 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping automatic verbatim transcripts for international multilingual meetings: an end-to-end solution
Sep 27, 2023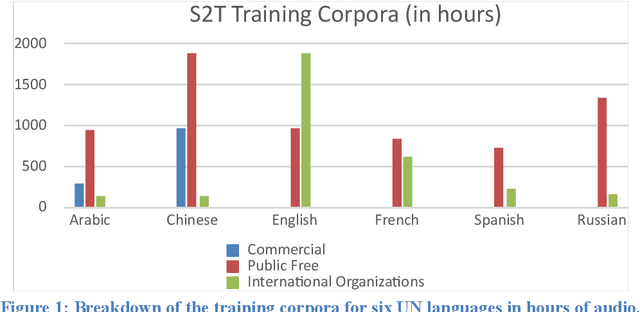

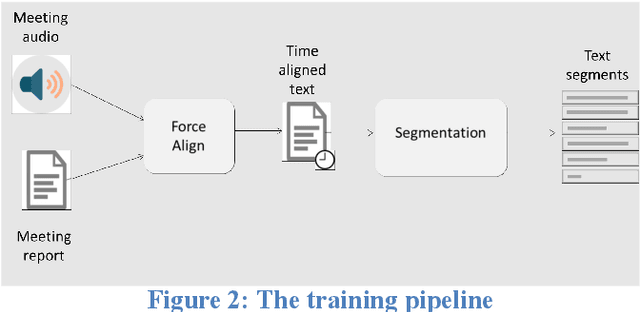
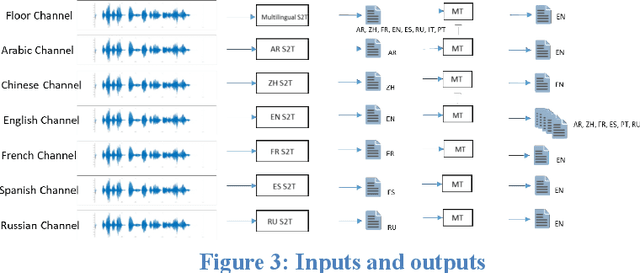
This paper presents an end-to-end solution for the creation of fully automated conference meeting transcripts and their machine translations into various languages. This tool has been developed at the World Intellectual Property Organization (WIPO) using in-house developed speech-to-text (S2T) and machine translation (MT) components. Beyond describing data collection and fine-tuning, resulting in a highly customized and robust system, this paper describes the architecture and evolution of the technical components as well as highlights the business impact and benefits from the user side. We also point out particular challenges in the evolution and adoption of the system and how the new approach created a new product and replaced existing established workflows in conference management documentation.
Sentiment Analysis in the News
Sep 24, 2013
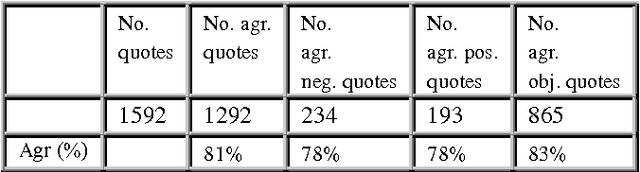
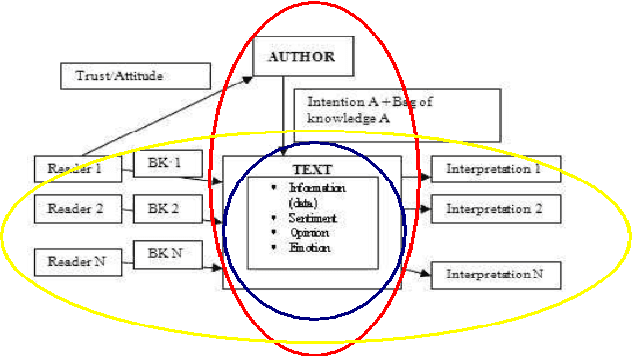
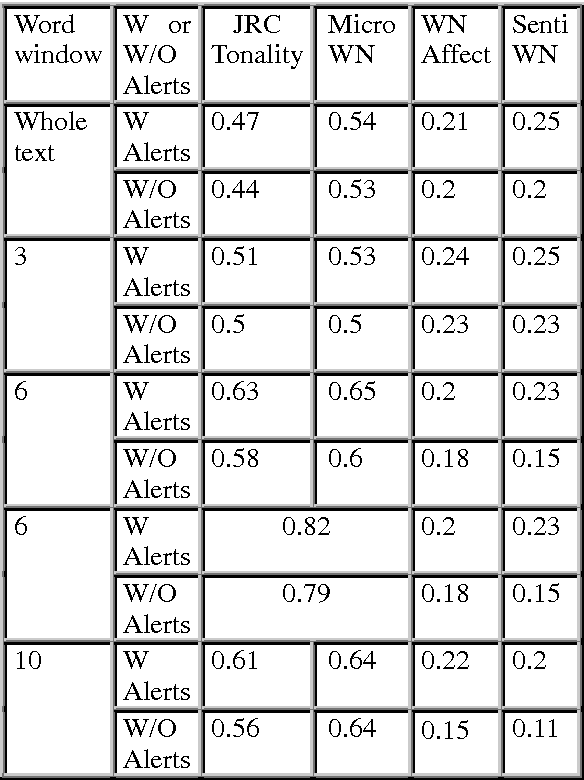
Recent years have brought a significant growth in the volume of research in sentiment analysis, mostly on highly subjective text types (movie or product reviews). The main difference these texts have with news articles is that their target is clearly defined and unique across the text. Following different annotation efforts and the analysis of the issues encountered, we realised that news opinion mining is different from that of other text types. We identified three subtasks that need to be addressed: definition of the target; separation of the good and bad news content from the good and bad sentiment expressed on the target; and analysis of clearly marked opinion that is expressed explicitly, not needing interpretation or the use of world knowledge. Furthermore, we distinguish three different possible views on newspaper articles - author, reader and text, which have to be addressed differently at the time of analysing sentiment. Given these definitions, we present work on mining opinions about entities in English language news, in which (a) we test the relative suitability of various sentiment dictionaries and (b) we attempt to separate positive or negative opinion from good or bad news. In the experiments described here, we tested whether or not subject domain-defining vocabulary should be ignored. Results showed that this idea is more appropriate in the context of news opinion mining and that the approaches taking this into consideration produce a better performance.
JRC-Names: A freely available, highly multilingual named entity resource
Sep 24, 2013
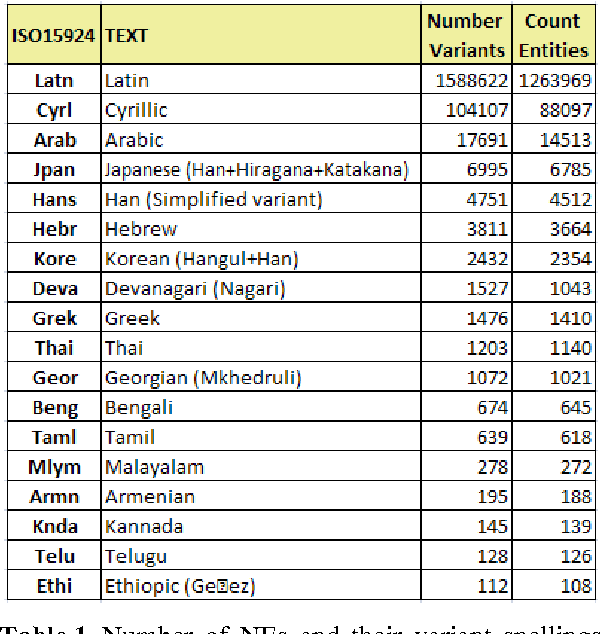

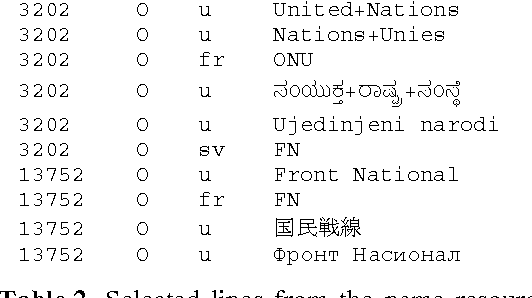
This paper describes a new, freely available, highly multilingual named entity resource for person and organisation names that has been compiled over seven years of large-scale multilingual news analysis combined with Wikipedia mining, resulting in 205,000 per-son and organisation names plus about the same number of spelling variants written in over 20 different scripts and in many more languages. This resource, produced as part of the Europe Media Monitor activity (EMM, http://emm.newsbrief.eu/overview.html), can be used for a number of purposes. These include improving name search in databases or on the internet, seeding machine learning systems to learn named entity recognition rules, improve machine translation results, and more. We describe here how this resource was created; we give statistics on its current size; we address the issue of morphological inflection; and we give details regarding its functionality. Updates to this resource will be made available daily.
An introduction to the Europe Media Monitor family of applications
Sep 20, 2013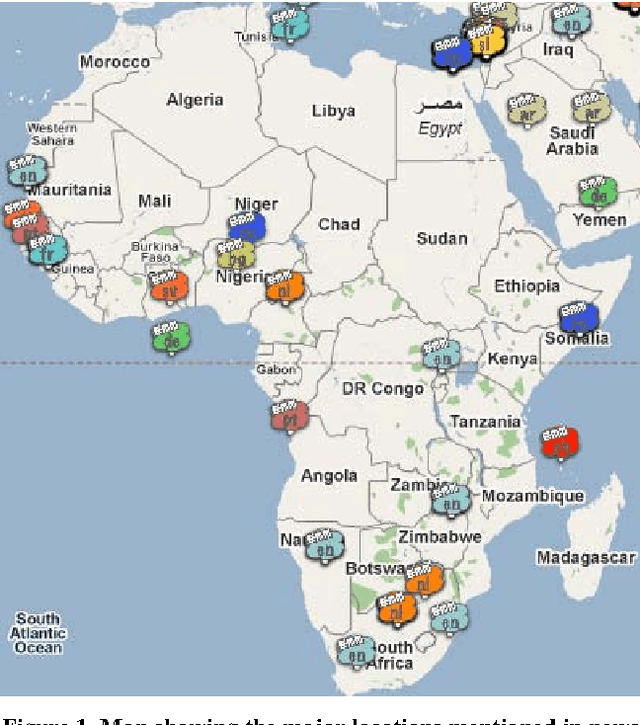
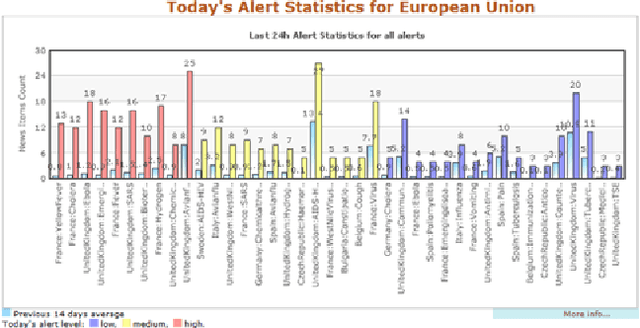

Most large organizations have dedicated departments that monitor the media to keep up-to-date with relevant developments and to keep an eye on how they are represented in the news. Part of this media monitoring work can be automated. In the European Union with its 23 official languages, it is particularly important to cover media reports in many languages in order to capture the complementary news content published in the different countries. It is also important to be able to access the news content across languages and to merge the extracted information. We present here the four publicly accessible systems of the Europe Media Monitor (EMM) family of applications, which cover between 19 and 50 languages (see http://press.jrc.it/overview.html). We give an overview of their functionality and discuss some of the implications of the fact that they cover quite so many languages. We discuss design issues necessary to be able to achieve this high multilinguality, as well as the benefits of this multilinguality.
A tool set for the quick and efficient exploration of large document collections
Sep 12, 2006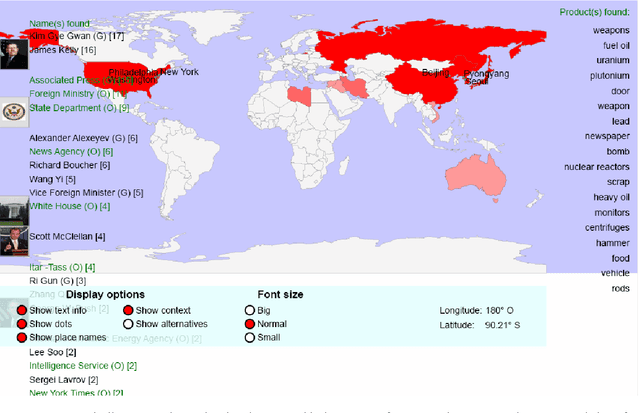



We are presenting a set of multilingual text analysis tools that can help analysts in any field to explore large document collections quickly in order to determine whether the documents contain information of interest, and to find the relevant text passages. The automatic tool, which currently exists as a fully functional prototype, is expected to be particularly useful when users repeatedly have to sieve through large collections of documents such as those downloaded automatically from the internet. The proposed system takes a whole document collection as input. It first carries out some automatic analysis tasks (named entity recognition, geo-coding, clustering, term extraction), annotates the texts with the generated meta-information and stores the meta-information in a database. The system then generates a zoomable and hyperlinked geographic map enhanced with information on entities and terms found. When the system is used on a regular basis, it builds up a historical database that contains information on which names have been mentioned together with which other names or places, and users can query this database to retrieve information extracted in the past.
* 10 pages
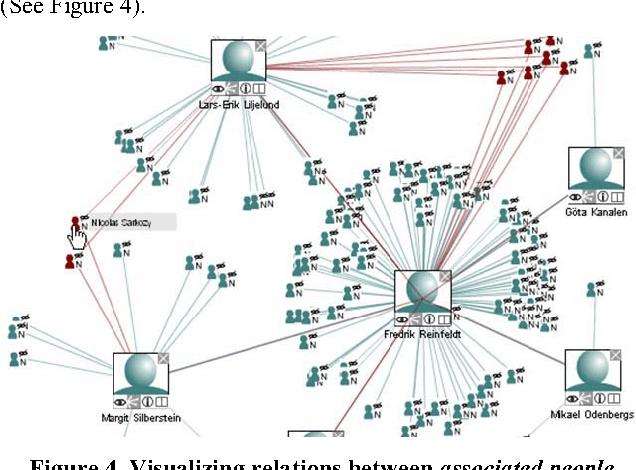
Building and displaying name relations using automatic unsupervised analysis of newspaper articles
Sep 12, 2006
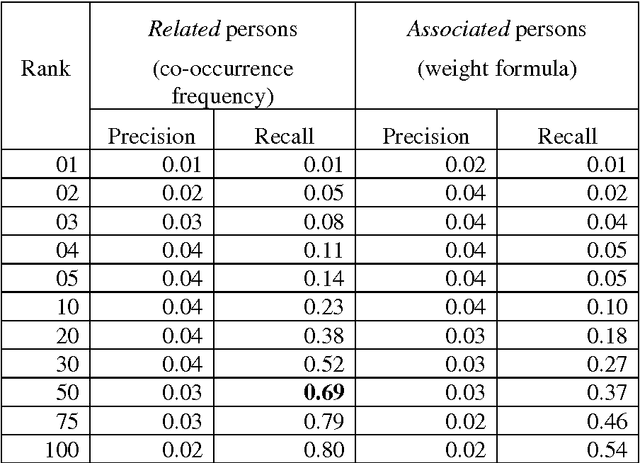

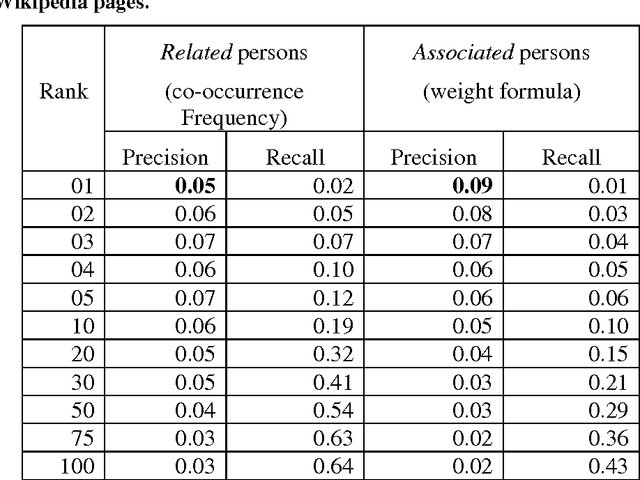
We present a tool that, from automatically recognised names, tries to infer inter-person relations in order to present associated people on maps. Based on an in-house Named Entity Recognition tool, applied on clusters of an average of 15,000 news articles per day, in 15 different languages, we build a knowledge base that allows extracting statistical co-occurrences of persons and visualising them on a per-person page or in various graphs.
* Builds upon the recognition of person names described in paper cs.CL/0609051. Resulting person relations can be explored in the multilingual online application NewsExplorer at http://press.jrc.it/NewsExplorer . 12 pages
Geocoding multilingual texts: Recognition, disambiguation and visualisation
Sep 12, 2006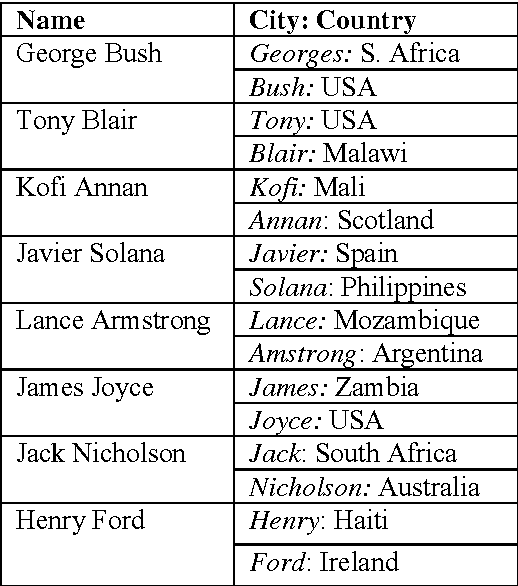
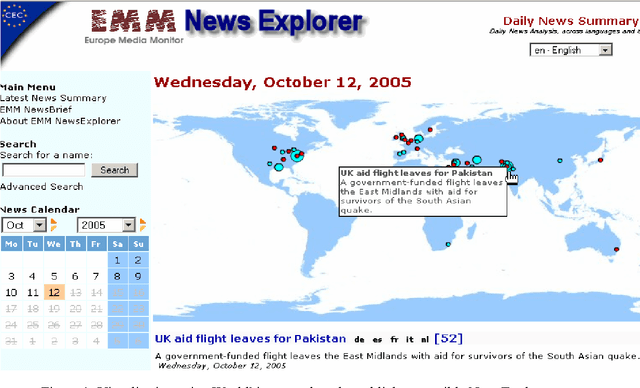
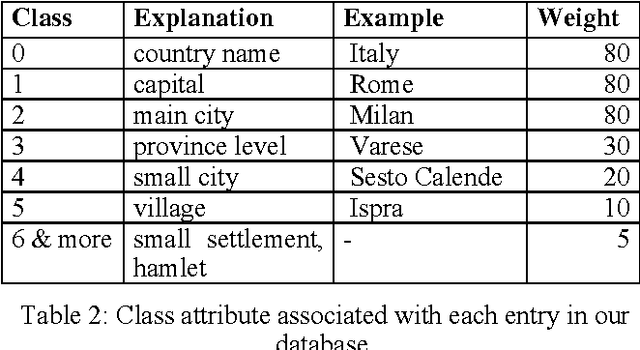
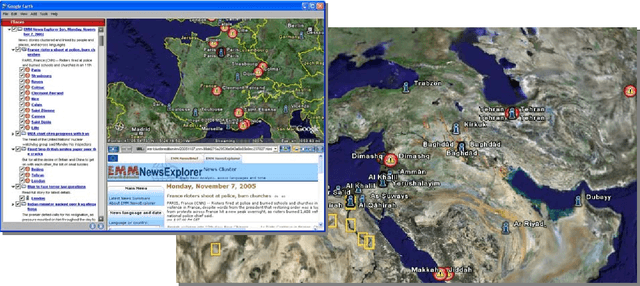
We are presenting a method to recognise geographical references in free text. Our tool must work on various languages with a minimum of language-dependent resources, except a gazetteer. The main difficulty is to disambiguate these place names by distinguishing places from persons and by selecting the most likely place out of a list of homographic place names world-wide. The system uses a number of language-independent clues and heuristics to disambiguate place name homographs. The final aim is to index texts with the countries and cities they mention and to automatically visualise this information on geographical maps using various tools.
* 6 pages
Exploiting multilingual nomenclatures and language-independent text features as an interlingua for cross-lingual text analysis applications
Sep 12, 2006
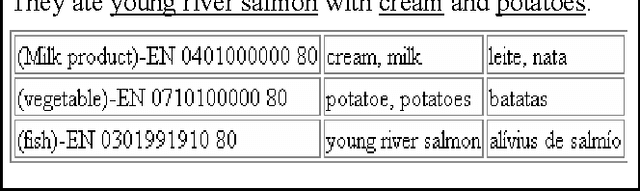
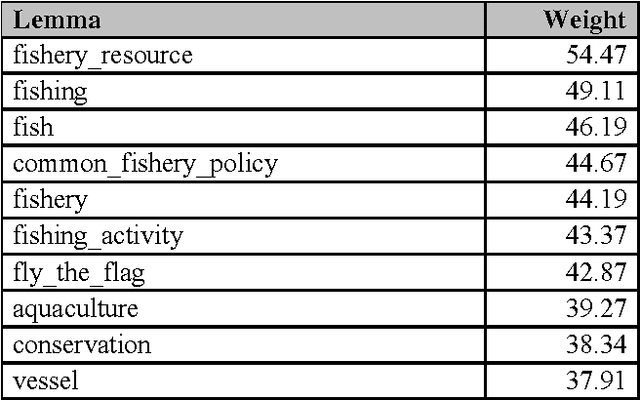

We are proposing a simple, but efficient basic approach for a number of multilingual and cross-lingual language technology applications that are not limited to the usual two or three languages, but that can be applied with relatively little effort to larger sets of languages. The approach consists of using existing multilingual linguistic resources such as thesauri, nomenclatures and gazetteers, as well as exploiting the existence of additional more or less language-independent text items such as dates, currency expressions, numbers, names and cognates. Mapping texts onto the multilingual resources and identifying word token links between texts in different languages are basic ingredients for applications such as cross-lingual document similarity calculation, multilingual clustering and categorisation, cross-lingual document retrieval, and tools to provide cross-lingual information access.
* The approach described in this paper is used to link related documents across languages in the multilingual news analysis system NewsExplorer, which is freely accessible at http://press.jrc.it/NewsExplorer . 11 pages
Extending an Information Extraction tool set to Central and Eastern European languages
Sep 12, 2006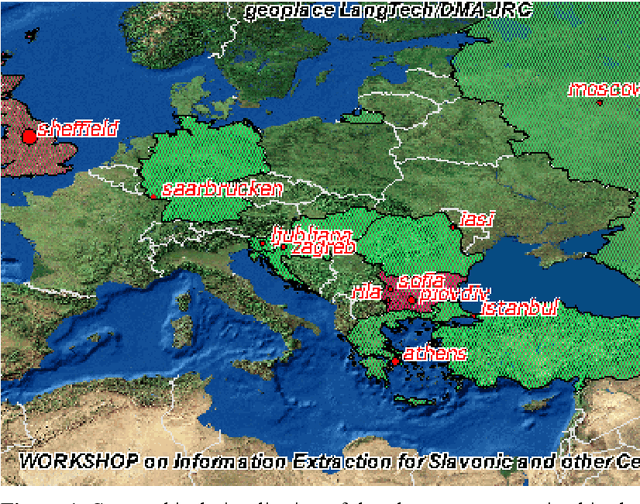
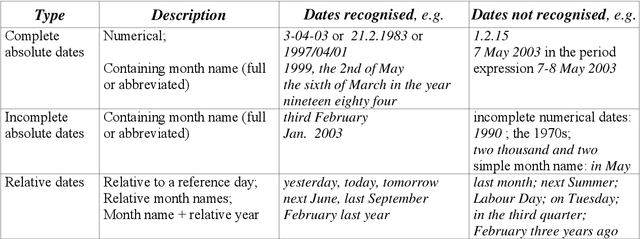
In a highly multilingual and multicultural environment such as in the European Commission with soon over twenty official languages, there is an urgent need for text analysis tools that use minimal linguistic knowledge so that they can be adapted to many languages without much human effort. We are presenting two such Information Extraction tools that have already been adapted to various Western and Eastern European languages: one for the recognition of date expressions in text, and one for the detection of geographical place names and the visualisation of the results in geographical maps. An evaluation of the performance has produced very satisfying results.
* 7 pages
Automatic Identification of Document Translations in Large Multilingual Document Collections
Sep 12, 2006Texts and their translations are a rich linguistic resource that can be used to train and test statistics-based Machine Translation systems and many other applications. In this paper, we present a working system that can identify translations and other very similar documents among a large number of candidates, by representing the document contents with a vector of thesaurus terms from a multilingual thesaurus, and by then measuring the semantic similarity between the vectors. Tests on different text types have shown that the system can detect translations with over 96% precision in a large search space of 820 documents or more. The system was tuned to ignore language-specific similarities and to give similar documents in a second language the same similarity score as equivalent documents in the same language. The application can also be used to detect cross-lingual document plagiarism.
* This technology is used daily to link related news items across languages in the multilingual news analysis system NewsExplorer, which is freely accessible at http://press.jrc.it/NewsExplorer . 8 pages