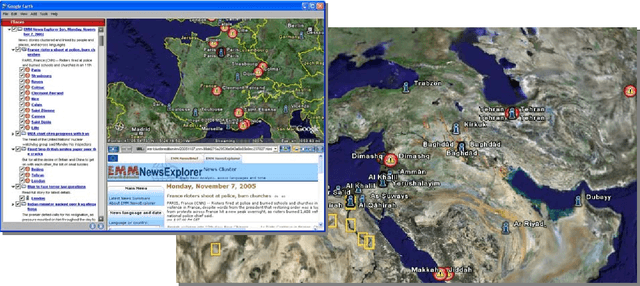
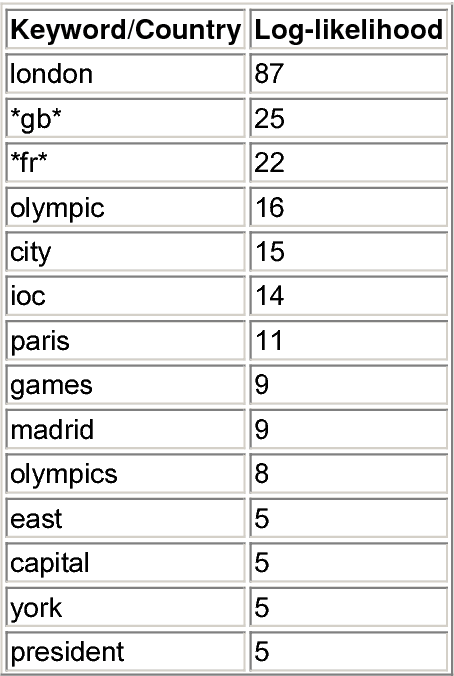
We are presenting a method to recognise geographical references in free text. Our tool must work on various languages with a minimum of language-dependent resources, except a gazetteer. The main difficulty is to disambiguate these place names by distinguishing places from persons and by selecting the most likely place out of a list of homographic place names world-wide. The system uses a number of language-independent clues and heuristics to disambiguate place name homographs. The final aim is to index texts with the countries and cities they mention and to automatically visualise this information on geographical maps using various tools.
* 6 pages
Exploiting multilingual nomenclatures and language-independent text features as an interlingua for cross-lingual text analysis applications
Sep 12, 2006
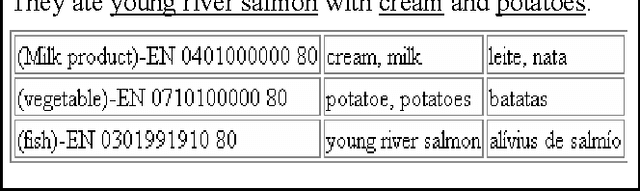
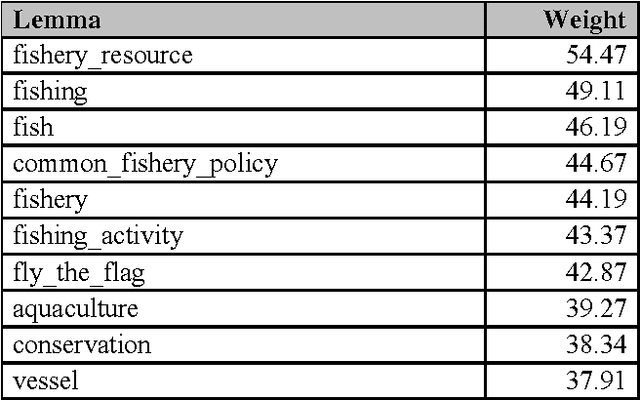

We are proposing a simple, but efficient basic approach for a number of multilingual and cross-lingual language technology applications that are not limited to the usual two or three languages, but that can be applied with relatively little effort to larger sets of languages. The approach consists of using existing multilingual linguistic resources such as thesauri, nomenclatures and gazetteers, as well as exploiting the existence of additional more or less language-independent text items such as dates, currency expressions, numbers, names and cognates. Mapping texts onto the multilingual resources and identifying word token links between texts in different languages are basic ingredients for applications such as cross-lingual document similarity calculation, multilingual clustering and categorisation, cross-lingual document retrieval, and tools to provide cross-lingual information access.
* The approach described in this paper is used to link related documents across languages in the multilingual news analysis system NewsExplorer, which is freely accessible at http://press.jrc.it/NewsExplorer . 11 pages
Extending an Information Extraction tool set to Central and Eastern European languages
Sep 12, 2006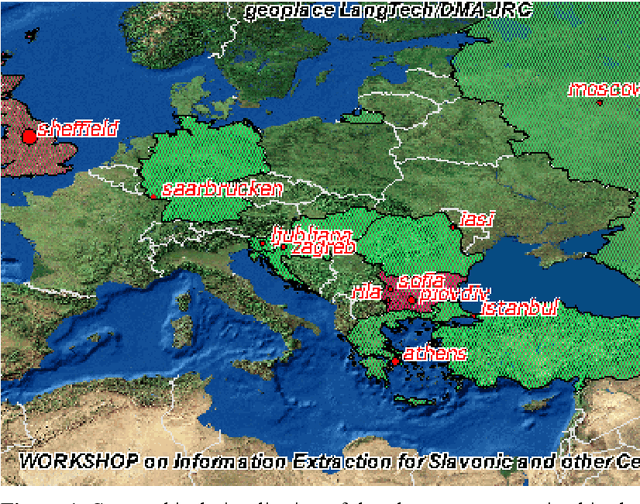
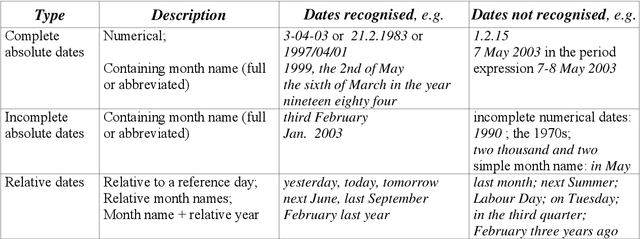
In a highly multilingual and multicultural environment such as in the European Commission with soon over twenty official languages, there is an urgent need for text analysis tools that use minimal linguistic knowledge so that they can be adapted to many languages without much human effort. We are presenting two such Information Extraction tools that have already been adapted to various Western and Eastern European languages: one for the recognition of date expressions in text, and one for the detection of geographical place names and the visualisation of the results in geographical maps. An evaluation of the performance has produced very satisfying results.
* 7 pages
Automatic Identification of Document Translations in Large Multilingual Document Collections
Sep 12, 2006Texts and their translations are a rich linguistic resource that can be used to train and test statistics-based Machine Translation systems and many other applications. In this paper, we present a working system that can identify translations and other very similar documents among a large number of candidates, by representing the document contents with a vector of thesaurus terms from a multilingual thesaurus, and by then measuring the semantic similarity between the vectors. Tests on different text types have shown that the system can detect translations with over 96% precision in a large search space of 820 documents or more. The system was tuned to ignore language-specific similarities and to give similar documents in a second language the same similarity score as equivalent documents in the same language. The application can also be used to detect cross-lingual document plagiarism.
* This technology is used daily to link related news items across languages in the multilingual news analysis system NewsExplorer, which is freely accessible at http://press.jrc.it/NewsExplorer . 8 pages
Automatic annotation of multilingual text collections with a conceptual thesaurus
Sep 12, 2006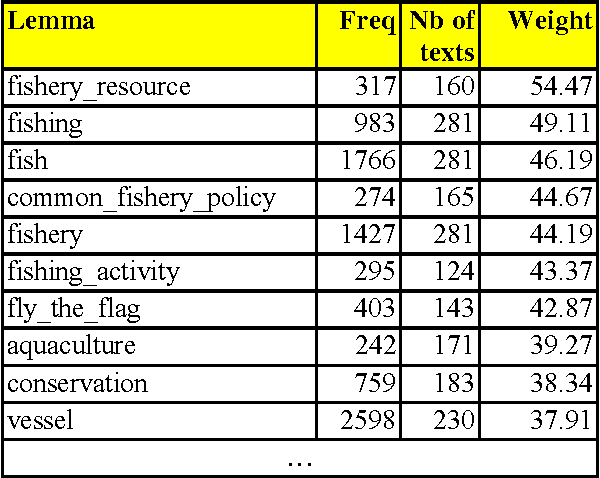
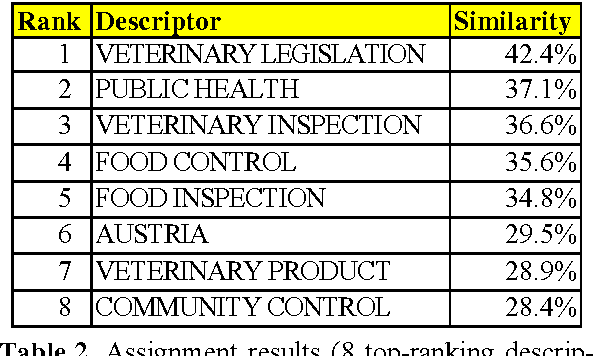
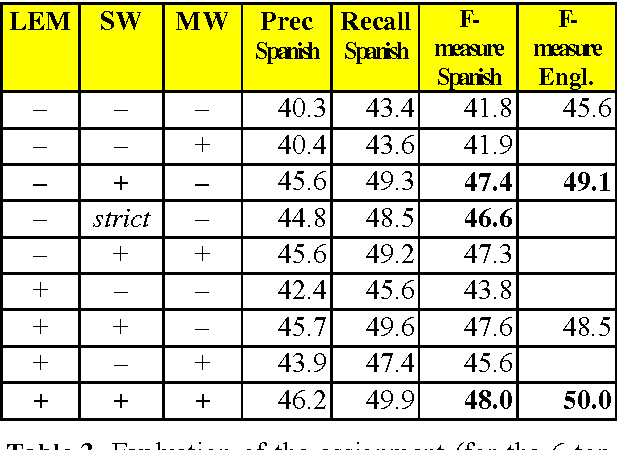
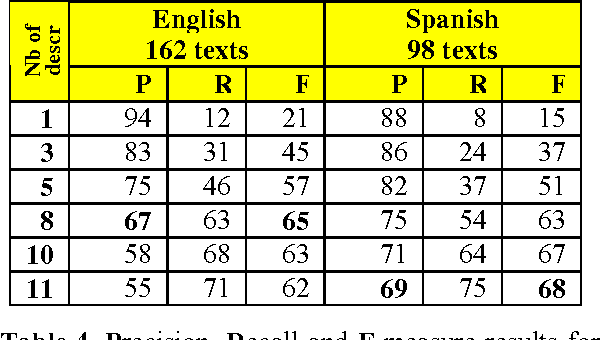
Automatic annotation of documents with controlled vocabulary terms (descriptors) from a conceptual thesaurus is not only useful for document indexing and retrieval. The mapping of texts onto the same thesaurus furthermore allows to establish links between similar documents. This is also a substantial requirement of the Semantic Web. This paper presents an almost language-independent system that maps documents written in different languages onto the same multilingual conceptual thesaurus, EUROVOC. Conceptual thesauri differ from Natural Language Thesauri in that they consist of relatively small controlled lists of words or phrases with a rather abstract meaning. To automatically identify which thesaurus descriptors describe the contents of a document best, we developed a statistical, associative system that is trained on texts that have previously been indexed manually. In addition to describing the large number of empirically optimised parameters of the fully functional application, we present the performance of the software according to a human evaluation by professional indexers.
* 10 pages
The JRC-Acquis: A multilingual aligned parallel corpus with 20+ languages
Sep 12, 2006

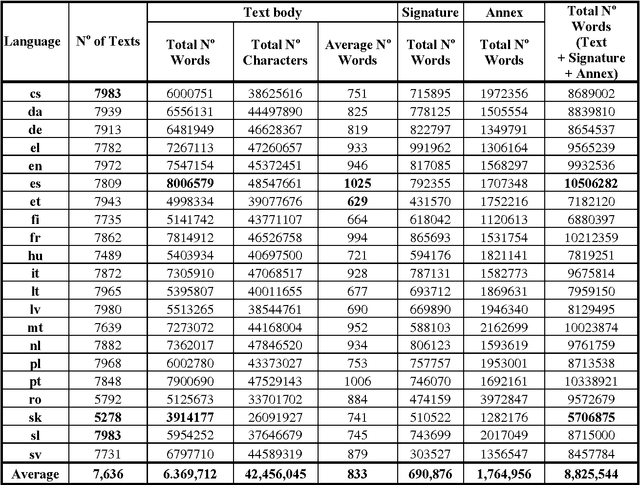

We present a new, unique and freely available parallel corpus containing European Union (EU) documents of mostly legal nature. It is available in all 20 official EUanguages, with additional documents being available in the languages of the EU candidate countries. The corpus consists of almost 8,000 documents per language, with an average size of nearly 9 million words per language. Pair-wise paragraph alignment information produced by two different aligners (Vanilla and HunAlign) is available for all 190+ language pair combinations. Most texts have been manually classified according to the EUROVOC subject domains so that the collection can also be used to train and test multi-label classification algorithms and keyword-assignment software. The corpus is encoded in XML, according to the Text Encoding Initiative Guidelines. Due to the large number of parallel texts in many languages, the JRC-Acquis is particularly suitable to carry out all types of cross-language research, as well as to test and benchmark text analysis software across different languages (for instance for alignment, sentence splitting and term extraction).
* A multilingual textual resource with meta-data freely available for download at http://langtech.jrc.it/JRC-Acquis.html
Navigating multilingual news collections using automatically extracted information
Sep 11, 2006

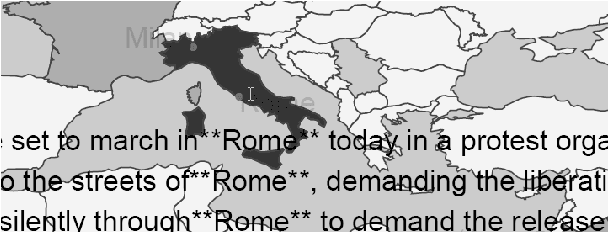
We are presenting a text analysis tool set that allows analysts in various fields to sieve through large collections of multilingual news items quickly and to find information that is of relevance to them. For a given document collection, the tool set automatically clusters the texts into groups of similar articles, extracts names of places, people and organisations, lists the user-defined specialist terms found, links clusters and entities, and generates hyperlinks. Through its daily news analysis operating on thousands of articles per day, the tool also learns relationships between people and other entities. The fully functional prototype system allows users to explore and navigate multilingual document collections across languages and time.
* This paper describes the main functionality of the JRC's fully-automatic news analysis system NewsExplorer, which is freely accessible in currently thirteen languages at http://press.jrc.it/NewsExplorer/ . 8 pages
Multilingual person name recognition and transliteration
Sep 11, 2006
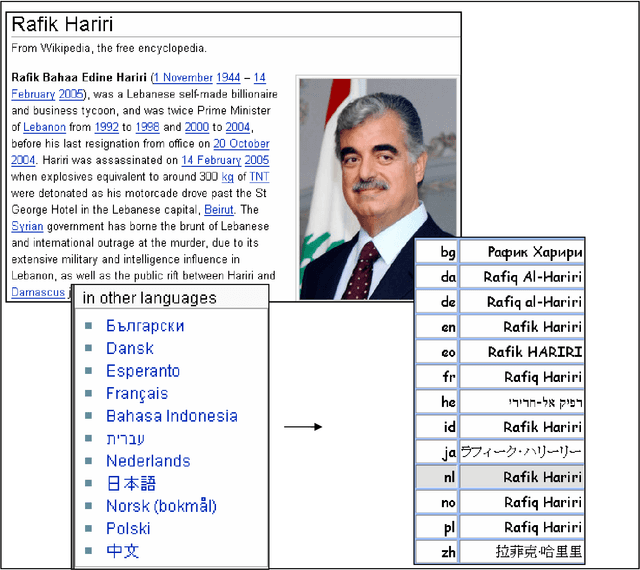
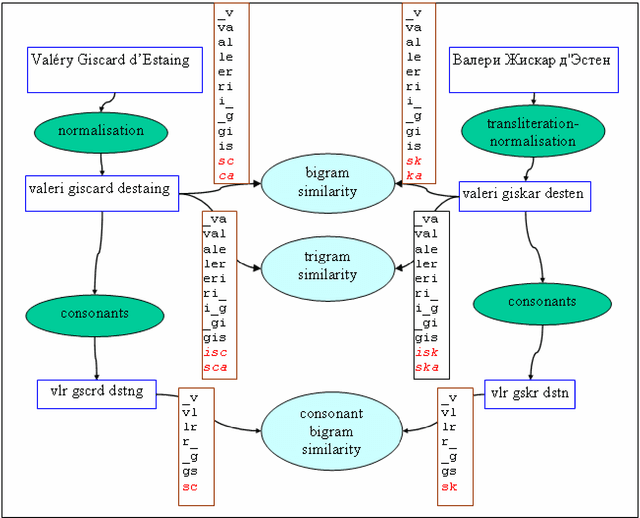
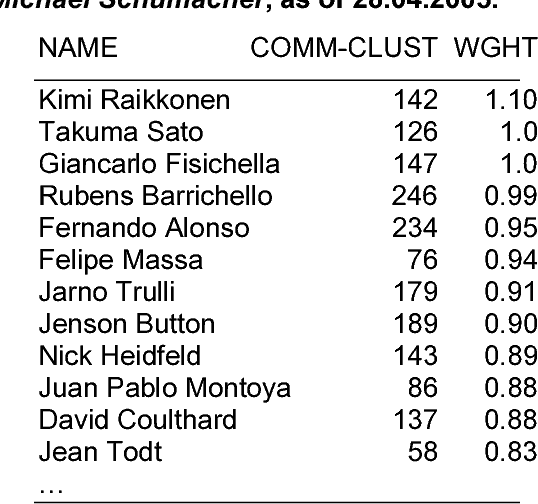
We present an exploratory tool that extracts person names from multilingual news collections, matches name variants referring to the same person, and infers relationships between people based on the co-occurrence of their names in related news. A novel feature is the matching of name variants across languages and writing systems, including names written with the Greek, Cyrillic and Arabic writing system. Due to our highly multilingual setting, we use an internal standard representation for name representation and matching, instead of adopting the traditional bilingual approach to transliteration. This work is part of the news analysis system NewsExplorer that clusters an average of 25,000 news articles per day to detect related news within the same and across different languages.
* Explains the technology behind the JRC's NewsExplorer application, which is freely accessible at http://press.jrc.it/NewsExplorer