 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating multilingual news collections using automatically extracted information
Paper and Code
Sep 11, 2006

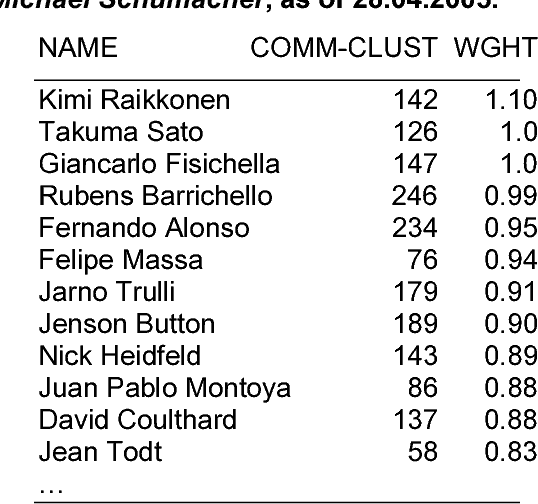
We are presenting a text analysis tool set that allows analysts in various fields to sieve through large collections of multilingual news items quickly and to find information that is of relevance to them. For a given document collection, the tool set automatically clusters the texts into groups of similar articles, extracts names of places, people and organisations, lists the user-defined specialist terms found, links clusters and entities, and generates hyperlinks. Through its daily news analysis operating on thousands of articles per day, the tool also learns relationships between people and other entities. The fully functional prototype system allows users to explore and navigate multilingual document collections across languages and time.